Modeling Video Evolution For Action Recognition - cvpr - 2015
2015-11-13 18:59
288 查看
Modeling Video Evolution
For Action Recognition - cvpr - 2015
论文题目Modeling Video Evolution For Action Recognition, 链接
该篇论文是CVPR 2015的, 文章的核心是feature descriptors的获取.
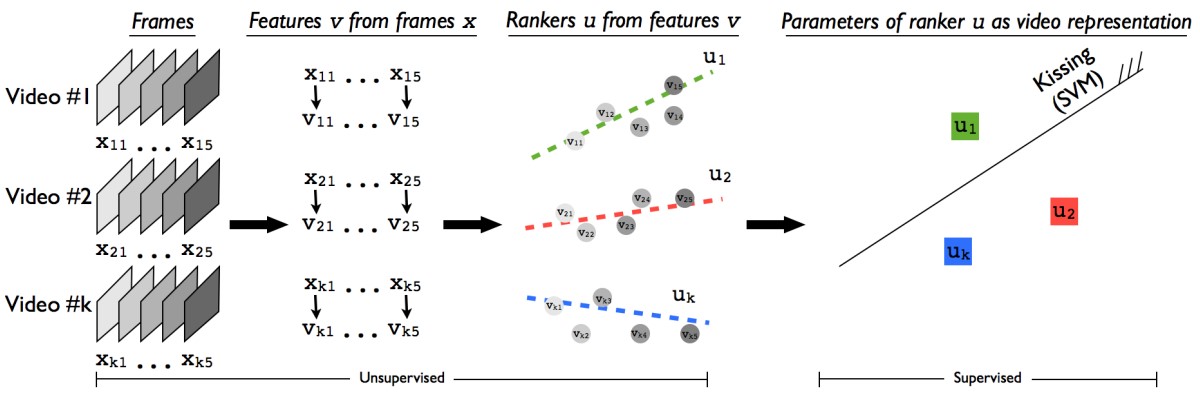
直接看图说话:
该论文的核心思想/步骤是:
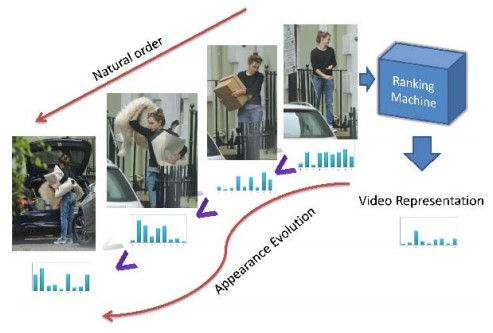
1 利用一些现有的feature来表征video每帧的, 如论文里的Xi, 利用时间因子t来进一步提取特征, 如论文里的Xt, 用来表征video的appearance和motion的evolution.
这里的Xt的计算比较有意思, 值得参考.
2 基于这样的假设: evolution over time t可以表征video的action信息, 也就是越往后的帧对于action来说,
越具有判别性. 训练一个ranking function.
即学习video里的{Xt}的order relationship.
论文里面提到ranking function是unsurpervised的, 也就是ranking的label是隐式给出的, 即上面的假设;

基于这样的数据, 训练一个rankSVM的ranking function/machine.
(当然这里可以是任意线性的ranking function)
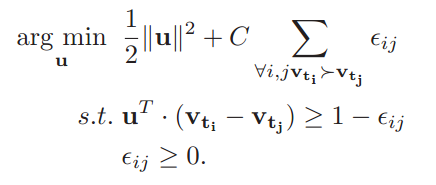
这些ranking function/machine学习到evolution如下图所示
3 将训练好的ranking function/machine的参数向量作为video的representation Ui.
4 {Ui, Yi}作为action classification的数据集, 训练non-linear svm的action classifiers, 对action进行分类.
总的来说, 个人觉得该论文的亮点是:
1 不同于以往的特征, 如HOG, HOF, MBH等, 用ranking function/machine的参数向量作为video的representation, 这个比较有意思.
2 不论是ranking funciton还是classification的svm, 都容易重现.
3 论文中的Xt的计算, 简单有效.
但是还是有不足之处的:
1 每个视频都需要单独训练一个ranking function/machine, 这个不适合online.
2 ranking的order label的假设是有缺陷的, 即
是不合理的. (大家想想为什么?)
3 整个流程还是非常pipeline的.
好吧, 不会吐槽, 莫怪, 莫怪.
欢迎前来骚扰...
For Action Recognition - cvpr - 2015
论文题目Modeling Video Evolution For Action Recognition, 链接
该篇论文是CVPR 2015的, 文章的核心是feature descriptors的获取.
直接看图说话:
该论文的核心思想/步骤是:
1 利用一些现有的feature来表征video每帧的, 如论文里的Xi, 利用时间因子t来进一步提取特征, 如论文里的Xt, 用来表征video的appearance和motion的evolution.
这里的Xt的计算比较有意思, 值得参考.
2 基于这样的假设: evolution over time t可以表征video的action信息, 也就是越往后的帧对于action来说,
越具有判别性. 训练一个ranking function.
即学习video里的{Xt}的order relationship.
论文里面提到ranking function是unsurpervised的, 也就是ranking的label是隐式给出的, 即上面的假设;
基于这样的数据, 训练一个rankSVM的ranking function/machine.
(当然这里可以是任意线性的ranking function)
这些ranking function/machine学习到evolution如下图所示
3 将训练好的ranking function/machine的参数向量作为video的representation Ui.
4 {Ui, Yi}作为action classification的数据集, 训练non-linear svm的action classifiers, 对action进行分类.
总的来说, 个人觉得该论文的亮点是:
1 不同于以往的特征, 如HOG, HOF, MBH等, 用ranking function/machine的参数向量作为video的representation, 这个比较有意思.
2 不论是ranking funciton还是classification的svm, 都容易重现.
3 论文中的Xt的计算, 简单有效.
但是还是有不足之处的:
1 每个视频都需要单独训练一个ranking function/machine, 这个不适合online.
2 ranking的order label的假设是有缺陷的, 即
是不合理的. (大家想想为什么?)
3 整个流程还是非常pipeline的.
好吧, 不会吐槽, 莫怪, 莫怪.
欢迎前来骚扰...

相关文章推荐
- DVI 视频接口图文解析
- C#实现语音视频录制-附demo源码
- C#调用mmpeg进行各种视频转换的类实例
- C#获取视频某一帧的缩略图的方法
- 显示youtube视频缩略图和Vimeo视频缩略图代码分享
- PHP使用ffmpeg给视频增加字幕显示的方法
- PHP实现将视频转成MP4并获取视频预览图的方法
- C++实现优酷土豆去视频广告的方法
- PHP简单获取视频预览图的方法
- asp.net 页面中添加普通视频的几种方式介绍
- Android获取SD卡上图片和视频缩略图的小例子
- php使用memcoder将视频转成mp4格式的方法
- 基于js与flash实现的网站flv视频播放插件代码
- java调用ffmpeg实现视频转换的方法
- js+HTML5基于过滤器从摄像头中捕获视频的方法
- python+ffmpeg视频并发直播压力测试
- 用Python的Django框架完成视频处理任务的教程
- Android使用MediaRecorder类进行录制视频
- Nginx搭建流媒体FLV视频服务器配置示例
- [总结]视频质量评价技术零基础学习方法