编译原理与技术(第四章)语法分析
2015-11-27 21:11
302 查看
FIRST集合
构造算法:
对于G中的每一个文法符号X∈VN∪VT,反复应用下列规则求FIRST(X),到所求的FIRST集不再增大为止。(1)若X∈VT,则FIRST(X)={X}。
(2)若X∈VN,且有X→aα∈P(a∈VT),则令a∈FIRST(X);若有X→ε∈P,则令ε∈FIRST(X)。
终结符,直接推导
(3)若X→Y1Y2…Yk∈P,且Y1∈VN,则令FIRST(Y1)-{ε}

FIRST(X)
非终结符
(4)若X→Y1Y2…Yk∈P,对所有的j(1≤j≤i−1),Yj∈VN,且Yj→ε(∗),则令FIRST(Yj)-{ε}
FIRST(X) (1≤j≤i)
连续的非终结符
(5) (3)(4)中特别当ε∈FIRST(Yj) (1≤j≤k)时,令ε∈FIRST(X)。
解释:
FIRST集合表示的是,由非终结符号能够推导出的所有句子的第一个终结符号。那么如果A→aB,就直接可以得到结果。
如果是A→BD,我们要继续看B的推导情况,因为A推出的句子首位肯定是B的位置,所以我们必须看B的FIRST集合。
如果B能够推出ε,则A推出的句子可以以D推出的句子开头,那么继而考虑D的情况。
如果A→BCD,BCD都可以推出ε,则A也可以推出ε。
FOLLOW集合
构造:
对于G中的每一A∈VN,为构造FOLLOW(A),可反复使用如下的规则,直到每一个FOLLOW集不再增大为止。(1)对于文法的开始符号S,令∈FOLLOW(S)。(2)对于每一个A\rightarrow αBβ∈P$,令FIRST(β) -{ε}
FOLLOW(B).
(3)对于每一个A→αB∈P或A→αBβ∈P,且ε∈FIRST(β),则令FOLLOW(A)
FOLLOW(B)。
解释:
FOLLOW集合表示的是,由非终结符号能够推导出的所有句子之后(不包含在推导出的句子内)的第一个终结符号。那么如果A→Bβ,则B推导出的句子后面一定可能跟着β,这β就属于FOLLOW(B)。
如果是A→BC,那么我们想B推导出的句子后面一定可能跟着C的句子,那么C推导出的句子的第一个终结符号(恰好是FIRST(C)里的元素)就属于FOLLOW(B)。
如果有C→ε,也就是ε∈FIRST(C),则我们可以想到在这个产生中下所有的A推导出的句子中的最后部分(包含在A推导出的句子里)是由B推导出的句子构成,那么A推出的句子后面跟着的终结符必定也跟着B,所以有FOLLOW(A)∈FOLLOW(B)。
LL(1)分析法
定义:
一个文法G是LL(1)的, 当且仅当对于G的每一个非终结符A的任何两个不同产生式 A→α|β,下面的条件成立:
① FIRST(α)∩FIRST(β)= ∅
也就是α和β推导不出以某个相同的终结符a为首的符号串;它们不应该都能推出空字ε.
② 假若β→ε那么,FIRST(α)∩ FOLLOW(A)=∅
也就是,若β→ε则α所能推出的串的首符号不应在FOLLOW(A)中。
构造:
for(文法G的每个产生式A→α){for(每个终结符号a∈FIRST(α))
把A→α加入到分析表M[A,a]中
if(ϵ∈FIRST(a))
for(任何b∈FOLLOW(A))
把A→α加入到分析表M[A,b]中
}
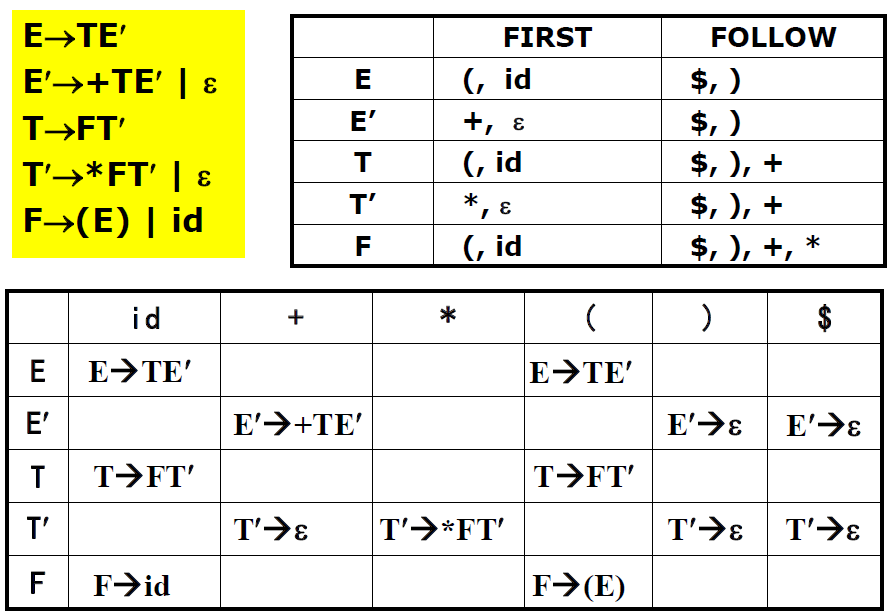
解释:
LL(1)分析法只往前看一位,算法也相对简单。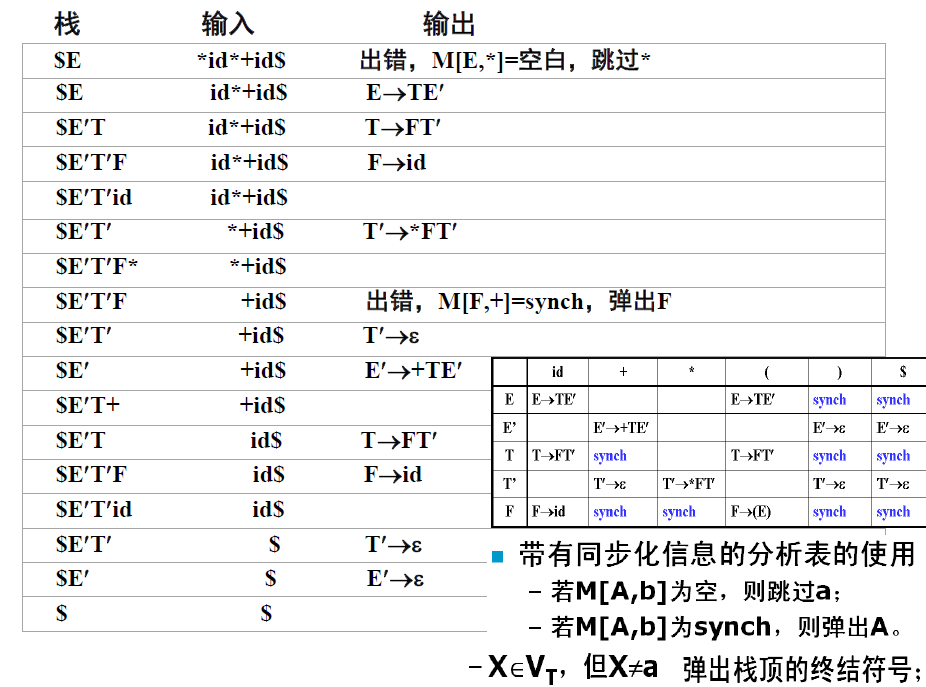
分析过程注意一下栈的变化,当进行产生式推导的时候,将产生式倒序压入栈。
闭包
构造:
对于拓广文法G,设I是文法G的一个LR(0)项目集合,closure(I)是从I出发,用下面的方法构造出的项目集合:(1)I中的每一个项目(即,I的所有产生式)都属于closure(I);
(2)若项目A→α⋅Bβ属于closure(I),则将文法G中B的所有产生式,B→⋅η加入到closure(I)内,重复的不算。
(3)直到集合不再扩大。
解释:
⋅符号之后的非终结符产生式全部加入到闭包内,⋅符号位置不同则表示产生式也不同。这种东西,如果没有要求,直接画DFA会比较好理解。

SLR(1)分析表
构造:
假设已构造出LR(0)项目集规范族为:C={I0,I1,…,In},其中Ik为项目集的名字,k为状态名,令包含S'→⋅S项目的集合Ik的下标k为分析器的初始状态。那么分析表的ACTION表和GOTO表构造步骤为:
① 若项目A→α·aβ属于Ik且转换函数GO(Ik,a)=Ij(其中go函数可以理解为DFA中对应状态和对应边),当a为终结符时则置ACTION[k,a]为Sj,表示移进。
② 若项目A→α· 属于Ik,则对任何终结符a∈FOLLOW(A)和号置ACTION[k,a]为rj,j为在文法G′中某产生式A→α的序号,表示根据此产生式进行归约。
③ 若GO(Ik,A)=Ij,则置GOTO[k,A]为j,其中A为非终结符,表示状态之间的转移。
④ 若项目S′→S·属于Ik,则置ACTION[k,#]为”acc”,表示接受。
⑤ 凡不能用上述方法填入的分析表的元素,均应填上”报错标志”。为了表的清晰我们仅用空白表示错误标志。
解释:

上图是SLR(1)分析表的样式。
注意几点:
1、只有当⋅在产生式的最后时(表示产生式完全读取)才可以进行归约。
2、归约的时候,是所有符合条件的action都可以进行归约,如SLR(1)在所有a∈FOLLOW(A)的下面都能进行归约。
3、在用分析表进行分析的时候,进行完归约操作,先将栈顶的句柄全部弹出,然后根据栈顶的状态数与归约完的非终结符进行转移(将归约完的非终结符当做输入串),从而得出新的栈顶状态数。
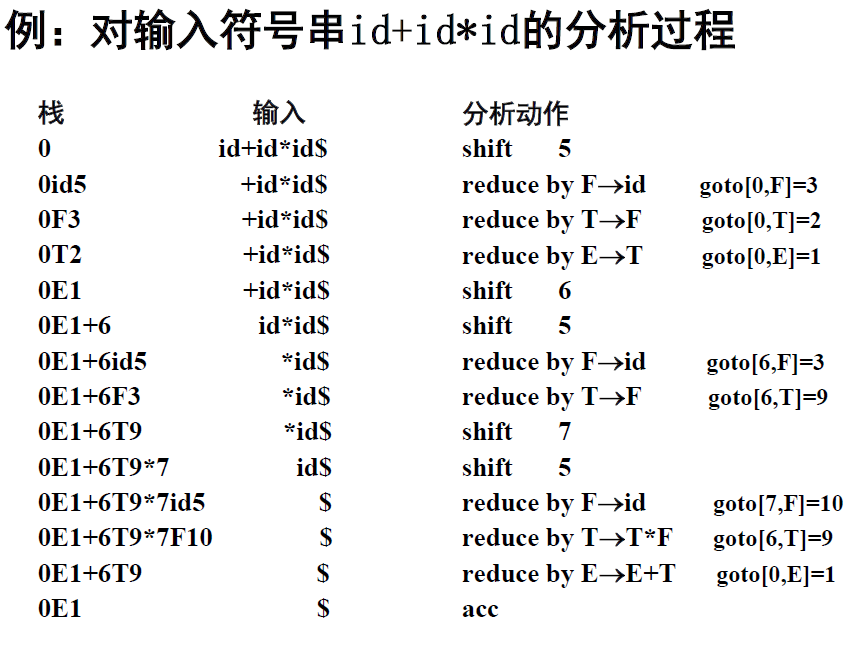
每次入栈的是输入符号(或者是归约之后的非终结符)+现在所在的状态(DFA中的状态节点)。
LR(1)
构造:
我在网络上找到了一个非常详细的构造过程,如下:现有文法如下,试构造其LR(1)分析表:
A→A+B
A→a
B→b
要构造 LR 表,我们需要先求出拓广文法:
加入S→A
现在就可以逐步构造 DFA 了。
第一个状态由 S→A 生成。而我们知道,一个 LR(1) 项看起来长这样:[A→α⋅β,t]。其中 t是一个终止符(所谓的 lookahead),而黑点则标志着我们现在的位置(已经看见了 α,正在找β)。
对后面的每一个状态,只要依次考虑以下几点:
它从哪里来?
它的闭包是什么?
它需要归约吗?
它需要转移吗?
就能得到正确的结果。这样看起来还是有些抽象,希望下面的演示能帮助理解吧。
State 0
我们从 [S→⋅A,$] 开始,构造这个状态的闭包,也就是加上所有能从这个产生式推出的表项。首先,我们寻找非终止符前是否有个 ⋅。嗯对了,这个 ⋅ 在A 前面。所以我们就要接着找所有由 A→推出的产生式,并将它们添加进闭包里(这个地方的推导和LR(0)分析表的构造思路一样)。这加上了 [A→⋅A+B,$]和[A→⋅a,$]。
这样够了吗,闭包还可以扩展吗?我们导入了另一个在非终止符前有⋅ 的项。所以下面我们需要再求一次闭包。
这次加入的产生式包括[A→⋅A+B,+]和[A→⋅a,+]。这里的终止符+,是来自于⋅A +B,也就是⋅后面一个元素之后的产生式的FIRST集合。
这次,产生式形如⋅A+,理论上我们也要用另一个项来表达它所引入的产生式,不过实际上这个项就是 [A→⋅A+B,+],所以不用导入新的项了,集合里面的元素是不能重复的。
现在S0 包含的项有:
[S→⋅A,$]
[A→⋅A+B,$]
[A→⋅a,$]
[A→⋅A+B,+]
[A→⋅a,+]
下一步,就是为这个状态添加转移了。对每个符号 X 后有个⋅的项,都可以从 State 0 过渡到其它状态。看一下这五个,满足条件的是⋅A和 ⋅a 吧?把前者转移的状态定义为 State 1,后者定义为 State 2 吧。
State 1
先要看看 State 1 中出现了哪些项吧。我们从 State 0 通过 A 转移到这里,所以我们找出所有 State 0 中在 A 前有⋅的项,这包括:[S→⋅A,$]
[A→⋅A+B,$]
[A→⋅A+B,+]
因此,将⋅向后推一格(⋅前面的表示已经读取过的),就得到了 State 1 的项了:
[S→A⋅,$]
[A→A⋅+B,$]
[A→A⋅+B,+]
现在再来求闭包,由于没有在非终止符前有⋅的项了,所以这就是全部了(耶!)
最后,从 State 1 出发,可以去哪里呢?由于在这个状态的 [S→A⋅,$]项中,⋅已经移动到了产生式尾部,因此我们需要应用S→A规则来进行归约。除此之外,对每个前面有⋅的状态,都有对应转移出去的状态。这里满足要求的就是[A→A⋅+B,+]这个了。这里我们约定+对应转移到 State 3。
State 2
我们是从哪里过来的呢?State 0 中的a。所以我们从所有 State 0 项中a前带有⋅的开始吧。State 0 的项:
[A→⋅a,$]
[A→⋅a,+]
将⋅后移得到:
[A→a⋅,$]
[A→a⋅,+]
再看看有没有在非终止符前有⋅的项吧。嗯好,没有了,这下不用再求闭包了。下面就是归约了。约定从+ 或 $,归约A→a。现在没有前面具有⋅的其它符号,因此也不需要再继续了。
State 3
如果我们在 State 1 中遇到+,那么就会转移到这个 State 3 上来。我们先找出所有符合要求的 State 1 项吧。State 1 的项:
[A→A⋅+B,$]
[A→A⋅+B,+]
把 · 后推得到:
[A→A+⋅B,$]
[A→A+⋅B,+]
好的,看到了非终结符前的 · 了吗?我们得求闭包了。先从 [A→A+⋅B, ] 开始,找出所有B → xxx 的产生式(注意lookahead是 $)。这会加入[B → ·b, $]。再对 [A → A + ·B, +] 做同样的操作,加入 [B → ·b, +]。现在由于没有前面有 · 的非终结符,因此闭包就完成了。闭包构造完成后,State3的项有这些:[A → A + ·B, $][A → A + ·B, +][B → ·b, $][B → ·b, +]最后看看从State3能去哪里吧。没有以 · 结束的产生式,也就是不需要归约了。不过 B 和 b 前都有 ·,这也就意味着有两个转移状态。约定 B 转移到State4,b$ 转移到 State 5。
State 4
我们在 State 3 中遇上B时来到这里。列出 State 3 中对应的项:[A→A+⋅B,$]
[A→A+⋅B,+]
那么对应的 State 4 项就是:
[A→A+B⋅,$]
[A→A+B⋅,+]
嗯,⋅前没有非终结符了,这么说也就不用再求闭包了。不过,别忘了归约啊。可以看到我们需要应用的归约规则就只有A→A+B这一条。由于⋅前没有非终结符,所以这个状态不需要转移。
State 5
我们在 State 3 中遇上b时来到这里。列出 State 3 中对应的项:[B→⋅b,$]
[B→⋅b,+]
于是得到对应的 State 5 项:
[B→b⋅,$]
[B→b⋅,+]
嗯,这个状态需要归约吗?需要。应用B→b规则即可。最后,它有对应的转移状态吗?· 前没有非终结符,所以也不需要转移。
好了。现在该生成的状态都生成了,DFA 就构造完成了。根据我们的结果,填一下最后的 LR 转移表。
结果:
sN 代表移入,实际上就是移入新符号并进入状态N。rN代表归约。这里把N与产生式的关系约定如下:
S→A
A→A+B
A→a
B→b
goto N 代表转移,也就是转移到状态 N。
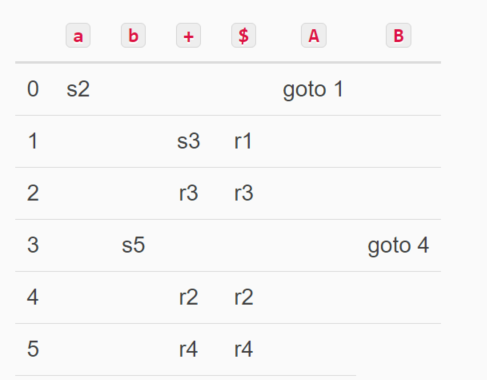
这就是LR(1)分析表。
LR(1)的分析过程和LR(0)的分析过程是一样的,就不重复累赘了。
LALR(1)
LALR(1)分析表的基本思想是合并LR(1)项目集规范族中的同心集,以减少分析表的状态数,即,用核代替项目集,以减少项目集所需的存储空间。因为转移函数GO(I,X)仅仅依赖于状态I的心,因此LR(1)项目集合并后的转移函数可以通过Go(I,X)自身的合并得到。
注意:
同心集的合并,可能导致归约-归约的冲突,但不会产生新的移进-归约冲突。
同心集:
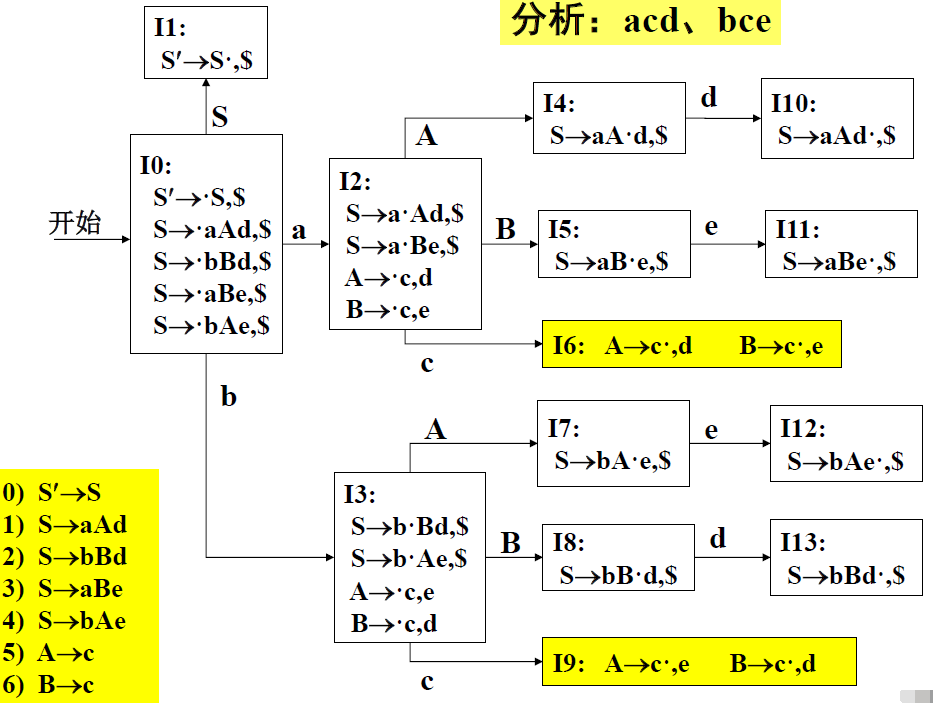
高亮的那两个状态,即I6和I9,去掉终止符之后,他们的核是相同的,因此称他们为同心集。
构造:
求出同心集然后合并即可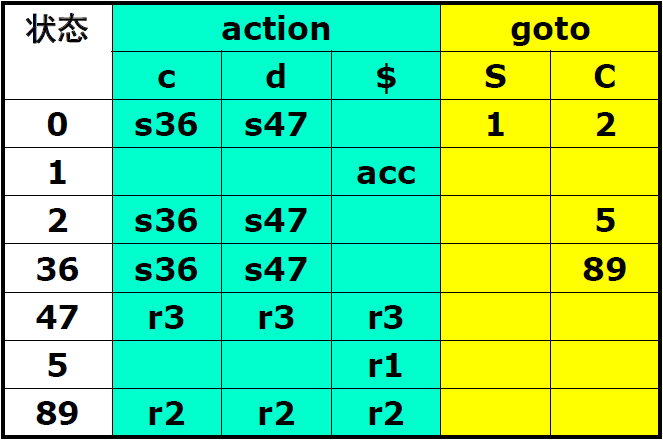
这里将I3、I6和I4、I7和I8、I9进行了合并,其余构造方法和LR(1)文法相同。
解释:
参照LR(1)分析程序,就可以类似地写出LALR(1)分析程序的分析过程。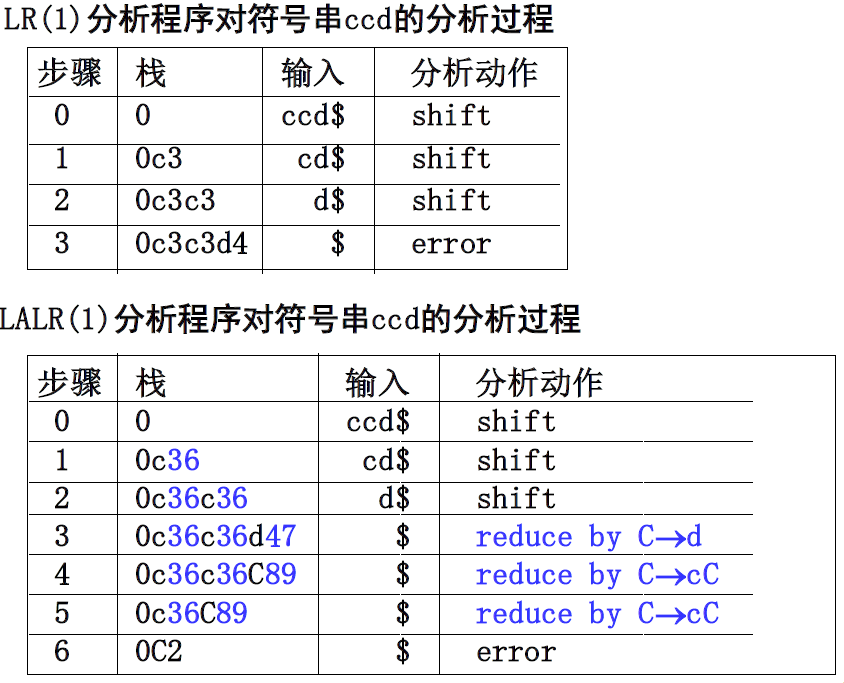
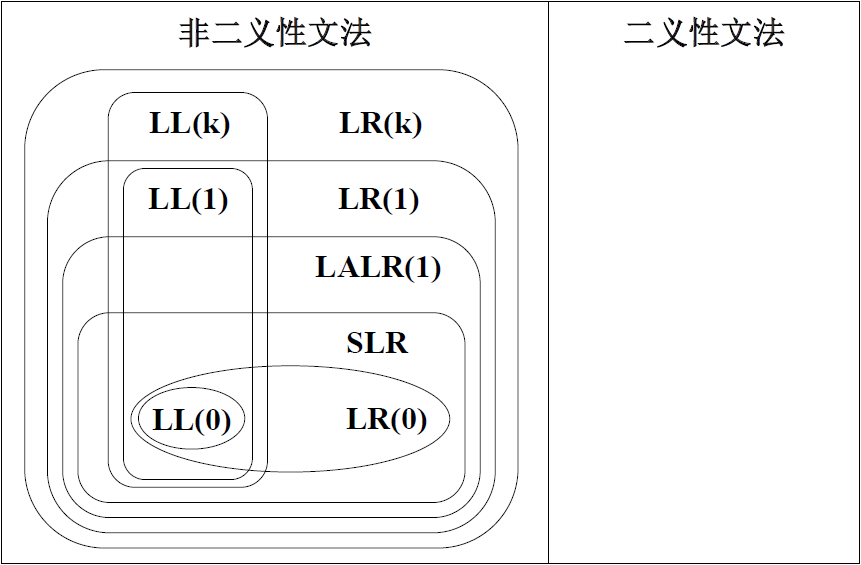
文法分类

相关文章推荐
- 实现一个简单的计算器
- NOP(N) NOP_##N
- 编译器是如何工作的?(转)
- 写给想学java的朋友!
- 学java的必看!
- java中的加密!
- java中的使用类!
- LEX/FLEX词法分析器
- 如何模仿人的学习模式来教计算机程序解数学题?
- 上下文无关文法1
- 上下文无关文法2
- 编译原理——词法分析器
- 编译原理预习笔记------名词理解
- Simple scanner of c
- 编译原理:短语、直接短语、句柄、素短语
- 编译原理中FIRST集合与FOLLOW集合的算法
- 上下文无关文法解析
- 识别浮点常量问题-编译原理程序实现
- 计算的哲学(philosophy in coding)
- 哈工大软件学院2012秋编译原理部分回顾