Spark standalone集群安装
2015-11-08 22:52
435 查看
本文不会搞什么Yarn混搭Spark,只想建立一个纯粹的Spark环境便于起步阶段的学习理解。
smile帐号就是spark服务的运行帐号。
wget http://mirrors.cnnic.cn/apache/spark/spark-1.5.1/spark-1.5.1-bin-hadoop2.6.tgz 解压到下面的目录,并将owner和group设置成smile帐号,再建立链接。
wget http://mirrors.cnnic.cn/apache/spark/spark-1.5.1/spark-1.5.1-bin-hadoop2.6.tgz tar zxvf spark-1.5.1-bin-hadoop2.6.tgz
chown -R smile:smile spark-1.5.1-bin-hadoop2.6
ln -s spark-1.5.1-bin-hadoop2.6 spark
chown -R smile:smile spark
进入目录
cd /data/slot0/spark/
./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /data/slot0/spark-1.5.1-bin-hadoop2.6/sbin/../logs/spark-smile-org.apache.spark.deploy.master.Master-1-10-149-11-157.out
启动成功。查看web界面 http://your-host:8080
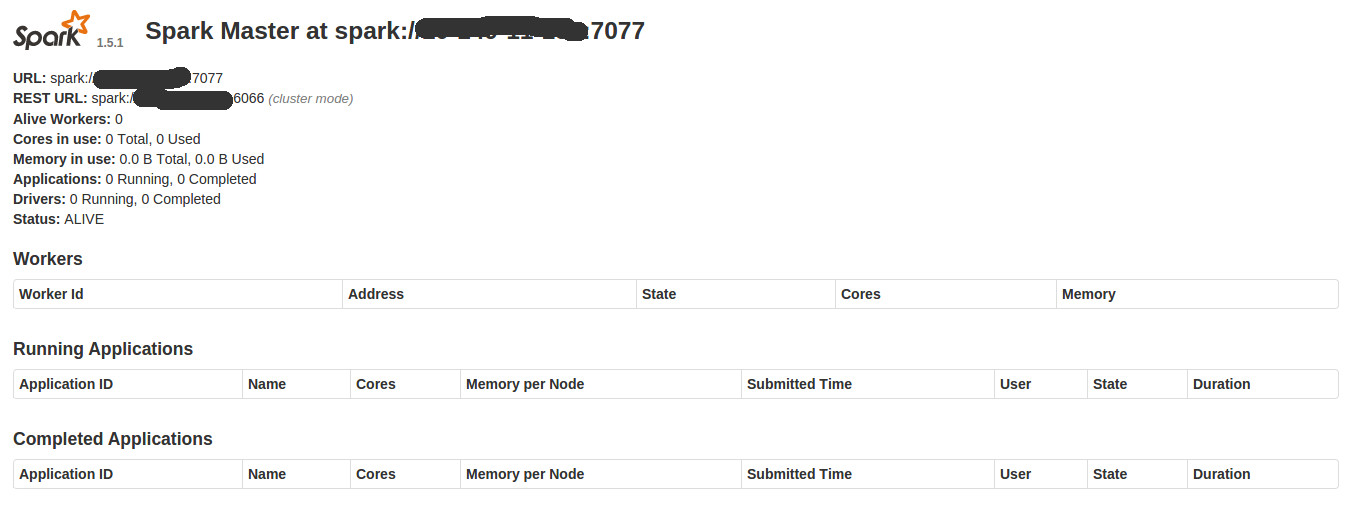
测试成功。关闭命令也很简单
$ sbin/stop-master.sh
stopping org.apache.spark.deploy.master.Master
在第一台服务器上,进入spark/conf目录,复制spark-env.sh.template为spark-env.sh文件
然后添加如下设置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=10.149.11.146:2181,10.149.11.147:2181,10.149.11.148:2181 -Dspark.deploy.zookeeper.dir=/vehicle_spark"
export SPARK_DAEMON_JAVA_OPTS
启动服务为master
./sbin/start-master.sh
依次在后面两个节点上启动start-master.sh, 此时3个节点都可以通过http://ip:8080打开master状态站点
./sbin/start-slave.sh spark://host1:7077,host2:7077,host3:7077
注意:
1. host1, host2, host3必须来自于几个master的8080站点,如果用IP代替连接会被拒绝
2. slave启动成功,可以在8081端口打开worker的UI站点,里面会显示当前的master leader
现在3台master的8080端口都显示了worker的状态。
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
15/11/16 13:22:37 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
Spark context available as sc.
15/11/16 13:22:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:22:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:23:15 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
15/11/16 13:23:15 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
15/11/16 13:23:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/16 13:23:21 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:23:22 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
SQL context available as sqlContext.
scala>
观察web ui和zookeeper,一切正常。
创建spark服务运行帐号
# useradd smilesmile帐号就是spark服务的运行帐号。
下载安装包并测试
在root帐号下,下载最新安装包,注意不是source,而是bin安装包,支持hadoop2.6以后的wget http://mirrors.cnnic.cn/apache/spark/spark-1.5.1/spark-1.5.1-bin-hadoop2.6.tgz 解压到下面的目录,并将owner和group设置成smile帐号,再建立链接。
wget http://mirrors.cnnic.cn/apache/spark/spark-1.5.1/spark-1.5.1-bin-hadoop2.6.tgz tar zxvf spark-1.5.1-bin-hadoop2.6.tgz
chown -R smile:smile spark-1.5.1-bin-hadoop2.6
ln -s spark-1.5.1-bin-hadoop2.6 spark
chown -R smile:smile spark
进入目录
cd /data/slot0/spark/
./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /data/slot0/spark-1.5.1-bin-hadoop2.6/sbin/../logs/spark-smile-org.apache.spark.deploy.master.Master-1-10-149-11-157.out
启动成功。查看web界面 http://your-host:8080
测试成功。关闭命令也很简单
$ sbin/stop-master.sh
stopping org.apache.spark.deploy.master.Master
基于zookeeper建立高可用集群
将三个节点作为master
现在打算用3台服务器建立master集群,使用zookeeper进行选举,确保总有一个master leader,其他两个总是master slave在第一台服务器上,进入spark/conf目录,复制spark-env.sh.template为spark-env.sh文件
然后添加如下设置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=10.149.11.146:2181,10.149.11.147:2181,10.149.11.148:2181 -Dspark.deploy.zookeeper.dir=/vehicle_spark"
export SPARK_DAEMON_JAVA_OPTS
启动服务为master
./sbin/start-master.sh
依次在后面两个节点上启动start-master.sh, 此时3个节点都可以通过http://ip:8080打开master状态站点
将后续节点作为slave启动
在另外几台spark 服务器上启动slave./sbin/start-slave.sh spark://host1:7077,host2:7077,host3:7077
注意:
1. host1, host2, host3必须来自于几个master的8080站点,如果用IP代替连接会被拒绝
2. slave启动成功,可以在8081端口打开worker的UI站点,里面会显示当前的master leader
现在3台master的8080端口都显示了worker的状态。
用shell测试连接master
$ ./bin/spark-shell --master spark://10-149-11-*:7077,10-149-11-*:7077,10-149-11-*:7077log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
15/11/16 13:22:37 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
Spark context available as sc.
15/11/16 13:22:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:22:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:23:15 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
15/11/16 13:23:15 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
15/11/16 13:23:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/16 13:23:21 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
15/11/16 13:23:22 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
SQL context available as sqlContext.
scala>
观察web ui和zookeeper,一切正常。
使用环境变量设置master url
由于spark-shell可以通过读取环境变量获得spark master信息,为了方便,不用每次都输入很长的参数在~/.bashrc中添加export MASTER=spark://10-149-*-*:7077,10-149-*-*:7077,10-149-*-*:7077

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Spark中将对象序列化存储到hdfs
- Spark初探
- Spark Streaming初探
- 搭建hadoop/spark集群环境
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark 性能相关参数配置详解-任务调度篇
- 基于spark1.3.1的spark-sql实战-01
- 基于spark1.3.1的spark-sql实战-02
- 在 Databricks 可获得 Spark 1.5 预览版
- spark standalone模式 zeppelin安装
- Apache Spark 1.5.0正式发布
- Tachyon 0.7.1伪分布式集群安装与测试
- spark取得lzo压缩文件报错 java.lang.ClassNotFoundException
- tachyon与hdfs,以及spark整合
- hive on spark 编译