Python爬虫——爬取网站的图片
2015-11-19 15:04
573 查看
爬虫这东西最早出现在我大学计算机网络的课程上面,我们当时的老师人很好,期末不笔试,他说这东西笔试没什么用,对于一个年纪比较大的老师来讲,能提出这种方式,实在难得。当时在考虑做一个与网络有关的东西好,第一个想到的就是爬虫。想想也没想过用Java写过这种东西,所以当时是一般看一本爬虫的书一边敲代码,现在想起来有很多东西是没有想明白的——我当时爬的是刘末鹏的博客,把全部文章用分类爬了下来,在本地可以打开。
后面老师评价的时候就说,你这个只能爬这个,其实你应该让他智能些,让他可以爬图片,可以爬特定的内容,我想想也是,不过知道的,后续有别的东西就没再去弄了。
而后知道写爬虫还可以用Python写,前面草草看了Python的一点东西,不系统。
后面看了《Learn Python in hard way》,嗯,这本书其实是为了连没有编程基础的人也学会,有编程基础的英文却不好的,可以练练英文,其实书到后面的跨度是比较大的,包括那个课后的习题游戏,自己不理清思路还是很难写出来。
有了大概的基础之后,你会发现,python有好多好多API。
《The Python Standard Library by Example》是一本大厚书,这种书更像查字典,官网的Python library的例子有点蛋疼。这本书超级详细,包括正则表达式。
学这门语言的时候遇到很多有趣的事情。
当年那位在圣诞无聊开发了一门编程语言的人就是Python的作者。
用自带的库也能写爬虫,但是有一个第三方库用起来很方便——requests,这个库不有趣,有趣的是他的作者——Kenneth Reitz。很年轻。为什么说有趣,是因为我看了之后上一个减肥的问题。
减肥前,他长——

减肥后,他长——

他爱好好像也是摄影,GitHub上的粉丝也是多。无论从编程还是减肥,他都是一个励志的例子。
回来正题:
当你要做点什么东西的时候,你还是需要想清楚你要获取什么,不然你很难写下去。像我刚开始模拟登录知乎的时候,登录完成后很高兴,后面也不知道怎么去爬,也没思路。后面有同事想获取一个网站上的图片,他花了好多钱买了一个php上传图片的工程,不禁感叹淘宝的钱真好赚。而他要下载图片,想想自己最近学的requests库还有其他东西。决定帮他爬。
要爬的是http://zone.quanjing.com这个网站。首先我先找了设计这个分类下的照片,分析了下html的源代码。
<img class="250img" width="250" height="337" title="" alt=""
showsrc="http://zonepic.quanjing.com/photo/p0/151112/151112-023836-ewvdeb.jpg" src="/image/grey.gif">
</a> </div></center></div>
<div class="favorite"><p class="title" title="跨界创意"><a href="http://www.quanjing.com/share/1160068">跨界创意</a>
其实知道自己获取这些数据之后,接下来要做的就是知道用正则如何去匹配到。思路有了,实现就简单了。
然后你知道怎么用requests库,python的一些基础,正则表达式就可以爬取到首页的图片了。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author: iaiti
# @Date: 2015-11-17 15:18:28
# @Last Modified by: Administrator
# @Last Modified time: 2015-11-19 11:11:37
import re
import requests
import sys
#设置编码
reload(sys)
sys.setdefaultencoding('utf-8')
circle = requests.get("http://zone.quanjing.com/share/design/")
#text和content的内容有不同
ccontent = circle.text
#这里是正则的坑 括号的东西是分组的 外面没有括号之前 只会匹配到jpg和png不会匹配全部
#外面多一层括号才会匹配整个 但是特别的是 里面的括号也会匹配 所以
#真正findall的是整个list list里面每个都是元组 元组里面有xxx.jpg和jpg
pattern = "(http:[^\s]*?(jpg|png|PNG|JPG))"
finder = re.findall(pattern, circle.text)
#匹配到之后获取匹配开头和末尾位置
# finder = re.search(pattern, test)
# start = finder.start()
# end = finder.end()
# print test[start:end]
#匹配http 获取文件名
truepicture = ".*photo/p0.*"
#匹配图片网址
picpattern = "http:[^\s]*/"
#匹配标题
titlepattern = '<p class="title" title=".*?"'
imgfinder = re.findall(titlepattern, circle.text)
imglen = 0
for n in xrange(0,len(finder)):
if re.match(truepicture, finder
[0]):
print finder
[0]
#p0改为r0后变成了大图目录的地址,
bigpicture = finder
[0].replace('photo/p0','photo/r0')
newimg = requests.get(bigpicture)
#替换掉无关的字符串
temp = imgfinder[imglen].replace('<p class="title" title="','')
newfinder = re.search(picpattern, finder
[0])
#截取title
temp = "G:/github/WebSpider_Python/img/"+temp[0:len(temp)-1]+'.jpg'
#下载文件,超级简单 设定好目录 content的意义也在于这里
with open(temp,'wb') as newfile:
newfile.write(newimg.content)
imglen = imglen+1
先上代码,其实爬虫这东西的文章,很多跨度太大,但是要给自己信心,不要别人可以爬的你也可以,看了一些基本的之后,自己动手写才是最重要的。我在这里写这篇,也是给个思路那样。
其实爬了首页之后,发现就那么几张图片。当你你鼠标往下拉,会自动加载东西。所以,万能的抓包出现了,和wireshark抓包不同的是,wireshark抓的包比较详细,包括tcp三次握手等等,嗯,前辈跟我说的,它带有很多路由信息。我们只需要分析http请求,所以chrome自带的调试工具,足矣。
按下F12。往下拉,然后请求都会被捕获。
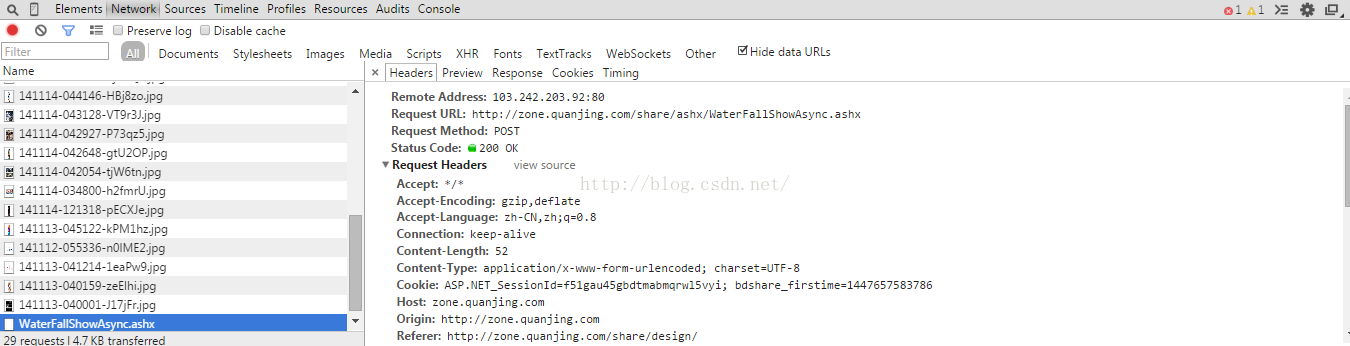
现在想想我想起了以前面试的时候面试官问我的东西,get和post的区别,我答的是get提交的数据会被捕捉到,post不会,想想当时懂的还是不多。
不过学习中也找到了问题的答案。
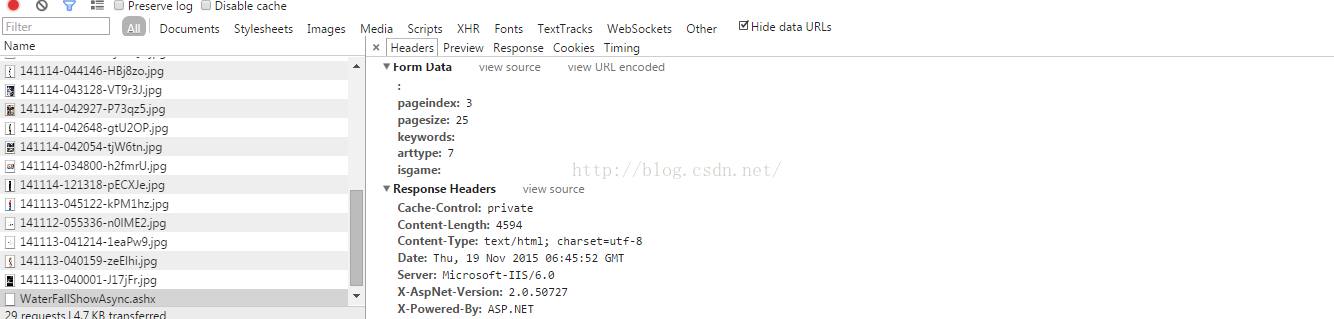
从捕获的东西上看出,网站后台用了.net。然后post了这些参数。
再看看js文件。
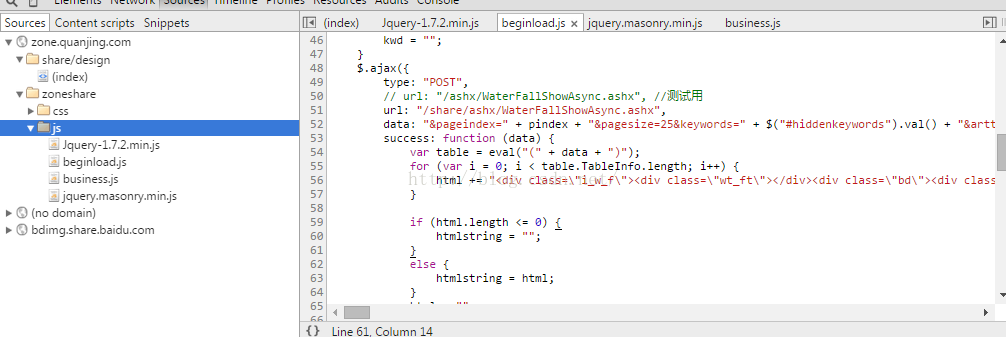
其实从这里我发现到和我写的系统惊人的相似,这就是前后端分离的结果。
前端可以写的完全一模一样,但是后台可以使用.net,也可以使用java。嗯,用requests模拟请求这个,得到的是:
{ "TableInfo":[ { "id":"1123130","FilePath":"141118-121609-fVwIzH.jpg","userid":"974767",
"title":"%e4%b8%8d%e8%8a%b1%e9%92%b1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
"Height":"255","UserName":"广州合丰","headpic":"default.jpg"},
{ "id":"1123129","FilePath":"141118-121233-LxISqc.jpg","userid":"974767",
"title":"%e5%8d%93%e8%b6%8a%e6%b2%83%e6%9c%8d%e5%8a%a1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
"Height":"1374","UserName":"广州合丰","headpic":"default.jpg"}]}
字典里面TableInfo的值是列表,列表中的每个值又是字典,title是url编码后的中文,FilePathe就是图片路径。
返回后的json串通过js的处理后拼接,再放入到前面那个页面的div里面,做到滚动显示。
其实基本的玩法也就是这样,嗯,我还被前辈批实战经验不足,确实要多搞搞才行。
python代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author: iaiti
# @Date: 2015-11-18 10:41:10
# @Last Modified by: Administrator
# @Last Modified time: 2015-11-19 14:55:01
import re
import requests
import sys
import json
from urllib import unquote
reload(sys)
sys.setdefaultencoding('utf-8')
#获取到匹配字符的字符串
def find(pattern,test):
finder = re.search(pattern, test)
start = finder.start()
end = finder.end()
return test[start:end-1]
#大图的网址为r0 小图为p0
picturepath = 'http://zonepic.quanjing.com/photo/r0/'
#循环发送ajax请求 捉取大量图片
# for x in xrange(100,200):
#ajax采用post请求,通过抓包可以看出具体请求的参数
#http://zone.quanjing.com/share/design/ post参数为此url下下拉加载ajax请求所需要的参数
formdata = {'pageindex':'','pagesize':'25','keywords':'','arttype':'7','isgame':''}
#批量获取时,pageindex
#formdata['pageindex'] = x
formdata['pageindex'] = 2
#模拟post请求
circle = requests.post("http://zone.quanjing.com/share/ashx/WaterFallShowAsync.ashx",data=formdata)
#匹配后缀为jpg和png的链接
pattern = "(http:[^\s]*?(jpg|png))"
finder = re.findall(pattern, circle.text)
# 字典里面TableInfo的值是列表,列表中的每个值又是字典,title是url编码后的中文,FilePathe就是图片路径
# { "TableInfo":[ { "id":"1123130","FilePath":"141118-121609-fVwIzH.jpg","userid":"974767",
# "title":"%e4%b8%8d%e8%8a%b1%e9%92%b1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
# "Height":"255","UserName":"广州合丰","headpic":"default.jpg"},
# { "id":"1123129","FilePath":"141118-121233-LxISqc.jpg","userid":"974767",
# "title":"%e5%8d%93%e8%b6%8a%e6%b2%83%e6%9c%8d%e5%8a%a1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
# "Height":"1374","UserName":"广州合丰","headpic":"default.jpg"}]}
print circle.text
#json串转字典,获取TableInfo的值
mydict = json.loads(circle.text)
tablekey = mydict['TableInfo']
#print tablekey
#由于http://zonepic.quanjing.com/photo/p0/151112/151112-040832-zxe6fZ.jpg p0后面的
#文件夹命名为图片前面的数字命名,所以匹配此字符串
secondfile = '.*?-'
print len(tablekey)
#遍历列表
for keyarray in tablekey:
print str(keyarray['title'])
#中文title的url解码
imgfilename =unquote(str(keyarray['title'])).decode('utf8')
#由于要把标题当做文件名,但是文件名不能包含*<>/\:这些特殊字符
imgfilename =imgfilename.replace('>', '').replace('*', '').replace('<', '').replace('/', '').replace(':', '').replace('\\', '').replace('|', '')
imgnametemp = "G:/github/WebSpider_Python/img/"+imgfilename+".jpg"
print imgfilename
filepath = keyarray['FilePath']
print filepath
print picturepath+find(secondfile,keyarray['FilePath'])+'/'+keyarray['FilePath']
#requests请求图片地址
newimg = requests.get(picturepath+find(secondfile,keyarray['FilePath'])+'/'+keyarray['FilePath'])
with open(imgnametemp,'wb') as newfile:
#获取图片内容并往磁盘写入,命名为匹配的中文title名加上后缀
newfile.write(newimg.content)
这样,我跟我同事完美地交了差,同时吐槽他这网站很多图片没有标题。
上面的代码有些写得不符合规范,也没有用到多线程去捉取,解析html也没有用Beautiful soup这些。后面慢慢补上。
这个东西写完之后,找回了很多东西。
后面老师评价的时候就说,你这个只能爬这个,其实你应该让他智能些,让他可以爬图片,可以爬特定的内容,我想想也是,不过知道的,后续有别的东西就没再去弄了。
而后知道写爬虫还可以用Python写,前面草草看了Python的一点东西,不系统。
后面看了《Learn Python in hard way》,嗯,这本书其实是为了连没有编程基础的人也学会,有编程基础的英文却不好的,可以练练英文,其实书到后面的跨度是比较大的,包括那个课后的习题游戏,自己不理清思路还是很难写出来。
有了大概的基础之后,你会发现,python有好多好多API。
《The Python Standard Library by Example》是一本大厚书,这种书更像查字典,官网的Python library的例子有点蛋疼。这本书超级详细,包括正则表达式。
学这门语言的时候遇到很多有趣的事情。
当年那位在圣诞无聊开发了一门编程语言的人就是Python的作者。
用自带的库也能写爬虫,但是有一个第三方库用起来很方便——requests,这个库不有趣,有趣的是他的作者——Kenneth Reitz。很年轻。为什么说有趣,是因为我看了之后上一个减肥的问题。
减肥前,他长——
减肥后,他长——
他爱好好像也是摄影,GitHub上的粉丝也是多。无论从编程还是减肥,他都是一个励志的例子。
回来正题:
当你要做点什么东西的时候,你还是需要想清楚你要获取什么,不然你很难写下去。像我刚开始模拟登录知乎的时候,登录完成后很高兴,后面也不知道怎么去爬,也没思路。后面有同事想获取一个网站上的图片,他花了好多钱买了一个php上传图片的工程,不禁感叹淘宝的钱真好赚。而他要下载图片,想想自己最近学的requests库还有其他东西。决定帮他爬。
要爬的是http://zone.quanjing.com这个网站。首先我先找了设计这个分类下的照片,分析了下html的源代码。
<img class="250img" width="250" height="337" title="" alt=""
showsrc="http://zonepic.quanjing.com/photo/p0/151112/151112-023836-ewvdeb.jpg" src="/image/grey.gif">
</a> </div></center></div>
<div class="favorite"><p class="title" title="跨界创意"><a href="http://www.quanjing.com/share/1160068">跨界创意</a>
其实知道自己获取这些数据之后,接下来要做的就是知道用正则如何去匹配到。思路有了,实现就简单了。
然后你知道怎么用requests库,python的一些基础,正则表达式就可以爬取到首页的图片了。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author: iaiti
# @Date: 2015-11-17 15:18:28
# @Last Modified by: Administrator
# @Last Modified time: 2015-11-19 11:11:37
import re
import requests
import sys
#设置编码
reload(sys)
sys.setdefaultencoding('utf-8')
circle = requests.get("http://zone.quanjing.com/share/design/")
#text和content的内容有不同
ccontent = circle.text
#这里是正则的坑 括号的东西是分组的 外面没有括号之前 只会匹配到jpg和png不会匹配全部
#外面多一层括号才会匹配整个 但是特别的是 里面的括号也会匹配 所以
#真正findall的是整个list list里面每个都是元组 元组里面有xxx.jpg和jpg
pattern = "(http:[^\s]*?(jpg|png|PNG|JPG))"
finder = re.findall(pattern, circle.text)
#匹配到之后获取匹配开头和末尾位置
# finder = re.search(pattern, test)
# start = finder.start()
# end = finder.end()
# print test[start:end]
#匹配http 获取文件名
truepicture = ".*photo/p0.*"
#匹配图片网址
picpattern = "http:[^\s]*/"
#匹配标题
titlepattern = '<p class="title" title=".*?"'
imgfinder = re.findall(titlepattern, circle.text)
imglen = 0
for n in xrange(0,len(finder)):
if re.match(truepicture, finder
[0]):
print finder
[0]
#p0改为r0后变成了大图目录的地址,
bigpicture = finder
[0].replace('photo/p0','photo/r0')
newimg = requests.get(bigpicture)
#替换掉无关的字符串
temp = imgfinder[imglen].replace('<p class="title" title="','')
newfinder = re.search(picpattern, finder
[0])
#截取title
temp = "G:/github/WebSpider_Python/img/"+temp[0:len(temp)-1]+'.jpg'
#下载文件,超级简单 设定好目录 content的意义也在于这里
with open(temp,'wb') as newfile:
newfile.write(newimg.content)
imglen = imglen+1
先上代码,其实爬虫这东西的文章,很多跨度太大,但是要给自己信心,不要别人可以爬的你也可以,看了一些基本的之后,自己动手写才是最重要的。我在这里写这篇,也是给个思路那样。
其实爬了首页之后,发现就那么几张图片。当你你鼠标往下拉,会自动加载东西。所以,万能的抓包出现了,和wireshark抓包不同的是,wireshark抓的包比较详细,包括tcp三次握手等等,嗯,前辈跟我说的,它带有很多路由信息。我们只需要分析http请求,所以chrome自带的调试工具,足矣。
按下F12。往下拉,然后请求都会被捕获。
现在想想我想起了以前面试的时候面试官问我的东西,get和post的区别,我答的是get提交的数据会被捕捉到,post不会,想想当时懂的还是不多。
不过学习中也找到了问题的答案。
从捕获的东西上看出,网站后台用了.net。然后post了这些参数。
再看看js文件。
其实从这里我发现到和我写的系统惊人的相似,这就是前后端分离的结果。
前端可以写的完全一模一样,但是后台可以使用.net,也可以使用java。嗯,用requests模拟请求这个,得到的是:
{ "TableInfo":[ { "id":"1123130","FilePath":"141118-121609-fVwIzH.jpg","userid":"974767",
"title":"%e4%b8%8d%e8%8a%b1%e9%92%b1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
"Height":"255","UserName":"广州合丰","headpic":"default.jpg"},
{ "id":"1123129","FilePath":"141118-121233-LxISqc.jpg","userid":"974767",
"title":"%e5%8d%93%e8%b6%8a%e6%b2%83%e6%9c%8d%e5%8a%a1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
"Height":"1374","UserName":"广州合丰","headpic":"default.jpg"}]}
字典里面TableInfo的值是列表,列表中的每个值又是字典,title是url编码后的中文,FilePathe就是图片路径。
返回后的json串通过js的处理后拼接,再放入到前面那个页面的div里面,做到滚动显示。
其实基本的玩法也就是这样,嗯,我还被前辈批实战经验不足,确实要多搞搞才行。
python代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author: iaiti
# @Date: 2015-11-18 10:41:10
# @Last Modified by: Administrator
# @Last Modified time: 2015-11-19 14:55:01
import re
import requests
import sys
import json
from urllib import unquote
reload(sys)
sys.setdefaultencoding('utf-8')
#获取到匹配字符的字符串
def find(pattern,test):
finder = re.search(pattern, test)
start = finder.start()
end = finder.end()
return test[start:end-1]
#大图的网址为r0 小图为p0
picturepath = 'http://zonepic.quanjing.com/photo/r0/'
#循环发送ajax请求 捉取大量图片
# for x in xrange(100,200):
#ajax采用post请求,通过抓包可以看出具体请求的参数
#http://zone.quanjing.com/share/design/ post参数为此url下下拉加载ajax请求所需要的参数
formdata = {'pageindex':'','pagesize':'25','keywords':'','arttype':'7','isgame':''}
#批量获取时,pageindex
#formdata['pageindex'] = x
formdata['pageindex'] = 2
#模拟post请求
circle = requests.post("http://zone.quanjing.com/share/ashx/WaterFallShowAsync.ashx",data=formdata)
#匹配后缀为jpg和png的链接
pattern = "(http:[^\s]*?(jpg|png))"
finder = re.findall(pattern, circle.text)
# 字典里面TableInfo的值是列表,列表中的每个值又是字典,title是url编码后的中文,FilePathe就是图片路径
# { "TableInfo":[ { "id":"1123130","FilePath":"141118-121609-fVwIzH.jpg","userid":"974767",
# "title":"%e4%b8%8d%e8%8a%b1%e9%92%b1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
# "Height":"255","UserName":"广州合丰","headpic":"default.jpg"},
# { "id":"1123129","FilePath":"141118-121233-LxISqc.jpg","userid":"974767",
# "title":"%e5%8d%93%e8%b6%8a%e6%b2%83%e6%9c%8d%e5%8a%a1%e7%b3%bb%e5%88%97%e6%b5%b7%e6%8a%a5",
# "Height":"1374","UserName":"广州合丰","headpic":"default.jpg"}]}
print circle.text
#json串转字典,获取TableInfo的值
mydict = json.loads(circle.text)
tablekey = mydict['TableInfo']
#print tablekey
#由于http://zonepic.quanjing.com/photo/p0/151112/151112-040832-zxe6fZ.jpg p0后面的
#文件夹命名为图片前面的数字命名,所以匹配此字符串
secondfile = '.*?-'
print len(tablekey)
#遍历列表
for keyarray in tablekey:
print str(keyarray['title'])
#中文title的url解码
imgfilename =unquote(str(keyarray['title'])).decode('utf8')
#由于要把标题当做文件名,但是文件名不能包含*<>/\:这些特殊字符
imgfilename =imgfilename.replace('>', '').replace('*', '').replace('<', '').replace('/', '').replace(':', '').replace('\\', '').replace('|', '')
imgnametemp = "G:/github/WebSpider_Python/img/"+imgfilename+".jpg"
print imgfilename
filepath = keyarray['FilePath']
print filepath
print picturepath+find(secondfile,keyarray['FilePath'])+'/'+keyarray['FilePath']
#requests请求图片地址
newimg = requests.get(picturepath+find(secondfile,keyarray['FilePath'])+'/'+keyarray['FilePath'])
with open(imgnametemp,'wb') as newfile:
#获取图片内容并往磁盘写入,命名为匹配的中文title名加上后缀
newfile.write(newimg.content)
这样,我跟我同事完美地交了差,同时吐槽他这网站很多图片没有标题。
上面的代码有些写得不符合规范,也没有用到多线程去捉取,解析html也没有用Beautiful soup这些。后面慢慢补上。
这个东西写完之后,找回了很多东西。

相关文章推荐
- Python基础(函数)
- 第一个python实例
- python切片
- python开源项目目录结构参考
- 流程控制练习*找奇数-求和-求积
- python里的map和reduce
- python学习笔记
- ---Maya&Python---001---
- Python基础学习-MySQL与Python结合
- Python 基础知识学习
- Python循环语句
- python模版
- python中文处理
- Python Queue模块详解
- python 双端队列 deque
- python 多进程共享变量
- python的pip命令常用操作
- python自然语言之nlck环境搭建初步
- 《用Python玩转数据》学习笔记第3周Part2
- 删除或查找特定时间范围的后缀文件(python)