超简单方法实现省/市/地区级联查询
2015-10-26 22:00
375 查看
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/48829517 未经博主允许不得转载。
博主地址是:http://blog.csdn.net/freewebsys
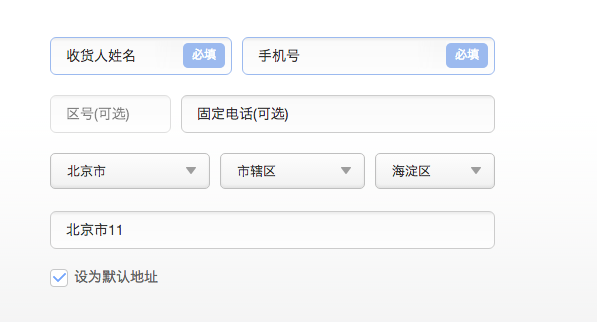
需要弄一个省、市,地区的级联查询。
页面好做,但是数据不太好弄,不好组织。
开始考虑抓一个现成的数据库,存储成表机构,然后查询。
发现这个是一个效率比较低的方案,但维护起来比较好。
直接对数据库进行操作行了。
从中国统计局页面拷贝数据:
http://www.stats.gov.cn
http://www.stats.gov.cn/was5/web/search?channelid=288041&andsen=行政区划
结果页面
http://www.stats.gov.cn/tjsj/tjbz/xzqhdm/201504/t20150415_712722.html

将数据拷贝到一个district.data.dic文本里面。
邮政编码一共6位,1-2位代表省,3-4位代表市,5-6位代表区/县。
所以,可以直接将这个数据存储成一个3级树形结构。
然后找到3-4位,判断市,最后5-6位是区/县。
运行结果:
这里面有个坑,找了半天才发现,国家统计局里面使用了一个非常特殊的中文空格,咋进行字符串过滤都去不掉。
就是字符 \u3000 ,这个也是一个空字符串。直接晕死!!!
转码才发现的:
http://tool.oschina.net/encode?type=3
博主地址是:http://blog.csdn.net/freewebsys
思路还是对的,中间遇到一个特殊空格的问题。
直接把这个树存储到内存,第一次加载使用,不用查询数据库了。
而且统计局这个数据更新的也比较慢,也就几年一次,够用了。
对于查询,同样的按照 1-2 , 3-4, 5-6 3级数据查询即可。
博主地址是:http://blog.csdn.net/freewebsys
1,关于中国地址
开发业务的时候遇到一个问题需要弄一个省、市,地区的级联查询。
页面好做,但是数据不太好弄,不好组织。
开始考虑抓一个现成的数据库,存储成表机构,然后查询。
发现这个是一个效率比较低的方案,但维护起来比较好。
直接对数据库进行操作行了。
2,一个简单的方案
首先要招到数据源:从中国统计局页面拷贝数据:
http://www.stats.gov.cn
http://www.stats.gov.cn/was5/web/search?channelid=288041&andsen=行政区划
结果页面
http://www.stats.gov.cn/tjsj/tjbz/xzqhdm/201504/t20150415_712722.html
将数据拷贝到一个district.data.dic文本里面。
邮政编码一共6位,1-2位代表省,3-4位代表市,5-6位代表区/县。
所以,可以直接将这个数据存储成一个3级树形结构。
3,代码实现
首先判断 1-2位,找到1级省。然后找到3-4位,判断市,最后5-6位是区/县。
import com.google.common.base.Strings;
import java.io.File;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class DistrictUtils {
static class Tree {
private String code;
private String name;
private Map<String, Tree> children = new HashMap<String, Tree>();
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Map<String, Tree> getChildren() {
return children;
}
public void addChildrenTree(String childrenCode, Tree childrenTree) {
this.children.put(childrenCode, childrenTree);
}
}
private static Map<String, Tree> addressTreeMap = new HashMap<String, Tree>();
static {
try {
// 取得运行时路径
String basePath = DistrictUtils.class.getResource("/")
.toString().replace("file:", "");
System.out.println(basePath);
List<String> lines = Files.readAllLines(new File(basePath + "district.data.dic").toPath(), Charset.forName("utf-8"));
//循环数据。
for (String line : lines) {
if (!Strings.isNullOrEmpty(line) && line.length() > 7) {
String code = line.substring(0, 6);
String name = line.substring(7);
//里面包括了1种特殊的空格(\u3000特殊的中文空格!!!)。
name = name.replaceAll("\t", "").replaceAll("\\u3000", "").replaceAll(" ", "");
String codeTmp1 = code.substring(0, 2);
String codeTmp2 = code.substring(2, 4);
String codeTmp3 = code.substring(4, 6);
//找到根节点。
if (codeTmp2.equals("00") && codeTmp3.equals("00")) {
Tree baseTree = new Tree();
baseTree.setCode(code);
baseTree.setName(name);
addressTreeMap.put(code, baseTree);
} else if (codeTmp3.equals("00")) {//找到二级节点
Tree secondTree = new Tree();
secondTree.setCode(code);
secondTree.setName(name);
//找到根节点,然后增加子树。
Tree baseTree = addressTreeMap.get(codeTmp1 + "0000");
if (baseTree != null) {
baseTree.addChildrenTree(code, secondTree);
} else {
System.err.println("no tree " + codeTmp1 + "0000");
}
} else {//剩下是3级节点。
Tree thirdTree = new Tree();
thirdTree.setCode(code);
thirdTree.setName(name);
//找到根节点。
Tree baseTree = addressTreeMap.get(codeTmp1 + "0000");
//然后找到二级节点,再增加子树。
Tree secondTree = baseTree.getChildren().get(codeTmp1 + codeTmp2 + "00");
if (secondTree != null) {
secondTree.addChildrenTree(code, thirdTree);
} else {
System.err.println("no tree " + codeTmp1 + codeTmp2 + "00");
}
}
}
}
} catch (Exception e) {
}
}
public static void loopTree(Tree addressTree, int level) {
for (int i = 0; i < level; i++) {
System.out.print("├─");
}
System.out.printf("[%s][%s]\n", addressTree.getCode(), addressTree.getName());
int nextLevel = level + 1;
for (Tree addressTreeTemp : addressTree.getChildren().values()) {
loopTree(addressTreeTemp, nextLevel);
}
}
public static void main(String[] args) {
System.out.println();
System.out.println();
for (Tree addressTree : addressTreeMap.values()) {
loopTree(addressTree, 1);
}
}
}运行结果:
├─[120000][天津市] ├─├─[120100][市辖区] ├─├─├─[120102][河东区] ├─├─├─[120103][河西区] ├─├─├─[120104][南开区] ├─├─├─[120105][河北区] ├─├─├─[120101][和平区] ├─├─├─[120112][津南区] ├─├─├─[120111][西青区] ├─├─├─[120110][东丽区] ├─├─├─[120116][滨海新区] ├─├─├─[120106][红桥区] ├─├─├─[120115][宝坻区] ├─├─├─[120114][武清区] ├─├─├─[120113][北辰区] ├─├─[120200][县] ├─├─├─[120225][蓟县] ├─├─├─[120223][静海县] ├─├─├─[120221][宁河县] ├─[110000][北京市] ├─├─[110200][县] ├─├─├─[110229][延庆县] ├─├─├─[110228][密云县] ├─├─[110100][市辖区] ├─├─├─[110114][昌平区] ├─├─├─[110115][大兴区] ├─├─├─[110116][怀柔区] ├─├─├─[110117][平谷区] ├─├─├─[110108][海淀区] ├─├─├─[110111][房山区] ├─├─├─[110107][石景山区] ├─├─├─[110112][通州区] ├─├─├─[110113][顺义区] ├─├─├─[110109][门头沟区] ├─├─├─[110106][丰台区] ├─├─├─[110105][朝阳区] ├─├─├─[110102][西城区] ├─├─├─[110101][东城区] ......
这里面有个坑,找了半天才发现,国家统计局里面使用了一个非常特殊的中文空格,咋进行字符串过滤都去不掉。
就是字符 \u3000 ,这个也是一个空字符串。直接晕死!!!
转码才发现的:
http://tool.oschina.net/encode?type=3
4,总结
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/48829517 未经博主允许不得转载。博主地址是:http://blog.csdn.net/freewebsys
思路还是对的,中间遇到一个特殊空格的问题。
直接把这个树存储到内存,第一次加载使用,不用查询数据库了。
而且统计局这个数据更新的也比较慢,也就几年一次,够用了。
对于查询,同样的按照 1-2 , 3-4, 5-6 3级数据查询即可。

相关文章推荐
- 大规模图的存储(前向星、next数组)
- JAVA中Process类的用法(感觉不错)
- Eclipse自动提示
- 为什么面试要问hashmap 的原理
- Linux 下报错:A Java RunTime Environment (JRE) or Java Development Kit (JDK) must解决方案
- Leetcode -- Candy
- 大规模图的存储(前向星、next数组)
- C++:运算符重载函数之"++"、"--"、"[ ]"、"=="的应用
- 《Programming with Objective-C》第四章 Encapsulating Data
- Struts2框架与jQuery框架之间ajax的实现
- Linux下安装Mysql
- HDU 1789 Doing Homework again(馋)
- 携程与去哪儿合并 百度成中国最大在线旅游提供商
- MySQL定期分析检查与优化表
- 模拟公交站台竖直排列,两端对齐
- low到一定程度了
- 简单中文分词系统的实现
- [转]DBA,SYSDBA,SYSOPER三者的区别
- NYOJ746 整数划分(四)
- hdu 4630 No Pain No Game(线段树)