hibernate的速度问题--hibernate.jdbc.fetch_size和 hibernate.jdbc.batch_size
2015-10-22 17:48
519 查看
MySQL Jdbc驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,直接造成较低的性能。
只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL (jdbc:mysql://ip:port/db?rewriteBatchedStatements=true)。不过,驱动具体是怎么样批量执行的? 你是不是需要看一下内幕,才敢放心地使用这个选项? 下文会给出答案。
另外,有人说rewriteBatchedStatements只对INSERT有效,有人说它对UPDATE/DELETE也有效。为此我做了一些实验(详见下文),结论是: 这个选项对INSERT/UPDATE/DELETE都有效,只不过对INSERT它为会预先重排一下SQL语句。
注:本文使用的mysql驱动版本是5.1.12
batchDelete(10条记录) => 发送10次delete 请求
batchUpdate(10条记录) => 发送10次update 请求
batchInsert(10条记录) => 发送10次insert 请求
也就是说,batchXXX()的确不起作用
batchDelete(10条记录) => 发送一次请求,内容为”delete from t where id = 1; delete from t where id = 2; delete from t where id = 3; ….”
batchUpdate(10条记录) => 发送一次请求,内容为”update t set … where id = 1; update t set … where id = 2; update t set … where id = 3 …”
batchInsert(10条记录) => 发送一次请求,内容为”insert into t (…) values (…) , (…), (…)”
对delete和update,驱动所做的事就是把多条sql语句累积起来再一次性发出去;而对于insert,驱动则会把多条sql语句重写成一条风格很酷的sql语句,然后再发出去。 官方文档说,这种insert写法可以提高性能(”This
is considerably faster (many times faster in some cases) than using separate single-row INSERT statements”)
<= 3时,驱动会宁愿一条一条地执行SQL。所以,如果你想验证rewriteBatchedStatements在你的系统里是否已经生效,记得要使用较大的batch.
---------------------------------------------------------------------------------------------------------------------------------------------------
这点我也疑惑过,最初应用hibernate的项目,我也感觉速度很慢,知道后来才知道问题的所在。
其实hibernate的速度性能并不差,比起jdbc来说,又是性能能高2倍。
当然了这和应用的数据库有关,在Oracle上,hibernate支持hibernate.jdbc.fetch_size和 hibernate.jdbc.batch_size,而MySQL却不支持,而我原来的项目绝大多数都是使用MySQL的,所以觉得速度慢,其实在企业级应用,尤其是金融系统大型应用上,使用Oracle比较多,相对来说,hibernate会提升系统很多性能的。
hibernate.jdbc.fetch_size 50 //读
hibernate.jdbc.batch_size 30 //写
hiberante.cfg.xml(Oracle ,sql server 支持,mysql不支持)
<property name="hibernate.jdbc.fetch_size">50</property>
<property name="hibernate.jdbc.batch_size">30</property>
这两个选项非常非常非常重要!!!将严重影响Hibernate的CRUD性能!
C = create, R = read, U = update, D = delete
Fetch Size 是设定JDBC的Statement读取数据的时候每次从数据库中取出的记录条数。
例如一次查询1万条记录,对于Oracle的JDBC驱动来说,是不会1次性把1万条取出来的,而只会取出Fetch Size条数,当纪录集遍历完了这些记录以后,再去数据库取Fetch Size条数据。
因此大大节省了无谓的内存消耗。当然Fetch Size设的越大,读数据库的次数越少,速度越快;Fetch Size越小,读数据库的次数越多,速度越慢。
这有点像平时我们写程序写硬盘文件一样,设立一个Buffer,每次写入Buffer,等Buffer满了以后,一次写入硬盘,道理相同。
Oracle数据库的JDBC驱动默认的Fetch Size=10,是一个非常保守的设定,根据我的测试,当Fetch Size=50的时候,性能会提升1倍之多,当Fetch Size=100,性能还能继续提升20%,Fetch Size继续增大,性能提升的就不显著了。
因此我建议使用Oracle的一定要将Fetch Size设到50。
不过并不是所有的数据库都支持Fetch Size特性,例如MySQL就不支持。
MySQL就像我上面说的那种最坏的情况,他总是一下就把1万条记录完全取出来,内存消耗会非常非常惊人!这个情况就没有什么好办法了 :(
Batch Size是设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小,有点相当于设置Buffer缓冲区大小的意思。
Batch Size越大,批量操作的向数据库发送sql的次数越少,速度就越快。我做的一个测试结果是当Batch Size=0的时候,使用Hibernate对Oracle数据库删除1万条记录需要25秒,Batch Size = 50的时候,删除仅仅需要5秒!!!
//
我们通常不会直接操作一个对象的标识符(identifier), 因此标识符的setter方法应该被声明为私有的(private)。这样当一个对象被保存的时候,只有Hibernate可以为它分配标识符。 你会发现Hibernate可以直接访问被声明为public,private和protected等不同级别访问控制的方法(accessor method)和字段(field)。 所以选择哪种方式来访问属性是完全取决于你,你可以使你的选择与你的程序设计相吻合。
所有的持久类(persistent classes)都要求有无参的构造器(no-argument constructor); 因为Hibernate必须要使用Java反射机制(Reflection)来实例化对象。构造器(constructor)的访问控制可以是私有的(private), 然而当生成运行时代理(runtime proxy)的时候将要求使用至少是package级别的访问控制,这样在没有字节码编入 (bytecode instrumentation)的情况下,从持久化类里获取数据会更有效率一些。
而
就是每次你在查询时,会级联查询的深度,譬如你对关联vo设置了eager的话,如果fetch_depth值太小的话,会发多很多条sql
只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL (jdbc:mysql://ip:port/db?rewriteBatchedStatements=true)。不过,驱动具体是怎么样批量执行的? 你是不是需要看一下内幕,才敢放心地使用这个选项? 下文会给出答案。
另外,有人说rewriteBatchedStatements只对INSERT有效,有人说它对UPDATE/DELETE也有效。为此我做了一些实验(详见下文),结论是: 这个选项对INSERT/UPDATE/DELETE都有效,只不过对INSERT它为会预先重排一下SQL语句。
注:本文使用的mysql驱动版本是5.1.12
实验记录:未打开rewriteBatchedStatements时
未打开rewriteBatchedStatements时,根据wireshark嗅探出的mysql报文可以看出,batchDelete(10条记录) => 发送10次delete 请求
batchUpdate(10条记录) => 发送10次update 请求
batchInsert(10条记录) => 发送10次insert 请求
也就是说,batchXXX()的确不起作用
实验记录:打开了rewriteBatchedStatements后
打开rewriteBatchedStatements后,根据wireshark嗅探出的mysql报文可以看出batchDelete(10条记录) => 发送一次请求,内容为”delete from t where id = 1; delete from t where id = 2; delete from t where id = 3; ….”
batchUpdate(10条记录) => 发送一次请求,内容为”update t set … where id = 1; update t set … where id = 2; update t set … where id = 3 …”
batchInsert(10条记录) => 发送一次请求,内容为”insert into t (…) values (…) , (…), (…)”
对delete和update,驱动所做的事就是把多条sql语句累积起来再一次性发出去;而对于insert,驱动则会把多条sql语句重写成一条风格很酷的sql语句,然后再发出去。 官方文档说,这种insert写法可以提高性能(”This
is considerably faster (many times faster in some cases) than using separate single-row INSERT statements”)
一个注意事项
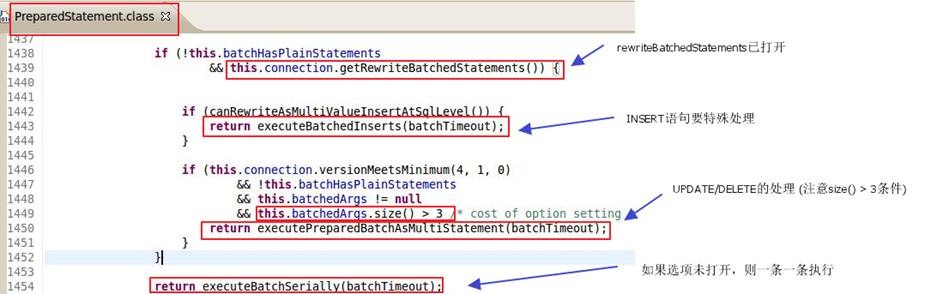
需要注意的是,即使rewriteBatchedStatements=true, batchDelete()和batchUpdate()也不一定会走批量: 当batchSize<= 3时,驱动会宁愿一条一条地执行SQL。所以,如果你想验证rewriteBatchedStatements在你的系统里是否已经生效,记得要使用较大的batch.
对应的代码
最后可以看下对应的MySQL JDBC驱动的代码,以加深印象: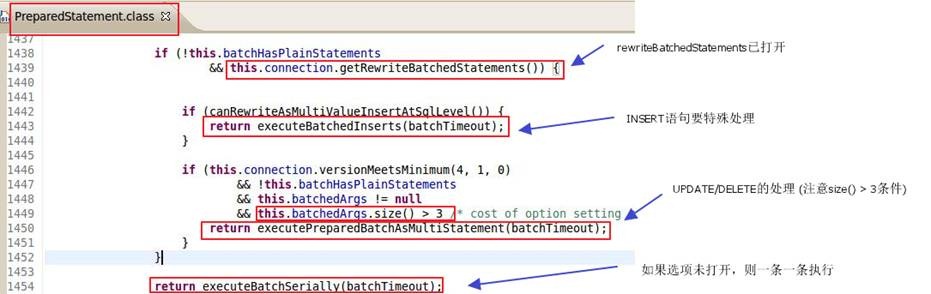
---------------------------------------------------------------------------------------------------------------------------------------------------
这点我也疑惑过,最初应用hibernate的项目,我也感觉速度很慢,知道后来才知道问题的所在。
其实hibernate的速度性能并不差,比起jdbc来说,又是性能能高2倍。
当然了这和应用的数据库有关,在Oracle上,hibernate支持hibernate.jdbc.fetch_size和 hibernate.jdbc.batch_size,而MySQL却不支持,而我原来的项目绝大多数都是使用MySQL的,所以觉得速度慢,其实在企业级应用,尤其是金融系统大型应用上,使用Oracle比较多,相对来说,hibernate会提升系统很多性能的。
hibernate.jdbc.fetch_size 50 //读
hibernate.jdbc.batch_size 30 //写
hiberante.cfg.xml(Oracle ,sql server 支持,mysql不支持)
<property name="hibernate.jdbc.fetch_size">50</property>
<property name="hibernate.jdbc.batch_size">30</property>
这两个选项非常非常非常重要!!!将严重影响Hibernate的CRUD性能!
C = create, R = read, U = update, D = delete
Fetch Size 是设定JDBC的Statement读取数据的时候每次从数据库中取出的记录条数。
例如一次查询1万条记录,对于Oracle的JDBC驱动来说,是不会1次性把1万条取出来的,而只会取出Fetch Size条数,当纪录集遍历完了这些记录以后,再去数据库取Fetch Size条数据。
因此大大节省了无谓的内存消耗。当然Fetch Size设的越大,读数据库的次数越少,速度越快;Fetch Size越小,读数据库的次数越多,速度越慢。
这有点像平时我们写程序写硬盘文件一样,设立一个Buffer,每次写入Buffer,等Buffer满了以后,一次写入硬盘,道理相同。
Oracle数据库的JDBC驱动默认的Fetch Size=10,是一个非常保守的设定,根据我的测试,当Fetch Size=50的时候,性能会提升1倍之多,当Fetch Size=100,性能还能继续提升20%,Fetch Size继续增大,性能提升的就不显著了。
因此我建议使用Oracle的一定要将Fetch Size设到50。
不过并不是所有的数据库都支持Fetch Size特性,例如MySQL就不支持。
MySQL就像我上面说的那种最坏的情况,他总是一下就把1万条记录完全取出来,内存消耗会非常非常惊人!这个情况就没有什么好办法了 :(
Batch Size是设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小,有点相当于设置Buffer缓冲区大小的意思。
Batch Size越大,批量操作的向数据库发送sql的次数越少,速度就越快。我做的一个测试结果是当Batch Size=0的时候,使用Hibernate对Oracle数据库删除1万条记录需要25秒,Batch Size = 50的时候,删除仅仅需要5秒!!!
//
我们通常不会直接操作一个对象的标识符(identifier), 因此标识符的setter方法应该被声明为私有的(private)。这样当一个对象被保存的时候,只有Hibernate可以为它分配标识符。 你会发现Hibernate可以直接访问被声明为public,private和protected等不同级别访问控制的方法(accessor method)和字段(field)。 所以选择哪种方式来访问属性是完全取决于你,你可以使你的选择与你的程序设计相吻合。
所有的持久类(persistent classes)都要求有无参的构造器(no-argument constructor); 因为Hibernate必须要使用Java反射机制(Reflection)来实例化对象。构造器(constructor)的访问控制可以是私有的(private), 然而当生成运行时代理(runtime proxy)的时候将要求使用至少是package级别的访问控制,这样在没有字节码编入 (bytecode instrumentation)的情况下,从持久化类里获取数据会更有效率一些。
而
| hibernate.max_fetch_depth | 设置外连接抓取树的最大深度 取值. 建议设置为0到3之间 |

相关文章推荐
- 【JSON】Jackson初学,及常用的例子
- 设计模式之观察者模式(订阅模式),jquery实现
- js动态删除增加dom元素
- JQuery 学习简单整理
- Maximum Subarray Difference Solution
- css3转盘抽奖示例-转指针
- jQuery事件之鼠标事件
- 让你的MyEclipse自动提示jquery和extjs等
- DIV横向排列_CSS如何让多个div盒子并排同行显示
- atom编辑器的使用
- Jquery初始--遍历
- jquery中把字符串转换为数字
- js Table鼠标滑过变色,单击变色,隐藏某列的方法
- CSS:透明度 opacity与rgba()的区别
- Jquery初始--文本格式
- nodejs里的module.exports和exports的关系
- 通达OA2015-工作流前端触发器的使用
- js/jquery获取浏览器窗口可视区域高度和宽度以及滚动条高度
- (一)页面中引入seajs以及模块的加载和启动
- 学习笔记 一步步了解webpack