MySQL编程。sql语句。
2015-11-23 18:09
676 查看
第1部分 MySQL基础篇
1、对于企业而言,选择MySQL数据库的两大原因:1)MySQL是开源关系型数据库产品,使用普及率高;2)性能出色,运行速度块。MySQL有免费和收费两种类型的产品。
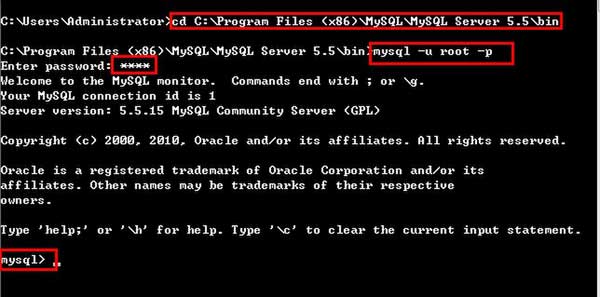
2、mysql登录:cd 打开mysql的bin目录,执行“mysql -u root -p”回车,然后要求输入密码Enter password,正确输入密码后,回车,即可登录成功!
3、常用数据库查询命令:
show databases; 查看数据库服务器上的全部数据库
create database test; 创建一个名称为test的数据库
use test;使用test数据库
show tables;查看当前数据库中所有表
创建表:
create table 表名(
属性名数据类型列选项,
……
)
其中,列选项可以为AUTO_INCREMENT(自增),DEFAULT '默认值',INDEX(定义为索引),[NOT]NULL(允许/禁止NULL),PRIMARY KEY(定义为主键),UNIQUE(定义为唯一性),CHECK(定义可以输入的值的范围/选项)。
alter table 表名 modify 列名 数据类型;修改表中列的定义
alter table 表名 add 列名 数据类型;追加新列
alter table 表名 drop 列名;删除列
DESC 表名;显示表的结构
DROP TABLE 表名; 删除表
Insert into 表名(列名1,列名2,...) values (数据1,数据2,...); 向表里插入数据
Select 列名1,列名2,... from 表名[条件表达式等]; 显示表中的数据
Update 表名 set 列名1=值1,列名1=值1,.... where 条件表达式; 更新标志的记录
Delete from 表名 where 条件表达式; 删除表中的记录
4、数据检索
①推荐明确指定列名:使用[*]来无条件地获得所有列数据,第一,获取到不需要的列就会浪费很多内存;第二,获得的数据会按表定义的列的顺序,如果修改了表列的顺序,对应的程序也必须进行修改。
②条件检索:必须使用WHERE语句。比较运算符有:=、<、>、<=、>=、<>(不等于)、IS[NOT] NULL(是否为空)、[NOT]LIKE(指定目标一致)、[NOT] BETWEEN(指定范围)、[NOT] IN(在指定候补值内)。
③模糊检索:select name from customer where name like '李%';
④ 多条件组合查询:使用and(并)、or(或)连接。理论运算符的优先顺序:NOT->AND->OR。
⑤结果排序:使用order by进行数据排序,可以指定ASC(升序)或DESC(降序),默认是ASC。
如:select name,age from customer where age>21 order by age DESC;
⑥取得指定数间的记录:LIMIT;
limit 2:从起始位置开始取出两件;
limit 1,2:从1开始取出两件。
⑦数据分组:GROUP BY,通常GROUP BY语句与统计函数一起使用。主要统计函数:AVG(列名)平均值、COUNT(列名)件数、MAX(列名)最大值、MIN(列名)最小值、SUM(列名)合计值。
⑧列的别名:select sex,COUNT(mid) as cnt from customer group by sex;其中as可以省略。
5、运算符与数据库函数
①运算符:+、-、*、/、DIV(除法返回结果的整数部分)、%(求余)、AND、OR。
②部分数据库函数
LENGTH函数:返回字符串的字节数
FLOOR/GEILING/TRUNCATE函数:用于小数四舍五入处理
DATE_ADD函数:对日期date进行指定值的加算处理
NOW()当前时间、CURDATE()当前日期、CURTIME()当前时刻、EXTRACT(YEAR_MONTH '2013-11-20 21:02:00')从给定的日期/时刻中取得任意元素(如年、月等)
CASE函数:条件判断
[sql] view
plaincopy


select name
case sex
when 0 then '男'
when 1 then '女'
else 'OTH'
end as sex
from customer;
6、多表连接查询
①内链接:返回结果集合中仅是符合查询条件和连接条件的记录;
[sql] view
plaincopy
select m.name,o.oid
from member m
<span style="color:#ff0000;">inner join </span>ordercord o
<span style="color:#ff6666;">on</span> m.id=o.mid
(where/order by等语句)
②外连接:返回的查询结果集中不仅是符合连接条件的行,而且还包括左表(左外连接)或右表(右外连接)中所有数据行;
左外连接:
[sql] view
plaincopy
select 列名1 from 表1
LEFT OUTER JOIN 表2
ON 表1.外键=表2.主键[WHERE/ORDER BY语句等]
右外连接:
[sql] view
plaincopy
select 列名1 from 表1
RIGHT OUTER JOIN 表2
ON 表1.外键=表2.主键[WHERE/ORDER BY语句等]
3个或3个以上表间连接,从内往外一层层的连接。
③子查询:先返回子查询的结果集,再返回主查询结果集。
第2部分 MySQL高级应用篇
7、MySQL的功能可以分为两部分:外层部分主要完成与客户端的连接以及事前调查SQL语句的内容的功能;而内层部分就是所谓的存储引擎部分,它负责接受外层的数据操作指示,完成实际的数据输入输出以及文件操作工作。MySQL提供的存储引擎有:MyISAM(默认的高速引擎,不支持事务处理)、InnoDB(支持行锁定以及事务处理,比MyISAM的处理速度稍慢)、ISAM等。
8、查看表中使用的引擎:show create table 表名 [\G];
修改表使用的引擎:alter table 表名 engine=新引擎;
其中,\G在MySQL监视框中显示出信息有序。
====>>事务
9、事务是指作为单个业务逻辑工作单元执行的一系列操作,要么全部成功,要么全部失败。MySQL提供的3个重要事务处理命令:BEGIN(声明事务处理开始)、COMMIT(提交整个事务)、ROLLBACK(回滚到事务开始的状态)。
10、MySQL默认自动提交事务。当然也可以通过SET AUTOCOMMIT=0;将自动提交功能置为OFF;也可以通过SET AUTOCOMMIT=1;将自动提交功能置为ON。
11、部分回滚:
定义保存点:savepoint 保存点名;
回滚到指定的保存点:rollback to savepoint 保存点名;
12、事务处理的利用范围,以下几条SQL命令,执行后将被自动提交,是在事务处理可以利用的范围之外:DROP DATABASE;DROP TABLE;DROP;ALTER TABLE;
13、多用户同时操作同一个数据库时,需要对其进行并发控制,MySQL通过锁来实现。锁分为共享锁和排他锁,共享锁是当用户参照数据时,将对象数据变为只读形式的锁定;排他锁是使用INSERT/UPDATE/DELETE命令对数据进行更新时,其他进程(或事务)一律不能对读取该数据。
14、锁定对象的大小,通常被称为锁定的粒度。支持的粒度随着数据库不同而有所差异,一般有3种锁定粒度:记录(行)、表、数据库;
15、锁定的粒度越小,运行性越高,但并不是越小的粒度越好,锁定的数目越多,消耗的服务器资源也越多。数据库中行单位粒度的锁定大量发生时,数据库有将这些锁定的粒度自动向上提升的机制,通常称为锁定提升。MySQL只支持行/表粒度,不支持锁定提升功能。
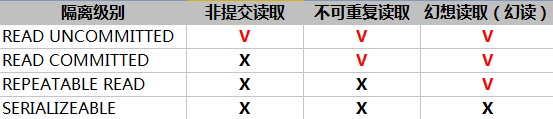
16、事务处理的隔离级别:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZEABLE。
17、事务处理的机制简单的说就是留下更新日志,数据库会根据这些日志信息,在必要时将就数据取回,或在发生错误是将数据恢复到原先的状态。与事务处理相关的日志可以分为两个类型:UNDO和REDO。
=====>>索引
18、索引就是表中所有记录的搜索引导,索引的经过排序的。有索引后,先查找索引再根据索引查找相应的记录。
19、大多数数据库中用B树(平衡树)的结果来保存索引的。
20、创建索引:create [unique] index 索引名 on 表名(列名,……);
查看表中所有的索引信息:show index from 表名 [\G];
删除索引:drop index 索引名 on 表名;
确认索引的使用情况(优劣):explain 调查对象 select 语句;
如:explain select * from employee where name='wang' \G;
复合索引:create index idx_employee_name on employee(name,sex);
唯一索引:create unique index idx_employee_name on employee(name);
索引名建议[idx_]的形式开头。
21、不适合使用索引的场合:
①模糊查询要求后方一致或部分一致检索;如:select * from employee where name like '%w%'或'%w';是不适合的。
②使用了IS NOT NULL、<>比较运算符的场合;如:select * from employee where name is not null;是不适合的。
③对列使用了运算/函数的场合;
④复合索引的第一列没被包含在where条件语句中的场合。如:select * from employee where name='wang' or age='1';是不适合的。
======>>视图
22、视图是伪表,视图本事不包含如何数据的,将多个物理表的数据通过视图动态地组织在一起,用户可以像使用普通物理表那样使用它。
23、视图具有以下特性:①可以公开表中特定的行和列;②简化复杂的SQL查询;③可以限制可插入/更新的值范围。
24、创建视图:create view 视图名(列名,...) as select 语句 [with check point];
删除视图:drop view 视图名;
查看视图所有列信息:show fields from 视图名;
视图名建议[v_]的形式开头。
25、不能进行插入/更新/删除操作的场合:
①视图列中含有统计函数
②视图定义使用了GROUP BY/HAVING语句,DISTINCT语句,UNION语句的情况
注:HAVING是对group by设置查询条件;distinct是要求查询结果没有重复项。
③视图定义时使用了子查询
④跨越多个表进行数据的变更操作
26、创建视图时使用[with check option]命令,将不能插入或更新不符合视图的检索条件的数据。
如:
[sql] view
plaincopy
create view v_product300up
as
select * from product where price >=300
with check option;
此时,变更操作要求price大于或等于300才能进行,否则就会出现[CHECK OPTION failed……]的错误信息。
=====>>存储过程
27、存储过程是数据库中保存的一系列SQL命令的集合,这些SQL命令通常并非简单的组合在一起,还可以使用各种条件判断、循环控制等,来实现简单的SQL命令不能实现的负责功能。
28、使用存储过程可以有这些好处:
①提高执行性能
②可减轻网络负担
③可防止对表的直接访问,提高安全性
④可将数据库的处理黑匣子化
29、定义存储过程:
ceate procedure 存储过程名(参数的种类1 参数1 参数类型1 [,参数的种类2,参数2,参数类型2…])
begin
处理内容
end
注:存储过程的参数可以分为输入参数(接受调用方的数据),输出参数(向调用方返回处理结果)。参数的种类可以是IN、OUT、INOUT其中之一。存储过程名前加上[sp_]的开头。
如:
[sql] view
plaincopy
<span style="color:#ff0000;">delimiter //</span>
create procedure sp_search_customer(IN p_name varchar(20) )
<span style="white-space:pre"> </span>begin
<span style="white-space:pre"> </span>if p_name is null or p_name='' then
<span style="white-space:pre"> </span>select * from customer;
<span style="white-space:pre"> </span>else
<span style="white-space:pre"> </span> select * from customer where name like p_name;
<span style="white-space:pre"> </span>end if;
<span style="white-space:pre"> </span>end
<span style="color:#ff0000;">delimiter ;</span>
注:上面delimiter命令改变分隔符为//,因为在存储过中使用到";"。
30、存储过程中可使用的控制语句:
①if...elseif...else...end if
②case when 值1 then 执行命令 when 值2 then 执行命令 else 执行名 end case
③循环控制(后置判断):repeat 直至条件表达式为true时才执行的命令 until 条件表达式 end repeat
④循环控制(前置判断):while 条件表达式 do 系列命令 end while
31、查看存储过程是否存在:show procedure status [\G];
查看存储过程信息:show create procedure 存储过程名;
删除存储过程:drop procedure 存储过程名;
执行存储过程名:call 存储过程名(参数,……);
32、定义存储过程可以声明局部变量:declare 变量名 数据类型[初始值];
赋值给变量:set 变量名=值;
=====>>存储函数
33、存储函数是保存在数据库中的函数(Function)。所谓函数就是按照事先决定的规则进行处理,然后将结果返回的单功能机制。
34、定义存储函数:
create function 函数名(
参数1 数据类型1
[,数据2 数据类型2...]
)returns 返回值类型
begin
任意系列SQL语句
return 返回值;
end
注:①参数只有输入型IN
②向调用返回结果值
③存储函数给定[fn_]的前缀
35、查看全部已创建的存储函数:show function status;
查看存储函数的信息:show create function 函数名 [\G];
存储函数调用:select 函数名(参数);
如:
[sql] view
plaincopy
delimiter //
create function fn_factorial(
f_num int
)returns int
begin
declare f_result int default 1;--定义局部变量并初始化为1
while f_num>1 do
set f_result=f_result*f_num;
set f_num=f_num-1;
end while;
retrun f_result;
delimiter ;
调用存储函数:
[sql] view
plaincopy
select fn_factorial(5), fn_factorial(0);
======>>触发器
36、触发器是在操作数据库时,执行一个动作,而触发了另一个动作。如删除表1的一条记录,在表2中插入一条日志记录。
37、创建触发器:
create trigger 触发器名 发生时刻 事件名
on 表名 for each row
begin
任意系列SQL语句
end
说明:①触发器不是直接与运行的,而是针对具体表的操作事时被调用的;
②决定触发器运行时刻具体是指发生在insert、update、delete等操作的前还是后,用before或after表示。
③for each row 表示以行为单位执行的,为固定值。
确认已创建完成的触发器列表和触发器的信息:show trigger [\G];
删除触发器:drop trigger 触发器名;
[sql] view
plaincopy
delimiter //
create trigger trg_customer_history after delete(
on customer for each row
begin
insert into customer_history(mid,name,birth,sex,updated)
<span style="white-space:pre"> </span>values(OLD.mid,OLD.name,OLD.birth,OLD.sex,NOW());
end;
delimiter ;
=====>>游标
38、游标就是对select语句取出的结果进行一件一件处理的功能。游标可以将多个查询记录进行一件一件的单独的处理。
[sql] view
plaincopy
[sql] view
plaincopy
delimiter //
create proceduce sp_cursor(
OUT p_result TEXT
)
begin
--定义标志变量flag(判断是否所有记录都被取出)
declare flag bit default 0;
--定义存储当前行的部署名的变量tmp
declare tmp varchar(20);
--定义游标取出游标中所有记录时的处理
declare cur cursor for select distinct depart from employee;
--定义取出游标中所有记录是的处理
declare continue handler for not found set flag=1;
--打开游标
open cur;
--从游标中一行行取出数据
while flag!=1 do
fetch cur into tmp;--将当前行中的内容保存到本地变量中
if flag!=1 then
--将变量tmp以逗号分隔的字符串的形式保存到输出参数p_result中
set p_result=concat_ws(',',p_result);
end if
end while; --标志变量为1后结束循环
--关闭游标
colse cur;
end
delimiter ;
[sql] view
plaincopy
调用游标:call sp_cursor(@p_result);
1、对于企业而言,选择MySQL数据库的两大原因:1)MySQL是开源关系型数据库产品,使用普及率高;2)性能出色,运行速度块。MySQL有免费和收费两种类型的产品。
2、mysql登录:cd 打开mysql的bin目录,执行“mysql -u root -p”回车,然后要求输入密码Enter password,正确输入密码后,回车,即可登录成功!
3、常用数据库查询命令:
show databases; 查看数据库服务器上的全部数据库
create database test; 创建一个名称为test的数据库
use test;使用test数据库
show tables;查看当前数据库中所有表
创建表:
create table 表名(
属性名数据类型列选项,
……
)
其中,列选项可以为AUTO_INCREMENT(自增),DEFAULT '默认值',INDEX(定义为索引),[NOT]NULL(允许/禁止NULL),PRIMARY KEY(定义为主键),UNIQUE(定义为唯一性),CHECK(定义可以输入的值的范围/选项)。
alter table 表名 modify 列名 数据类型;修改表中列的定义
alter table 表名 add 列名 数据类型;追加新列
alter table 表名 drop 列名;删除列
DESC 表名;显示表的结构
DROP TABLE 表名; 删除表
Insert into 表名(列名1,列名2,...) values (数据1,数据2,...); 向表里插入数据
Select 列名1,列名2,... from 表名[条件表达式等]; 显示表中的数据
Update 表名 set 列名1=值1,列名1=值1,.... where 条件表达式; 更新标志的记录
Delete from 表名 where 条件表达式; 删除表中的记录
4、数据检索
①推荐明确指定列名:使用[*]来无条件地获得所有列数据,第一,获取到不需要的列就会浪费很多内存;第二,获得的数据会按表定义的列的顺序,如果修改了表列的顺序,对应的程序也必须进行修改。
②条件检索:必须使用WHERE语句。比较运算符有:=、<、>、<=、>=、<>(不等于)、IS[NOT] NULL(是否为空)、[NOT]LIKE(指定目标一致)、[NOT] BETWEEN(指定范围)、[NOT] IN(在指定候补值内)。
③模糊检索:select name from customer where name like '李%';
④ 多条件组合查询:使用and(并)、or(或)连接。理论运算符的优先顺序:NOT->AND->OR。
⑤结果排序:使用order by进行数据排序,可以指定ASC(升序)或DESC(降序),默认是ASC。
如:select name,age from customer where age>21 order by age DESC;
⑥取得指定数间的记录:LIMIT;
limit 2:从起始位置开始取出两件;
limit 1,2:从1开始取出两件。
⑦数据分组:GROUP BY,通常GROUP BY语句与统计函数一起使用。主要统计函数:AVG(列名)平均值、COUNT(列名)件数、MAX(列名)最大值、MIN(列名)最小值、SUM(列名)合计值。
⑧列的别名:select sex,COUNT(mid) as cnt from customer group by sex;其中as可以省略。
5、运算符与数据库函数
①运算符:+、-、*、/、DIV(除法返回结果的整数部分)、%(求余)、AND、OR。
②部分数据库函数
LENGTH函数:返回字符串的字节数
FLOOR/GEILING/TRUNCATE函数:用于小数四舍五入处理
DATE_ADD函数:对日期date进行指定值的加算处理
NOW()当前时间、CURDATE()当前日期、CURTIME()当前时刻、EXTRACT(YEAR_MONTH '2013-11-20 21:02:00')从给定的日期/时刻中取得任意元素(如年、月等)
CASE函数:条件判断
[sql] view
plaincopy
select name
case sex
when 0 then '男'
when 1 then '女'
else 'OTH'
end as sex
from customer;
6、多表连接查询
①内链接:返回结果集合中仅是符合查询条件和连接条件的记录;
[sql] view
plaincopy
select m.name,o.oid
from member m
<span style="color:#ff0000;">inner join </span>ordercord o
<span style="color:#ff6666;">on</span> m.id=o.mid
(where/order by等语句)
②外连接:返回的查询结果集中不仅是符合连接条件的行,而且还包括左表(左外连接)或右表(右外连接)中所有数据行;
左外连接:
[sql] view
plaincopy
select 列名1 from 表1
LEFT OUTER JOIN 表2
ON 表1.外键=表2.主键[WHERE/ORDER BY语句等]
右外连接:
[sql] view
plaincopy
select 列名1 from 表1
RIGHT OUTER JOIN 表2
ON 表1.外键=表2.主键[WHERE/ORDER BY语句等]
3个或3个以上表间连接,从内往外一层层的连接。
③子查询:先返回子查询的结果集,再返回主查询结果集。
第2部分 MySQL高级应用篇
7、MySQL的功能可以分为两部分:外层部分主要完成与客户端的连接以及事前调查SQL语句的内容的功能;而内层部分就是所谓的存储引擎部分,它负责接受外层的数据操作指示,完成实际的数据输入输出以及文件操作工作。MySQL提供的存储引擎有:MyISAM(默认的高速引擎,不支持事务处理)、InnoDB(支持行锁定以及事务处理,比MyISAM的处理速度稍慢)、ISAM等。
8、查看表中使用的引擎:show create table 表名 [\G];
修改表使用的引擎:alter table 表名 engine=新引擎;
其中,\G在MySQL监视框中显示出信息有序。
====>>事务
9、事务是指作为单个业务逻辑工作单元执行的一系列操作,要么全部成功,要么全部失败。MySQL提供的3个重要事务处理命令:BEGIN(声明事务处理开始)、COMMIT(提交整个事务)、ROLLBACK(回滚到事务开始的状态)。
10、MySQL默认自动提交事务。当然也可以通过SET AUTOCOMMIT=0;将自动提交功能置为OFF;也可以通过SET AUTOCOMMIT=1;将自动提交功能置为ON。
11、部分回滚:
定义保存点:savepoint 保存点名;
回滚到指定的保存点:rollback to savepoint 保存点名;
12、事务处理的利用范围,以下几条SQL命令,执行后将被自动提交,是在事务处理可以利用的范围之外:DROP DATABASE;DROP TABLE;DROP;ALTER TABLE;
13、多用户同时操作同一个数据库时,需要对其进行并发控制,MySQL通过锁来实现。锁分为共享锁和排他锁,共享锁是当用户参照数据时,将对象数据变为只读形式的锁定;排他锁是使用INSERT/UPDATE/DELETE命令对数据进行更新时,其他进程(或事务)一律不能对读取该数据。
14、锁定对象的大小,通常被称为锁定的粒度。支持的粒度随着数据库不同而有所差异,一般有3种锁定粒度:记录(行)、表、数据库;
15、锁定的粒度越小,运行性越高,但并不是越小的粒度越好,锁定的数目越多,消耗的服务器资源也越多。数据库中行单位粒度的锁定大量发生时,数据库有将这些锁定的粒度自动向上提升的机制,通常称为锁定提升。MySQL只支持行/表粒度,不支持锁定提升功能。
16、事务处理的隔离级别:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZEABLE。
17、事务处理的机制简单的说就是留下更新日志,数据库会根据这些日志信息,在必要时将就数据取回,或在发生错误是将数据恢复到原先的状态。与事务处理相关的日志可以分为两个类型:UNDO和REDO。
=====>>索引
18、索引就是表中所有记录的搜索引导,索引的经过排序的。有索引后,先查找索引再根据索引查找相应的记录。
19、大多数数据库中用B树(平衡树)的结果来保存索引的。
20、创建索引:create [unique] index 索引名 on 表名(列名,……);
查看表中所有的索引信息:show index from 表名 [\G];
删除索引:drop index 索引名 on 表名;
确认索引的使用情况(优劣):explain 调查对象 select 语句;
如:explain select * from employee where name='wang' \G;
复合索引:create index idx_employee_name on employee(name,sex);
唯一索引:create unique index idx_employee_name on employee(name);
索引名建议[idx_]的形式开头。
21、不适合使用索引的场合:
①模糊查询要求后方一致或部分一致检索;如:select * from employee where name like '%w%'或'%w';是不适合的。
②使用了IS NOT NULL、<>比较运算符的场合;如:select * from employee where name is not null;是不适合的。
③对列使用了运算/函数的场合;
④复合索引的第一列没被包含在where条件语句中的场合。如:select * from employee where name='wang' or age='1';是不适合的。
======>>视图
22、视图是伪表,视图本事不包含如何数据的,将多个物理表的数据通过视图动态地组织在一起,用户可以像使用普通物理表那样使用它。
23、视图具有以下特性:①可以公开表中特定的行和列;②简化复杂的SQL查询;③可以限制可插入/更新的值范围。
24、创建视图:create view 视图名(列名,...) as select 语句 [with check point];
删除视图:drop view 视图名;
查看视图所有列信息:show fields from 视图名;
视图名建议[v_]的形式开头。
25、不能进行插入/更新/删除操作的场合:
①视图列中含有统计函数
②视图定义使用了GROUP BY/HAVING语句,DISTINCT语句,UNION语句的情况
注:HAVING是对group by设置查询条件;distinct是要求查询结果没有重复项。
③视图定义时使用了子查询
④跨越多个表进行数据的变更操作
26、创建视图时使用[with check option]命令,将不能插入或更新不符合视图的检索条件的数据。
如:
[sql] view
plaincopy
create view v_product300up
as
select * from product where price >=300
with check option;
此时,变更操作要求price大于或等于300才能进行,否则就会出现[CHECK OPTION failed……]的错误信息。
=====>>存储过程
27、存储过程是数据库中保存的一系列SQL命令的集合,这些SQL命令通常并非简单的组合在一起,还可以使用各种条件判断、循环控制等,来实现简单的SQL命令不能实现的负责功能。
28、使用存储过程可以有这些好处:
①提高执行性能
②可减轻网络负担
③可防止对表的直接访问,提高安全性
④可将数据库的处理黑匣子化
29、定义存储过程:
ceate procedure 存储过程名(参数的种类1 参数1 参数类型1 [,参数的种类2,参数2,参数类型2…])
begin
处理内容
end
注:存储过程的参数可以分为输入参数(接受调用方的数据),输出参数(向调用方返回处理结果)。参数的种类可以是IN、OUT、INOUT其中之一。存储过程名前加上[sp_]的开头。
如:
[sql] view
plaincopy
<span style="color:#ff0000;">delimiter //</span>
create procedure sp_search_customer(IN p_name varchar(20) )
<span style="white-space:pre"> </span>begin
<span style="white-space:pre"> </span>if p_name is null or p_name='' then
<span style="white-space:pre"> </span>select * from customer;
<span style="white-space:pre"> </span>else
<span style="white-space:pre"> </span> select * from customer where name like p_name;
<span style="white-space:pre"> </span>end if;
<span style="white-space:pre"> </span>end
<span style="color:#ff0000;">delimiter ;</span>
注:上面delimiter命令改变分隔符为//,因为在存储过中使用到";"。
30、存储过程中可使用的控制语句:
①if...elseif...else...end if
②case when 值1 then 执行命令 when 值2 then 执行命令 else 执行名 end case
③循环控制(后置判断):repeat 直至条件表达式为true时才执行的命令 until 条件表达式 end repeat
④循环控制(前置判断):while 条件表达式 do 系列命令 end while
31、查看存储过程是否存在:show procedure status [\G];
查看存储过程信息:show create procedure 存储过程名;
删除存储过程:drop procedure 存储过程名;
执行存储过程名:call 存储过程名(参数,……);
32、定义存储过程可以声明局部变量:declare 变量名 数据类型[初始值];
赋值给变量:set 变量名=值;
=====>>存储函数
33、存储函数是保存在数据库中的函数(Function)。所谓函数就是按照事先决定的规则进行处理,然后将结果返回的单功能机制。
34、定义存储函数:
create function 函数名(
参数1 数据类型1
[,数据2 数据类型2...]
)returns 返回值类型
begin
任意系列SQL语句
return 返回值;
end
注:①参数只有输入型IN
②向调用返回结果值
③存储函数给定[fn_]的前缀
35、查看全部已创建的存储函数:show function status;
查看存储函数的信息:show create function 函数名 [\G];
存储函数调用:select 函数名(参数);
如:
[sql] view
plaincopy
delimiter //
create function fn_factorial(
f_num int
)returns int
begin
declare f_result int default 1;--定义局部变量并初始化为1
while f_num>1 do
set f_result=f_result*f_num;
set f_num=f_num-1;
end while;
retrun f_result;
delimiter ;
调用存储函数:
[sql] view
plaincopy
select fn_factorial(5), fn_factorial(0);
======>>触发器
36、触发器是在操作数据库时,执行一个动作,而触发了另一个动作。如删除表1的一条记录,在表2中插入一条日志记录。
37、创建触发器:
create trigger 触发器名 发生时刻 事件名
on 表名 for each row
begin
任意系列SQL语句
end
说明:①触发器不是直接与运行的,而是针对具体表的操作事时被调用的;
②决定触发器运行时刻具体是指发生在insert、update、delete等操作的前还是后,用before或after表示。
③for each row 表示以行为单位执行的,为固定值。
确认已创建完成的触发器列表和触发器的信息:show trigger [\G];
删除触发器:drop trigger 触发器名;
[sql] view
plaincopy
delimiter //
create trigger trg_customer_history after delete(
on customer for each row
begin
insert into customer_history(mid,name,birth,sex,updated)
<span style="white-space:pre"> </span>values(OLD.mid,OLD.name,OLD.birth,OLD.sex,NOW());
end;
delimiter ;
=====>>游标
38、游标就是对select语句取出的结果进行一件一件处理的功能。游标可以将多个查询记录进行一件一件的单独的处理。
[sql] view
plaincopy
[sql] view
plaincopy
delimiter //
create proceduce sp_cursor(
OUT p_result TEXT
)
begin
--定义标志变量flag(判断是否所有记录都被取出)
declare flag bit default 0;
--定义存储当前行的部署名的变量tmp
declare tmp varchar(20);
--定义游标取出游标中所有记录时的处理
declare cur cursor for select distinct depart from employee;
--定义取出游标中所有记录是的处理
declare continue handler for not found set flag=1;
--打开游标
open cur;
--从游标中一行行取出数据
while flag!=1 do
fetch cur into tmp;--将当前行中的内容保存到本地变量中
if flag!=1 then
--将变量tmp以逗号分隔的字符串的形式保存到输出参数p_result中
set p_result=concat_ws(',',p_result);
end if
end while; --标志变量为1后结束循环
--关闭游标
colse cur;
end
delimiter ;
[sql] view
plaincopy
调用游标:call sp_cursor(@p_result);

相关文章推荐
- Mysql中字段大小写敏感问题
- MySQL Study之--MySQL 表连接
- MySQL Study之--MySQL 表连接
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!
- MYSQL 常用查詢
- mysql命令行下将数据导出成excel文件
- mysql数据库操作缓慢,原来是字段的内容过长导致的,看来cache很有用.报错:Lock wait timeout exceeded; try restarting transaction
- MySQL索引的查看创建和删除
- mysql 执行alter语句
- windows下Mysql免安装版配置
- mysql中char与varchar的区别分析
- mac mysql(5.6.27) 中文乱码
- MySQL 基本查询语法使用
- mysql limit
- 连接Mysql提示Can’t connect to local MySQL server through socket的解决方法
- MySQL的启动脚本
- MySQL 存储过程之游标
- Hibernate 与Mysql 关键字冲突
- MYSQL 二进制日志
- mysql权限设置