Linux虚拟地址空间概述
2015-11-10 00:12
405 查看
原文:
http://my.oschina.net/u/1770090/blog/263326
1 虚拟地址空间概述
Linux进程虚拟地址空间是linux内存管理一个重要的部分,我们知道,在IA-32系统上地址空间的范围可达2的32次幂=4G,总的地址空间通常按3:1的比例划分,用户态占用了3G,内核占用了1G。
各进程的用户态虚拟地址空间起始于地址0,延伸到TASK_SIZE -1的位置,其上是内核的地址空间。
无论当前的那个用户进程处于运行状态,虚拟地址空间的内核部分总是相同的。如下图所示:

2 用户态地址空间
虚拟地址空间有不同的段组成,分布方式是特定于体系结构的,但所有方法都有下列共同成分。
在IA-32架构中,Linux传统内存空间布局如下:
--芯片寄存器的虚拟地址也应该在内核地址1GB范围内吧,是不是还应该在0XF8000000之上?(我注释)
--内核有stack,用户也有stack

2.1 各段的说明
TEXT:代码段,映射程序的二进制代码, 该区域为私有区域;在代码段中,也会包含一些只读的常数变量,比如字符串常量等。
一般来说,IA-32体系结构中进程空间的代码段从0x08048000开始,这与最低可用地址(0x00000000)有128M的间距,按照linux内核架构一书介绍是为了捕获NULL指针(具体不详)。该值是在编译阶段就已经设定好的,其他体系结构也有类似的缺口,比如mips(), ppc() x86-64使用的是0x000000000400000(只4MB了)。
DATA:数据段,映射程序中已经初始化的全局变量。
BSS段:存放程序中未初始化的全局变量,在ELF文件中,该区域的变量仅仅是个符号,并不占用文件空间,但程序加载后,会占用内存空间,并初始化为0。
HEAP:运行时的堆,在程序运行中使用malloc申请的内存区域。
该区域的起始地址受start_brk影响,和BSS段之间会有一个随机值的空洞;该区域的内存增长方式是由低地址向高地址增长。
MMAP:共享库及匿名文件的映射区域;该区域中会包含共享库的代码段和数据段。其中代码段为共享的,但数据段为私有的,写时拷贝。
该区域起始地址也会有一个随机值,该区域的增长方式是从高地址向低地址增长(Linux经典布局中不同,稍后讨论)
STACK:用户进程栈;
该区域起始地址也存在一个随机值,通过PF_RANDOMIZE来设置。栈的增长方向是由高地址向低地址增长,并且若设置了RLIMIT_STACK即规定了栈的大小。
最后,是命令行参数和环境变量。
2.2 布局说明
Linux经典内存布局和新布局不同
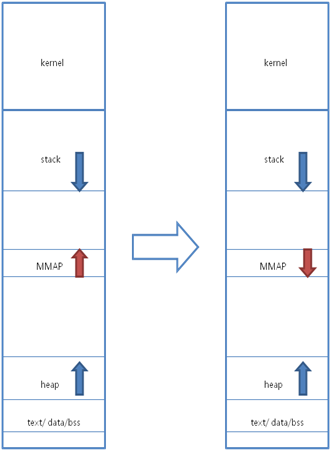
从以上图对比可以发现,不同之处在于MMAP区域的增长方向,新布局导致了栈空间的固定,而堆区域和MMAP区域公用一个空间,这在很大程度上增长了堆区域的大小。
那么为什么这么做呢?使用经典布局在32位计算机上,TASK_UNMMAPPED_BASE在IA-32中只有0x40000000(固定了害死人呢),也就是说对空间只有1G空间可用(包括malloc),堆超过了可用空间,继续增长会进入MMAP区域。在2.6.7内核开始,为IA-32引入了新的虚拟地址空间的布局(经典布局仍然可用)。
布局的选择,如果用户通过/proc/sys/kernel/legacy_va_layout给出明确指示,或者要执行的二进制文件为unix变体编译需要旧的布局,或者栈可以无限制增长,则系统就会选择旧的布局。
如果选择新的布局时,内存增长是有高地址向低地址,那MMAP的起始地址从什么地方开始的?可以使用栈的最大长度来计算栈最低的可能位置,作为MMAP的基址。但内核也会确保栈至少跨越128M空间。如果指定了栈的界限非常大,那内核也会至少保留一部分地址空间不会被栈占据。通常要求地址空间的随机化,上述位置会再减去一个偏移量,最大为1M。
64位系统上堆虚拟地址空间总是使用经典布局。
2.3 随机化问题
在以上的描述中提到堆/栈/MMAP的随机化问题,那么为什么需要随机化呢? 如果所有的进程都按照设定的默认值,攻击者很容易就知道栈和库函数的地址。
3 内核态地址空间
3.1 内核在物理内存的布局
Linux的内核在初始化时会加载到内存区的固定位置(在此我们不讨论可重定位内核的情况),而内核所占用的内存区域的布局是固定的,如图所示:

内存的第一个页不使用,通常保留给BIOS使用,接下来的640K原则上是可用的,但也不会加载内核代码,因为系统用于各种ROM(BIOS和显卡ROM)的映射。再之后的空间也是闲置的,原因是内核需要被放到连续的内存中;所以从0x100000(1MB)作为内核代码的起始地址。
3.2 各段的说明
内核占据的内存也分为几个段:
_text和_etext是代码段的起始和终止位置
_etext到_edata之间是数据段,保存了大部分的内核变量
_edata到_end之间,是初始化为0的所有静态全局变量的BSS段。
以上的信息可以通过cat /proc/iomem来查看,不同cpu体系有不同的情况。
3.3 由物理地址到虚拟地址的转换
IA-32架构可以访问4G的地址空间,通常会将线性地址空间划分为3:1的两个部分:用户态使用3G,内核态使用1G,即内核空间从0xC0000000开始,每个虚拟地址x都对应于物理地址x-0xC0000000。这样的设计可以加快内核空间的寻址速度(简单的减法操作)。在进程切换的过程中,只有用户态对应的页表被切换,高地址空间会公用内核页表。
3.4 高端内存的情况
IA-32架构的这种设计也存在这样的一个问题:既然内核只能处理1G的空间(实际上内核直接处理的空间还不足1G),那么物理内存大于1G,剩下的内存将如何处理呢?这种情况下内核无法直接映射全部的物理内存,这样就会用到高端内存区域的概念了(ZONE_HIGHMEM)。具体的内存分配如下图:

由以上的图可以看到,内核区域的映射从_PAGE_OFFSE(0xC0000000)开始,即3G的位置开始映射到4G的区域,开始的一段用于直接映射,后而的128M为vmalloc使用的空间,再之后会有永久映射和固定映射区。所以事实上,物理内存能够直接映射到内核的空间=1G-vmalloc-永久映射-固定映射,真正的空间大约只剩下850M,也就是说,物理内存中只有850M是可以映射到内核空间的,对于超过的部分来说,作为高端内存使用。
3.5 疑问一
这里会存在一个疑问:如果内存只能处理896M的空间,那么如果内存很大比如(3G),那剩下的内存怎么办?对于这个问题,我们需要注意的是,1.这里讲述的内存是内核直接映射的物理内存,对于高地址的内存内核还有另外一套机制来管理;2.用户空间对物理内存的访问不是通过直接映射,还有另外一套机制。
3.6 疑问二
还有一个疑问:既然内核直接映射了将近1G的内存,那么如果我们有3G的物理内存,是不是只有2G多一点的内存可使用了呢?这个说法是错误的,上图所描述的只是内核在线性地址空间的分布情况,物理内存分配的过程中(用户态进程申请的内存,vmalloc部分的内存等),更倾向于先分配高地址的内存,在高地址内存耗尽的情况下,才会使用低850M的内存。
4 虚拟地址空间的访问权限

1. 用户空间禁止访问内核空间。
2. 用户态通过系统调用切换到内核空间后,该进程处于内核态上下文,可以访问用户空间的内存。
3. 中断抢占进程后,处于中断上下文时,不能访问用户空间。
4. 内核线程不能访问用户空间。
第一篇就先写到这里,可能也会有理解不太准确的地方,后续也会据此继续更新,希望使该篇文章保持准确性。
http://my.oschina.net/u/1770090/blog/263326
1 虚拟地址空间概述
Linux进程虚拟地址空间是linux内存管理一个重要的部分,我们知道,在IA-32系统上地址空间的范围可达2的32次幂=4G,总的地址空间通常按3:1的比例划分,用户态占用了3G,内核占用了1G。
各进程的用户态虚拟地址空间起始于地址0,延伸到TASK_SIZE -1的位置,其上是内核的地址空间。
无论当前的那个用户进程处于运行状态,虚拟地址空间的内核部分总是相同的。如下图所示:
2 用户态地址空间
虚拟地址空间有不同的段组成,分布方式是特定于体系结构的,但所有方法都有下列共同成分。
在IA-32架构中,Linux传统内存空间布局如下:
--芯片寄存器的虚拟地址也应该在内核地址1GB范围内吧,是不是还应该在0XF8000000之上?(我注释)
--内核有stack,用户也有stack
2.1 各段的说明
TEXT:代码段,映射程序的二进制代码, 该区域为私有区域;在代码段中,也会包含一些只读的常数变量,比如字符串常量等。
一般来说,IA-32体系结构中进程空间的代码段从0x08048000开始,这与最低可用地址(0x00000000)有128M的间距,按照linux内核架构一书介绍是为了捕获NULL指针(具体不详)。该值是在编译阶段就已经设定好的,其他体系结构也有类似的缺口,比如mips(), ppc() x86-64使用的是0x000000000400000(只4MB了)。
DATA:数据段,映射程序中已经初始化的全局变量。
BSS段:存放程序中未初始化的全局变量,在ELF文件中,该区域的变量仅仅是个符号,并不占用文件空间,但程序加载后,会占用内存空间,并初始化为0。
HEAP:运行时的堆,在程序运行中使用malloc申请的内存区域。
该区域的起始地址受start_brk影响,和BSS段之间会有一个随机值的空洞;该区域的内存增长方式是由低地址向高地址增长。
MMAP:共享库及匿名文件的映射区域;该区域中会包含共享库的代码段和数据段。其中代码段为共享的,但数据段为私有的,写时拷贝。
该区域起始地址也会有一个随机值,该区域的增长方式是从高地址向低地址增长(Linux经典布局中不同,稍后讨论)
STACK:用户进程栈;
该区域起始地址也存在一个随机值,通过PF_RANDOMIZE来设置。栈的增长方向是由高地址向低地址增长,并且若设置了RLIMIT_STACK即规定了栈的大小。
最后,是命令行参数和环境变量。
2.2 布局说明
Linux经典内存布局和新布局不同
从以上图对比可以发现,不同之处在于MMAP区域的增长方向,新布局导致了栈空间的固定,而堆区域和MMAP区域公用一个空间,这在很大程度上增长了堆区域的大小。
那么为什么这么做呢?使用经典布局在32位计算机上,TASK_UNMMAPPED_BASE在IA-32中只有0x40000000(固定了害死人呢),也就是说对空间只有1G空间可用(包括malloc),堆超过了可用空间,继续增长会进入MMAP区域。在2.6.7内核开始,为IA-32引入了新的虚拟地址空间的布局(经典布局仍然可用)。
布局的选择,如果用户通过/proc/sys/kernel/legacy_va_layout给出明确指示,或者要执行的二进制文件为unix变体编译需要旧的布局,或者栈可以无限制增长,则系统就会选择旧的布局。
如果选择新的布局时,内存增长是有高地址向低地址,那MMAP的起始地址从什么地方开始的?可以使用栈的最大长度来计算栈最低的可能位置,作为MMAP的基址。但内核也会确保栈至少跨越128M空间。如果指定了栈的界限非常大,那内核也会至少保留一部分地址空间不会被栈占据。通常要求地址空间的随机化,上述位置会再减去一个偏移量,最大为1M。
64位系统上堆虚拟地址空间总是使用经典布局。
2.3 随机化问题
在以上的描述中提到堆/栈/MMAP的随机化问题,那么为什么需要随机化呢? 如果所有的进程都按照设定的默认值,攻击者很容易就知道栈和库函数的地址。
3 内核态地址空间
3.1 内核在物理内存的布局
Linux的内核在初始化时会加载到内存区的固定位置(在此我们不讨论可重定位内核的情况),而内核所占用的内存区域的布局是固定的,如图所示:
内存的第一个页不使用,通常保留给BIOS使用,接下来的640K原则上是可用的,但也不会加载内核代码,因为系统用于各种ROM(BIOS和显卡ROM)的映射。再之后的空间也是闲置的,原因是内核需要被放到连续的内存中;所以从0x100000(1MB)作为内核代码的起始地址。
3.2 各段的说明
内核占据的内存也分为几个段:
_text和_etext是代码段的起始和终止位置
_etext到_edata之间是数据段,保存了大部分的内核变量
_edata到_end之间,是初始化为0的所有静态全局变量的BSS段。
以上的信息可以通过cat /proc/iomem来查看,不同cpu体系有不同的情况。
3.3 由物理地址到虚拟地址的转换
IA-32架构可以访问4G的地址空间,通常会将线性地址空间划分为3:1的两个部分:用户态使用3G,内核态使用1G,即内核空间从0xC0000000开始,每个虚拟地址x都对应于物理地址x-0xC0000000。这样的设计可以加快内核空间的寻址速度(简单的减法操作)。在进程切换的过程中,只有用户态对应的页表被切换,高地址空间会公用内核页表。
3.4 高端内存的情况
IA-32架构的这种设计也存在这样的一个问题:既然内核只能处理1G的空间(实际上内核直接处理的空间还不足1G),那么物理内存大于1G,剩下的内存将如何处理呢?这种情况下内核无法直接映射全部的物理内存,这样就会用到高端内存区域的概念了(ZONE_HIGHMEM)。具体的内存分配如下图:
由以上的图可以看到,内核区域的映射从_PAGE_OFFSE(0xC0000000)开始,即3G的位置开始映射到4G的区域,开始的一段用于直接映射,后而的128M为vmalloc使用的空间,再之后会有永久映射和固定映射区。所以事实上,物理内存能够直接映射到内核的空间=1G-vmalloc-永久映射-固定映射,真正的空间大约只剩下850M,也就是说,物理内存中只有850M是可以映射到内核空间的,对于超过的部分来说,作为高端内存使用。
3.5 疑问一
这里会存在一个疑问:如果内存只能处理896M的空间,那么如果内存很大比如(3G),那剩下的内存怎么办?对于这个问题,我们需要注意的是,1.这里讲述的内存是内核直接映射的物理内存,对于高地址的内存内核还有另外一套机制来管理;2.用户空间对物理内存的访问不是通过直接映射,还有另外一套机制。
3.6 疑问二
还有一个疑问:既然内核直接映射了将近1G的内存,那么如果我们有3G的物理内存,是不是只有2G多一点的内存可使用了呢?这个说法是错误的,上图所描述的只是内核在线性地址空间的分布情况,物理内存分配的过程中(用户态进程申请的内存,vmalloc部分的内存等),更倾向于先分配高地址的内存,在高地址内存耗尽的情况下,才会使用低850M的内存。
4 虚拟地址空间的访问权限
1. 用户空间禁止访问内核空间。
2. 用户态通过系统调用切换到内核空间后,该进程处于内核态上下文,可以访问用户空间的内存。
3. 中断抢占进程后,处于中断上下文时,不能访问用户空间。
4. 内核线程不能访问用户空间。
第一篇就先写到这里,可能也会有理解不太准确的地方,后续也会据此继续更新,希望使该篇文章保持准确性。

相关文章推荐
- linux如何安装jdk
- Linux下实现MySQL数据备份和恢复的命令使用全攻略
- Linux查看程序端口占用情况
- linux桌面环境应用
- CentOS7下安装python包管理工具pip
- linux 命令
- linux 默认的include
- centos上如何安装git
- 如何将arm-linux-gcc添加到自己用户的PATH路径里
- 在linode centos7 上安装 gitlab-ce
- 每天一个linux命令(2):wget命令
- linux命令英文缩写
- Linux文本处理三剑客之sed
- centos 7首次登录和常见命令
- Linux推荐书籍
- Linux下使用Tmux提高终端环境下的效率
- linux 安装nodejs
- 陈硕-Linux C++ 服务器端这条线怎么走?一年半能做出什么?
- Linux动态加载库的使用方法
- Linux内核(驱动)常用函数