使用Python 2.7实现的垃圾短信识别器
2015-11-18 16:59
666 查看
最近参加比赛,写了一个垃圾短信识别器,在这里做一下记录。
官方提供的数据是csv文件,其中训练集有80万条数据,测试集有20万条数据,训练集的格式为:行号 标记(0为普通短信,1为垃圾短信) 短信内容;测试集的格式为: 行号 短信内容;要求输出的数据格式要求为: 行号 标记,以csv格式保存。
实现的原理可概括为以下几步:
1.读取文件,输入数据
2.对数据进行分割,将每一行数据分成行号、标记、短信内容。由于短信内容中可能存在空格,故不能简单地用split()分割字符串,应该用正则表达式模块re进行匹配分割。
3.将分割结果存入数据库(MySQL),方便下次测试时直接从数据库读取结果,省略步骤。
4.对短信内容进行分词,这一步用到了第三方库结巴分词:https://github.com/fxsjy/jieba
5.将分词的结果用于训练模型,训练的算法为朴素贝叶斯算法,可调用第三方库Scikit-Learn:http://scikit-learn.org/stable
6.从数据库中读取测试集,进行判断,输出结果并写入文件。
最终实现出来一共有4个py文件:
1.ImportIntoDB.py 将数据进行预处理并导入数据库,仅在第一次使用。
2.DataHandler.py 从数据库中读取数据,进行分词,随后处理数据,训练模型。
3.Classifier.py 从数据库中读取测试集数据,利用训练好的模型进行判断,输出结果到文件中。
4.Main.py 程序的入口
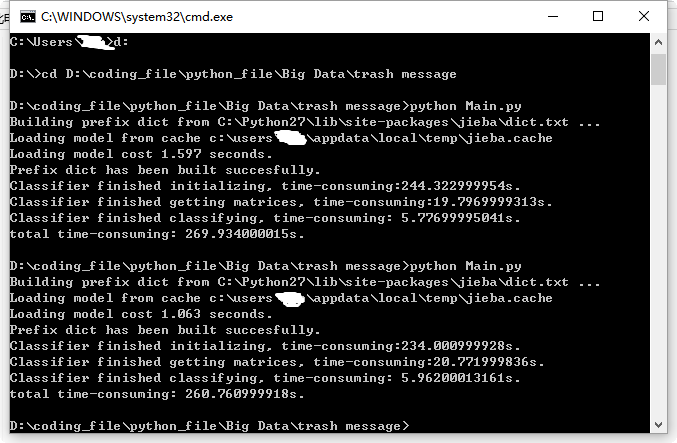
最终程序每次运行耗时平均在260秒-270秒之间,附代码:
ImportIntoDB.py:
DataHandler.py:
Classifier.py:
Main.py:
官方提供的数据是csv文件,其中训练集有80万条数据,测试集有20万条数据,训练集的格式为:行号 标记(0为普通短信,1为垃圾短信) 短信内容;测试集的格式为: 行号 短信内容;要求输出的数据格式要求为: 行号 标记,以csv格式保存。
实现的原理可概括为以下几步:
1.读取文件,输入数据
2.对数据进行分割,将每一行数据分成行号、标记、短信内容。由于短信内容中可能存在空格,故不能简单地用split()分割字符串,应该用正则表达式模块re进行匹配分割。
3.将分割结果存入数据库(MySQL),方便下次测试时直接从数据库读取结果,省略步骤。
4.对短信内容进行分词,这一步用到了第三方库结巴分词:https://github.com/fxsjy/jieba
5.将分词的结果用于训练模型,训练的算法为朴素贝叶斯算法,可调用第三方库Scikit-Learn:http://scikit-learn.org/stable
6.从数据库中读取测试集,进行判断,输出结果并写入文件。
最终实现出来一共有4个py文件:
1.ImportIntoDB.py 将数据进行预处理并导入数据库,仅在第一次使用。
2.DataHandler.py 从数据库中读取数据,进行分词,随后处理数据,训练模型。
3.Classifier.py 从数据库中读取测试集数据,利用训练好的模型进行判断,输出结果到文件中。
4.Main.py 程序的入口
最终程序每次运行耗时平均在260秒-270秒之间,附代码:
ImportIntoDB.py:
# -*- coding:utf-8 -*- __author__ = 'Jz' import MySQLdb import codecs import re import time # txt_path = 'D:/coding_file/python_file/Big Data/trash message/train80w.txt' txt_path = 'D:/coding_file/python_file/Big Data/trash message/test20w.txt' # use regular expression to split string into parts # split_pattern_80w = re.compile(u'([0-9]+).*?([01])(.*)') split_pattern_20w = re.compile(u'([0-9]+)(.*)') txt = codecs.open(txt_path, 'r') lines = txt.readlines() start_time = time.time() #connect mysql database con = MySQLdb.connect(host = 'localhost', port = 3306, user = 'root', passwd = '*****', db = 'TrashMessage', charset = 'UTF8') cur = con.cursor() # insert into 'train' table # sql = 'insert into train(sms_id, sms_type, content) values (%s, %s, %s)' # for line in lines: # match = re.match(split_pattern_80w, line) # sms_id, sms_type, content = match.group(1), match.group(2), match.group(3).lstrip() # cur.execute(sql, (sms_id, sms_type, content)) # print sms_id # # commit transaction # con.commit() # insert into 'test' table sql = 'insert into test(sms_id, content) values (%s, %s)' for line in lines: match = re.match(split_pattern_20w, line) sms_id, content = match.group(1), match.group(2).lstrip() cur.execute(sql, (sms_id, content)) print sms_id # commit transaction con.commit() cur.close() con.close() txt.close() end_time = time.time() print 'time-consuming: ' + str(end_time - start_time) + 's.'
DataHandler.py:
# -*- coding:utf-8 -*- __author__ = 'Jz' import MySQLdb import jieba import re class DataHandler: def __init__(self): try: self.con = MySQLdb.connect(host = 'localhost', port = 3306, user = 'root', passwd = '*****', db = 'TrashMessage', charset = 'UTF8') self.cur = self.con.cursor() except MySQLdb.OperationalError, oe: print 'Connection error! Details:', oe def __del__(self): self.cur.close() self.con.close() # obsolete function # def getConnection(self): # return self.con # obsolete function # def getCursor(self): # return self.cur def query(self, sql): self.cur.execute(sql) result_set = self.cur.fetchall() return result_set def resultSetTransformer(self, train, test): # list of words divided by jieba module after de-duplication train_division = [] test_division = [] # list of classification of each message train_class = [] # divide messages into words for record in train: train_class.append(record[1]) division = jieba.cut(record[2]) filtered_division_set = set() for word in division: filtered_division_set.add(word + ' ') division = list(filtered_division_set) str_word = ''.join(division) train_division.append(str_word) # handle test set in a similar way as above for record in test: division = jieba.cut(record[1]) filtered_division_set = set() for word in division: filtered_division_set.add(word + ' ') division = list(filtered_division_set) str_word = ''.join(division) test_division.append(str_word) return train_division, train_class, test_division
Classifier.py:
# -*- coding:utf-8 -*-
__author__ = 'Jz'
from DataHandler import DataHandler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
import time
class Classifier:
def __init__(self):
start_time = time.time()
self.data_handler = DataHandler()
# get result set
self.train = self.data_handler.query('select * from train')
self.test = self.data_handler.query('select * from test')
self.train_division, self.train_class, self.test_division = self.data_handler.resultSetTransformer(self.train, self.test)
end_time = time.time()
print 'Classifier finished initializing, time-consuming:' + str(end_time - start_time) + 's.'
def getMatrices(self):
start_time = time.time()
# convert a collection of raw documents to a matrix of TF-IDF features.
self.tfidf_vectorizer = TfidfVectorizer()
# learn vocabulary and idf, return term-document matrix [sample, feature]
self.train_count_matrix = self.tfidf_vectorizer.fit_transform(self.train_division)
# transform the count matrix of the train set to a normalized tf-idf representation
self.tfidf_transformer = TfidfTransformer()
self.train_tfidf_matrix = self.tfidf_transformer.fit_transform(self.train_count_matrix)
end_time = time.time()
print 'Classifier finished getting matrices, time-consuming:' + str(end_time - start_time) + 's.'
def classify(self):
self.getMatrices()
start_time = time.time()
# convert a collection of text documents to a matrix of token counts
# scikit-learn doesn't support chinese vocabulary
test_tfidf_vectorizer = CountVectorizer(vocabulary = self.tfidf_vectorizer.vocabulary_)
# learn the vocabulary dictionary and return term-document matrix.
test_count_matrix = test_tfidf_vectorizer.fit_transform(self.test_division)
# transform a count matrix to a normalized tf or tf-idf representation
test_tfidf_transformer = TfidfTransformer()
test_tfidf_matrix = test_tfidf_transformer.fit(self.train_count_matrix).transform(test_count_matrix)
# the multinomial Naive Bayes classifier is suitable for classification with discrete features
# e.g., word counts for text classification).
naive_bayes = MultinomialNB(alpha = 0.65)
naive_bayes.fit(self.train_tfidf_matrix, self.train_class)
prediction = naive_bayes.predict(test_tfidf_matrix)
# output result to a csv file
index = 0
csv = open('result.csv', 'w')
for sms_type in prediction:
csv.write(str(self.test[index][0]) + ',' + str(sms_type) + '\n')
index += 1
csv.close()
end_time = time.time()
print 'Classifier finished classifying, time-consuming: ' + str(end_time - start_time) + 's.'Main.py:
# -*- coding:utf-8 -*- __author__ = 'Jz' import time from Classifier import Classifier start_time = time.time() classifier = Classifier() classifier.classify() end_time = time.time() print 'total time-consuming: ' + str(end_time - start_time) + 's.'

相关文章推荐
- python用requests请求百度接口报“SSL: CERTIFICATE_VERIFY_FAILED”
- Python学习指南
- python3输出unicode
- Python中list的实现
- Python处理Json报文
- 【python】class之子类
- python 抽象类、抽象方法的实现
- 安装python MySQLdb报错:pymemcompat.h:10:20: 致命错误的解决
- scikit学习心得——Isotonic Regression
- Python编写微信打飞机小游戏(十二)
- Difference between Range and Xrange in Python
- 折腾Ipython
- 第一个Python程序——博客自动访问脚本
- Python基础学习-爬虫小试2
- python插件
- Python学习小记
- 让cherrypy监听系统内所有活动网卡传入的请求
- python 远程操作ubuntu
- Python 创建函数和代码重用
- python数据类型详解