Spark - 大数据Big Data处理框架
2015-11-10 09:13
323 查看
Spark是一个针对超大数据集合的低延迟的集群分布式计算系统,比MapReducer快40倍左右。
Spark是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。
Spark兼容Hadoop的APi,能够读写Hadoop的HDFS HBASE 顺序文件等。
传统Hadoop如下图 性能慢原因有:磁盘IO 复制和序列化等等,涉及图中的HDFS
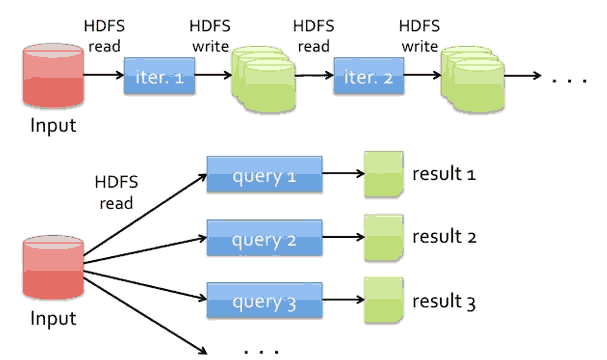
而在Spark中,使用内存替代了使用HDFS存储中间结果:

Spark架构图

弹性的分布数据集(RDD) :分布式对象集合能够跨集群在内存中保存。多个并行操作,失败自动恢复。
使用内存集群计算, 内存访问要比磁盘快得多。有Scala Java Python API,能够从Scala和Python访问。
下面是一个简单的对日志log计数的代码:
/*** SimpleJob.scala ***/
import spark.SparkContext
import SparkContext._
object SimpleJob {
def main(args: Array[String]) {
val logFile = "/var/log/syslog" // Should be some file on your system
val sc = new SparkContext("local", "Simple Job", "$YOUR_SPARK_HOME",
List("target/scala-2.9.3/simple-project_2.9.3-1.0.jar"))
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
运行原理图:
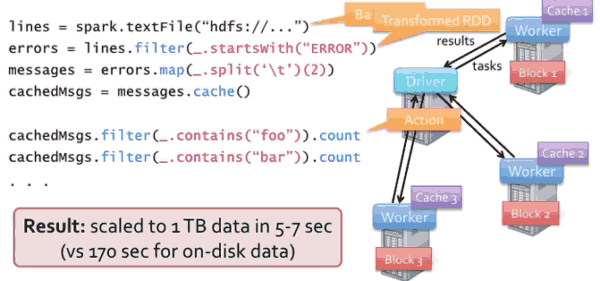
当进行filter操作是,是一种transformed RDD,RDD跟踪这种转换,当有数据丢失失败时,重新计算 得到这个数据。
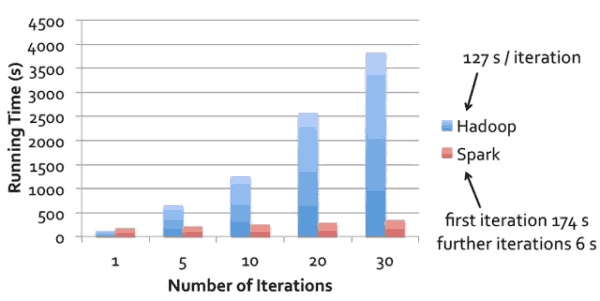
Spark支持物流logistic表达式,如下图:

物流表达式相比Hadoop的遍历性能:
支持以下数据分析操作:

以推流方式处理数据:

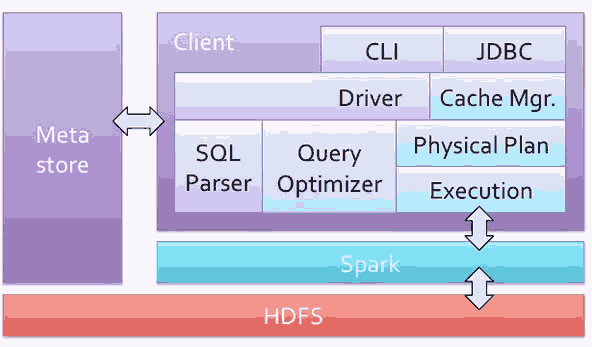
Shark是基于Spark上的“Hive”,看看基于hadoop的Hive:
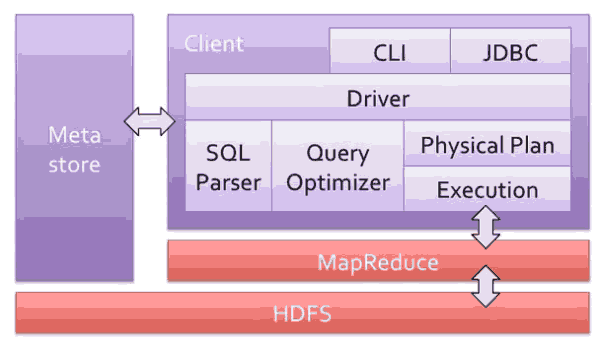
而Shark的结构图:
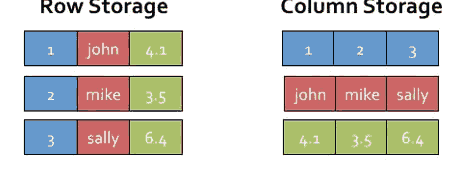
Hive是记录每行记录一个对象,而shark是每列记录:
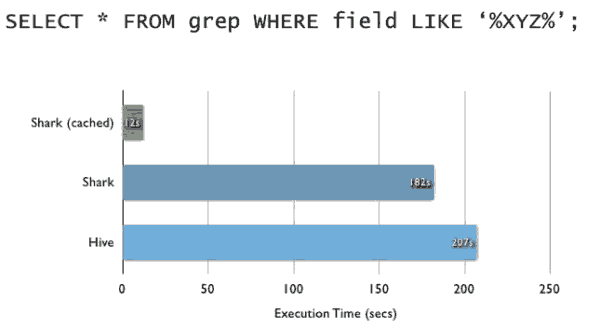
执行SQL时间对比:
Spark是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。
Spark兼容Hadoop的APi,能够读写Hadoop的HDFS HBASE 顺序文件等。
传统Hadoop如下图 性能慢原因有:磁盘IO 复制和序列化等等,涉及图中的HDFS
而在Spark中,使用内存替代了使用HDFS存储中间结果:
Spark架构图
Spark的编程模型
弹性的分布数据集(RDD) :分布式对象集合能够跨集群在内存中保存。多个并行操作,失败自动恢复。使用内存集群计算, 内存访问要比磁盘快得多。有Scala Java Python API,能够从Scala和Python访问。
下面是一个简单的对日志log计数的代码:
/*** SimpleJob.scala ***/
import spark.SparkContext
import SparkContext._
object SimpleJob {
def main(args: Array[String]) {
val logFile = "/var/log/syslog" // Should be some file on your system
val sc = new SparkContext("local", "Simple Job", "$YOUR_SPARK_HOME",
List("target/scala-2.9.3/simple-project_2.9.3-1.0.jar"))
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
运行原理图:
当进行filter操作是,是一种transformed RDD,RDD跟踪这种转换,当有数据丢失失败时,重新计算 得到这个数据。
Spark支持物流logistic表达式,如下图:
物流表达式相比Hadoop的遍历性能:
支持以下数据分析操作:
Spark流处理
以推流方式处理数据:
Shark
Shark是基于Spark上的“Hive”,看看基于hadoop的Hive:而Shark的结构图:
Hive是记录每行记录一个对象,而shark是每列记录:
执行SQL时间对比:

相关文章推荐
- 流式大数据处理的三种框架:Storm,Spark和Samza
- Cloud Design Pattern - Health Endpoint Monitoring(健康端点监测)
- 大数据培训
- usaco.section1.3.Barn Repair
- 数据引擎-阿里开源引擎OceanBase
- Last Daily Scrum (2015/11/9)
- DT大数据梦工厂,王家林老师的大数据全集
- LightOJ - 1417 Forwarding Emails(强连通+dfs)
- 如何写好 C main 函数
- LightOJ - 1086 Jogging Trails(欧拉+状态压缩)
- 【Alpha】Daily Scrum Meeting第七次
- 【Alpha】Daily Scrum Meeting第七次
- 处理大数据的四个步骤
- TinyOS06:Avrora的Mailing List
- poj 2010 Moo University - Financial Aid 优先队列
- fibonacci && climbing-stairs
- 转发Spark亚太研究院院长王家林大数据和云计算学习视频
- 你是探索者,还是归客?用大数据说话
- 数据库大数据访问的解决方法
- LightOJ 1021 - Painful Bases(dp)