matlab图像处理为什么要归一化和如何归一化
2015-11-25 09:51
218 查看
本文引用地址:http://blog.sciencenet.cn/blog-444691-322182.html 此文来自科学网张建国博客
http://www.cnblogs.com/LBSer/p/4440590.html
matlab图像处理为什么要归一化和如何归一化
一、为什么归一化
1.
基本上归一化思想是利用图像的不变矩寻找一组参数使其能够消除其他变换函数对图像变换的影响。也就是转换成唯一的标准形式以抵抗仿射变换
图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的。
因为我们这次的图片有好多都是一个系列的,所以老师把这个也作为我研究的一个方向。
我们主要要通过归一化减小医学图片由于光线不均匀造成的干扰。
2.matlab里图像数据有时候必须是浮点型才能处理,而图像数据本身是0-255的UNIT型数据所以需要归一化,转换到0-1之间。
3.归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 目的是为了:
(1).避免具有不同物理意义和量纲的输入变量不能平等使用
(2).bp中常采用sigmoid函数作为转移函数,归一化能够防止净输入绝对值过大引起的神经元输出饱和现象
(3).保证输出数据中数值小的不被吞食
3.神经网络中归一化的原因
归一化是为了加快训练网络的收敛性,可以不进行归一化处理
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布; 当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。
但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。
二、如何归一化
matlab中的归一化处理有三种方法
1. premnmx、postmnmx、tramnmx
2. restd、poststd、trastd
3. 自己编程
(1)线性函数转换,表达式如下:
y=(x-MinValue)/(MaxValue-MinValue)
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
(2)对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
(3)反余切函数转换,表达式如下:
y=atan(x)*2/PI
(4)一个归一化代码.
I=double(I);
maxvalue=max(max(I)');%max在把矩阵每列的最大值找到,并组成一个单行的数组,转置一下就会行转换为列,再max就求一个最大的值,如果不转置,只能求出每列的最大值。
f = 1 - I/maxvalue; %为什么要用1去减?
Image1=f;
[b]机器学习模型需要对数据进行归一化[/b]
1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。

一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
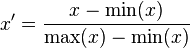
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
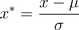
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
http://www.cnblogs.com/LBSer/p/4440590.html
matlab图像处理为什么要归一化和如何归一化
一、为什么归一化
1.
基本上归一化思想是利用图像的不变矩寻找一组参数使其能够消除其他变换函数对图像变换的影响。也就是转换成唯一的标准形式以抵抗仿射变换
图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的。
因为我们这次的图片有好多都是一个系列的,所以老师把这个也作为我研究的一个方向。
我们主要要通过归一化减小医学图片由于光线不均匀造成的干扰。
2.matlab里图像数据有时候必须是浮点型才能处理,而图像数据本身是0-255的UNIT型数据所以需要归一化,转换到0-1之间。
3.归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 目的是为了:
(1).避免具有不同物理意义和量纲的输入变量不能平等使用
(2).bp中常采用sigmoid函数作为转移函数,归一化能够防止净输入绝对值过大引起的神经元输出饱和现象
(3).保证输出数据中数值小的不被吞食
3.神经网络中归一化的原因
归一化是为了加快训练网络的收敛性,可以不进行归一化处理
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布; 当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。
但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。
二、如何归一化
matlab中的归一化处理有三种方法
1. premnmx、postmnmx、tramnmx
2. restd、poststd、trastd
3. 自己编程
(1)线性函数转换,表达式如下:
y=(x-MinValue)/(MaxValue-MinValue)
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
(2)对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
(3)反余切函数转换,表达式如下:
y=atan(x)*2/PI
(4)一个归一化代码.
I=double(I);
maxvalue=max(max(I)');%max在把矩阵每列的最大值找到,并组成一个单行的数组,转置一下就会行转换为列,再max就求一个最大的值,如果不转置,只能求出每列的最大值。
f = 1 - I/maxvalue; %为什么要用1去减?
Image1=f;
[b]机器学习模型需要对数据进行归一化[/b]
1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度
1 归一化为什么能提高梯度下降法求解最优解的速度?
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2 归一化有可能提高精度
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
3 归一化的类型
1)线性归一化
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
2)标准差标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
3)非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。

相关文章推荐
- Windows下使用MATLAB的MCC命令生成C/C++程序
- Matlab和C程序的备忘2
- 精神污染图制作(matlab代码)
- matlab 破解教程密钥
- Matlab 实现矩阵的满秩分解(最大秩分解)
- 每天一点matlab——图像二值化,人为设定阈值
- matlab批处理读取图像文件和批写图像文件
- 常见MATLAB小技巧
- 绘制y=sin(x)/x的图形
- 用MATLAB进行SVM分类
- matlab quadprog函数 二次规划的matlab解法
- matlab load
- matlab save 命令
- libsvm之(一)安装与测试(matlab)
- Matlab调用C的时候的一个小备注
- 支撑向量机 SVM 学习笔记(Matlab代码)
- MATLAB中squeeze函数的作用
- Python 读写matlab中.mat文件
- 将sin()与cos()显示在同一个网格里
- Matlab里面.M文件不能运行,预期的图像也显示不出来的一个原因