Python抓取淘女郎网页信息以及代码下载
2015-11-22 14:03
851 查看
上一篇Python抓取糗事百科网页信息以及源码下载
也是利用python抓取网页信息,轻车熟路,知道一个之后,轻轻松松就是实现啦。
淘女郎网页地址:https://mm.taobao.com/json/request_top_list.htm?page=1
page=1代表第一页淘女郎信息列表。
页面信息如下;
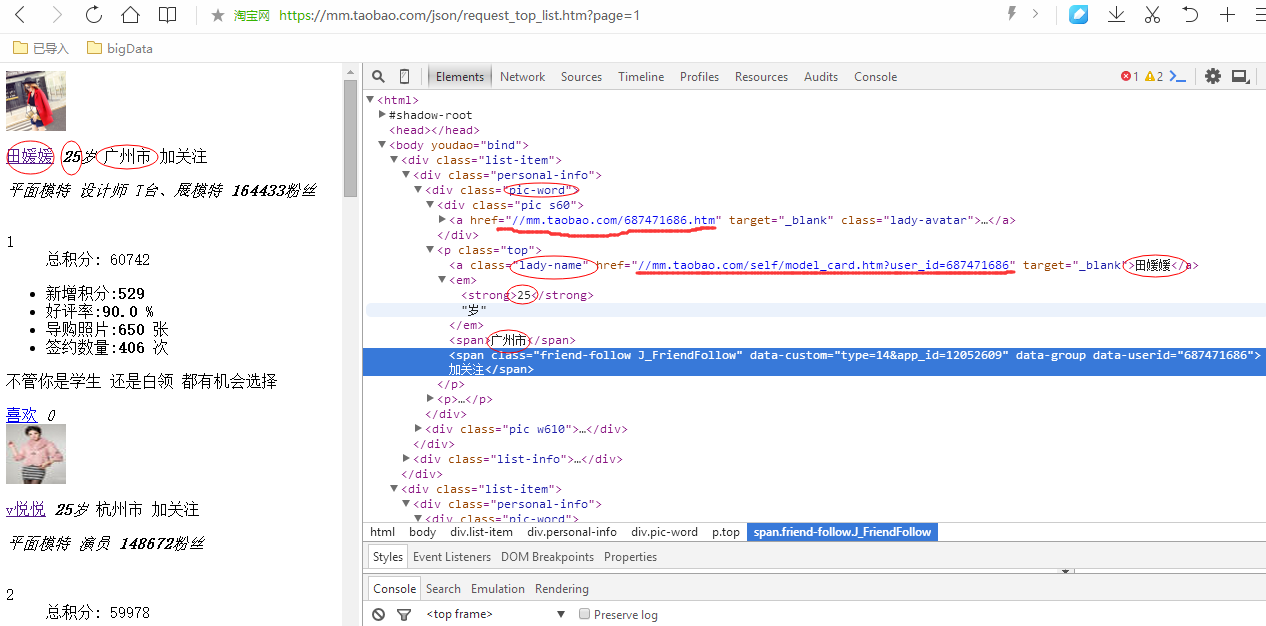
页面整体的html代码如下:

代码效果如下:

基本上可以把美眉的信息以及个人网址抓取到。其中的地址前面缺少https:,网址加上这个https:就可以了。
但是淘宝牛掰,把网址都使用了安全协议,需要登录认证之后才可以到页面信息中。现在还没有做登录之后的功能,所以目前仅仅把美眉的个人信息以及网址抓取到了。研究好利用python登录的功能之后,在把淘女郎的更加详细的信息以及海量图片抓取到。然后再更新本博客。
整个代码还是比较简单的。
其中关键的部分还是正则表达式部分:
这里需要对照网页的html代码进行比对:
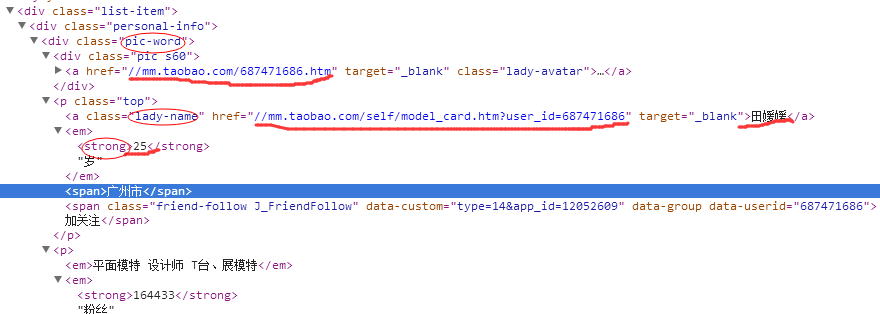
仔细比对html和正则表达式部分,然后利用(.*?)这个表达式把有用信息进行分组得到想要获取的信息。每个圆括号对应元组的一个值。这里有六个圆括号,每一个元组有六个数据。

这里对获取到的六个item数据进行输出。
还是要提醒一句,上面的内容对于我现在是有用的,如果当你看到这篇文章的时候,可能网页的html代码已经改变,则需要调整正则表达式的代码才能与网页进行匹配,进而获取有用的信息。
python代码下载,请猛戳这里!
Github地址,在这里!
github地址不仅仅有淘女郎网页的抓取,还有糗事百科网页信息的抓取,后期还会有更多内容加入。欢迎关注!^_^【握手~】
也是利用python抓取网页信息,轻车熟路,知道一个之后,轻轻松松就是实现啦。
淘女郎网页地址:https://mm.taobao.com/json/request_top_list.htm?page=1
page=1代表第一页淘女郎信息列表。
页面信息如下;
页面整体的html代码如下:
代码效果如下:
基本上可以把美眉的信息以及个人网址抓取到。其中的地址前面缺少https:,网址加上这个https:就可以了。
但是淘宝牛掰,把网址都使用了安全协议,需要登录认证之后才可以到页面信息中。现在还没有做登录之后的功能,所以目前仅仅把美眉的个人信息以及网址抓取到了。研究好利用python登录的功能之后,在把淘女郎的更加详细的信息以及海量图片抓取到。然后再更新本博客。
整个代码还是比较简单的。
#coding:utf-8
__author__ = 'CQC'
import re
import urllib2
import tool
#抓取MM
class Spider:
#页面初始化
def __init__(self):
self.siteURL = 'http://mm.taobao.com/json/request_top_list.htm'
self.tool = tool.Tool()
#获取索引页面的内容
def getPage(self,pageIndex):
url = self.siteURL + "?page=" + str(pageIndex)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read().decode('gbk')
#获取索引界面所有MM的信息,list格式
def getContents(self,pageIndex):
page = self.getPage(pageIndex)
# 这里获取六条信息 个人信息网址,头像图片地址,美眉个人信息页地址,美眉名字,年龄,居住地址
pattern = re.compile('<div class="list-item".*?pic-word.*?'+
'<a href="(.*?)".target=.*?<img src="(.*?)".alt.*?'+
'<a class="lady-name".href="(.*?)".target=.*?>(.*?)'+
'</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S)
items = re.findall(pattern,page)
contents = []
for item in items:
contents.append([item[0],item[1],item[2],item[3],item[4],item[5]])
return contents
#将一页淘宝MM的信息保存起来
def savePageInfo(self,pageIndex):
#获取第一页淘宝MM列表
contents = self.getContents(pageIndex)
for item in contents:
#item[0]个人详情URL,item[1]头像URL,item[2]是个人信息地址,item[3]姓名,
#item[4]年龄,item[5]居住地
print u"发现一位模特,名字叫",item[3],u"芳龄",item[4],u",她在",item[5]
print u"正在偷偷地保存",item[3],"的信息"
print u"又意外地发现她的个人地址是",item[0] #这个地址需要登录
print u"名字对应的个人信息地址是",item[2] #这个地址有用
#个人详情页面的URL
detailURL = item[0]
print 'detailURL=https:%s' %detailURL
def savePagesInfo(self,start,end):
for i in range(start,end+1):
print u"正在偷偷寻找第",i,u"个地方,看看MM们在不在"
self.savePageInfo(i)
#传入起止页码即可,在此传入了1,10,表示抓取第1到10页的MM
spider = Spider()
spider.savePagesInfo(1,10)其中关键的部分还是正则表达式部分:
# 这里获取六条信息 个人信息网址,头像图片地址,美眉个人信息页地址,美眉名字,年龄,居住地址
pattern = re.compile('<div class="list-item".*?pic-word.*?'+
'<a href="(.*?)".target=.*?<img src="(.*?)".alt.*?'+
'<a class="lady-name".href="(.*?)".target=.*?>(.*?)'+
'</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S)这里需要对照网页的html代码进行比对:
仔细比对html和正则表达式部分,然后利用(.*?)这个表达式把有用信息进行分组得到想要获取的信息。每个圆括号对应元组的一个值。这里有六个圆括号,每一个元组有六个数据。
这里对获取到的六个item数据进行输出。
还是要提醒一句,上面的内容对于我现在是有用的,如果当你看到这篇文章的时候,可能网页的html代码已经改变,则需要调整正则表达式的代码才能与网页进行匹配,进而获取有用的信息。
python代码下载,请猛戳这里!
Github地址,在这里!
github地址不仅仅有淘女郎网页的抓取,还有糗事百科网页信息的抓取,后期还会有更多内容加入。欢迎关注!^_^【握手~】

相关文章推荐
- python的编码问题研究------使用scrapy体验
- [Python]利用python爬虫去LeetCode上下载Ac解
- 如何在cmd命令下运行python脚本
- installation about python package and complier
- windows下selenium+python环境搭建
- Python 运算符
- Python 变量类型
- Python 基础语法
- Python 中文编码
- Python 环境搭建
- Python 简介
- Python 快速教程(Django07):马不停蹄
- Python 快速教程(Django06):假作真时
- Python 快速教程(Django05):黑面管家
- Python 快速教程(Django03): 所谓伊人
- Python 快速教程(Django02):庄园疑云
- Python之旅(三)
- Python 快速教程(Django01):初试天涯
- windows 64位安装Python以及PIL模块详细步骤
- [置顶] python基于dlib的face landmarks