分类算法属性选择度量--信息增益、增益率、Gini指标
2015-11-22 19:27
274 查看
属性选择度量就是分裂规则,用来确定分裂属性和分裂子集
信息增益
信息增益:某属性的信息增益值越大,这个属性作为一棵树的根节点就能使这棵树更简洁,降低树的高度。衡量给定属性划分训练样本的能力。计算信息增益的公式需要用到“熵”(Entropy)。熵:衡量任意样本集的纯度,熵越小,样本纯度越高。以二分类为例,
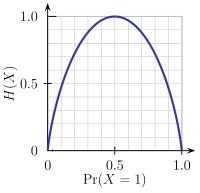
H(X)表示熵,横坐标表示类别A在这两个类{A,B}中的百分比,越接近0.5,表示两个类对抗越明显。值越接近0,表示某个类占的比例越大或越小,也就是样本纯度越高。

相关文章推荐
- IOS中输入框被软键盘遮挡的解决办法
- Django 数据库键值处理
- HPU 1189:HH的字符逆序【水】
- 企业怎样玩转10亿网民?田溯宁有不一样的想法!
- 邻接矩阵
- HADOOP笔记
- 非链接方式访问数据库--查询的数据集用Dataset来存储。
- 【nginx】关于gzip压缩
- C语言关键字的使用注意事项
- UIWebView和html的简单交互
- OD使用教程12
- 密码修改机制
- Android平台关于时间和日期的相关类和方法(Date/Time)
- Spring MVC 入参支持数组
- 利用UIWebView显示pdf文件,网页等等
- java数据封装
- CentOS 6.5 安装Apache服务器后无法访问解决方法
- GCD多线程
- 使用Spring Roo构建项目
- 抛砖引玉:新大话2儿女养成之后之童工篇