Hibernate中单向一对多,单向多对一,双向一对多 inverse="true" casecade="save-update"的理解
2015-10-18 01:56
585 查看
Customer类:
Java代码

public class Customer {
private int id;
private String name;
private Set orders = new HashSet();
•••
}
即Customer类具有一个set集合属性orders,其中Order是一个普通的类:
Java代码
public class Order {
private int id;
private String orderName;
•••
}
数据库中表的结构:
Java代码
t_customer: 两个字段:id name
t_order: 三个字段:id orderName customerid
Customer类的映射文件:Customer.hbm.xml (Order类的映射文件忽略)
Java代码
<hibernate-mapping>
<class name="test.Customer" table="t_customer" lazy="false">
<id name="id">
<generator class="native"/>
</id>
<property name="name"/>
<set name="orders" cascade="save-update" lazy="false">
<key column="customerid"/>
<one-to-many class="test.Order"/>
</set>
</class>
</hibernate-mapping>
执行如下代码:
Java代码
Set orders = new HashSet();
Order o1 = new Order();
o1.setOrderName("o1");
Order o2 = new Order();
o2.setOrderName("o2");
orders.add(o1);
orders.add(o2);
Customer c = new Customer();
c.setName("aaa");
c.setOrders(orders);
session.save(c);
此时Hibernate发出的sql语句如下:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: update t_order set customerid=? where id=?
Hibernate: update t_order set customerid=? where id=?
查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 1
2 o2 1
保存Customer对象时,首先发出insert into t_customer (name) values (?)语句将c同步到数据库,由于在<set>映射中设置cascade="save-update",所以会同时保存orders集合中的Order类型的o1,o2对象(如果没有这个设置,即cascade="save-update"),那么Hibenrate不会自动保存orders集合中的对象,那么在更新时将会抛出如下异常:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: update t_order set customerid=? where id=?
org.hibernate.TransientObjectException: test.Order
••••••
抛出这一异常的原因是:<set>映射默认"inverse=fasle"即由Customer对象作为主控方,那么它要负责关联的维护工作,在这里也就是负责更新t_order表中的customerid字段的值,但由于未设置cascade="save-update",所以orders集合中的对象不会在保存customer时自动保存,因此会抛出异常(如果未设置,需要手动保存)。
现在设置cascade="save-update",同时设置inverse="true",即:
Java代码
•••
<set name="orders" cascade="save-update" inverse="true" lazy="false">
<key column="customerid"/>
<one-to-many class="test.Order"/>
</set>
•••
同样执行上述代码,发出如下语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: insert into t_order (orderName) values (?)
相比上一次执行,少了两条update语句,查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 NULL
2 o2 NULL
发现t_order表中customerid的值为NULL,这是由于设置了inverse="true",它意味着
Customer不再作为主控方,而将关联关系的维护工作交给关联对象Orders来完成。在保存Customer时,Customer不在关心Orders的customerid属性,必须由Order自己去维护,即设置order.setCustomer(customer);
如果需要通过Order来维护关联关系,那么这个关联关系转换成双向关联。
修改Order类代码:
Java代码
public class Order {
private int id;
private String orderName;
private Customer customer;
•••
}
Order.hbm.xml:
Java代码
<hibernate-mapping>
<class name="test.Order" table="t_order">
<id name="id">
<generator class="native"/>
</id>
<property name="orderName"/>
<many-to-one name="customer" column="customerid"/>
</class>
</hibernate-mapping>
此时数据库中表的结构不会变化。
再次执行上述代码,发出如下sql语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
发现在保存Order对象时为customerid字段赋值,因为Order对象中拥有Customer属性,对应customerid字段,查看数据库表:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 NULL
2 o2 NULL
发现customerid的值仍为NULL,因为在上述代码中并未设置Order对象的Customer属性值,由于设置了inverse="true",所以Order对象需要维护关联关系,所以必须进行设置,即
order.setCustomer(customer);
修改上述代码为:
Java代码
•••
Customer c = new Customer();
Set orders = new HashSet();
Order o1 = new Order();
o1.setOrderName("o1");
o1.setCustomer(c);
Order o2 = new Order();
o2.setOrderName("o2");
o2.setCustomer(c);
orders.add(o1);
orders.add(o2);
c.setName("aaa");
c.setOrders(orders);
session.save(c);
•••
执行上述代码,发出如下语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 1
2 o2 1
发现已经设置了customerid的值。
在一对多关联中,在多的一方设置inverse="true",有助于性能的改善。通过上述分析可以发现少了update语句。
在我们以前的数据库设计中,设计表就不是一件轻松的事情。多种事物之间往往都是有这样那样的关系的。那怎样设计表格,才能既将事情描述明白,又能使数据库设计的比较合理呢?那里我们提供了好多规范,好多约束来满足这些事情。在hibernate中,通过对象来创建表,当然也需要有一些东西来维护各个对象之间的关系,以创建出合适的表。这个东西就是映射。通过映射,可以轻松的将对象间的关系表述的非常清楚明白。对象间关系搞明白了,数据库表自然也就出来了。那我们先看一下关联映射。关联映射就是将关联关系映射到数据库中,所谓的关联关系在对象模型中就是一个或多个引用。
首先来看一下多对一。举个例子来说用户和组。一个组中有多个用户,一个用户只能属于一组。用户和组之间就是一个多对一的关系的。如下图

这个关系我们要怎样维护呢?我们想象一下,假如在一的一端维护关系,即在group一端加一个字段userId来标识学生。那设计出来的表格存储数据是这个样子的。
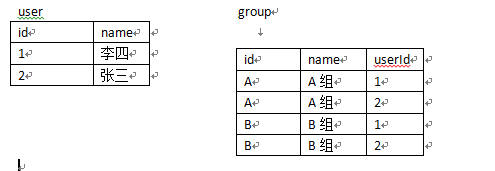
不解释,直接看在多的一端维护关系
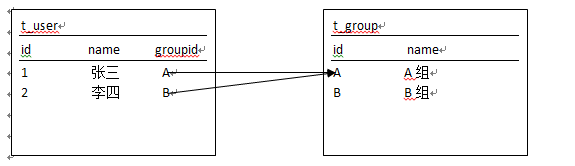
不用说,大家就知道在多的一端维护数据冗余要少的多。怎么来解释这个问题呢?大家想一下是多的记少的容易记,还是少的记多的容易记呢?举个例子员工和老板。你说是老板记员工比较容易还是员工记老板比较容易呢?很明显记少的比较容易啊,能维护二者的关系也能减少工作量。hibernate当然也是这么做的。看一下实体和配置文件。这里只显示部分代码。
对应的关系映射文件
一对多的实现就是这个样子了,那一对多反过来不就是多对一吗?他们有什么不同呢?一对多关联映射和多对一关联映射的原理确实是一致的,都是在多的一端加入外键,指向一的一端。但是他们也是有区别的。我们先看一下他的实现。我们仍然采用一对多的学生用户举例。
看一下对应的配置文件又是怎么实现的呢?
这里面并没有体现出任何与一的一端有关联的字段。一对多的关联最后生成的表格与多对一是一样的。但是他们到底有什么区别呢?多对一的维护关系是多指向一的关系,有了此关系,在加载多的时候可以将一加载上来。即我们查询用户的时候,组也被查询出来了。而一对多的关系,是指在加载一的时候可以将多加载进来。即查询组的时候,用户也被查出来了。他们适用于不同的需求。
刚开始我们说过,不管是一对多还是多对一,都是在多的一端维护关系。从程序的执行状况来解释一下这样做的原因。若在一的一端维护关系,多的一端User并不知道Group的存在。所以在保存User的时候,关系字段groupId是为null的。如果将该关系字段设置为非空,则将无法保存数据。另外因为User不维护关系,Group维护关系,则在对Group进行操作时,Group就会发出多余的update语句,去维持Group与User的关系,这样加载Group的时候才会把该Group对应的学生加载进来。可见一对多关联映射是存在这很大的问题的。那怎么解决这些问题呢?看一下下面的一对多双向关联。
实体类实现
接下来看一下映射文件
通过一对多双向关联映射,我们将关系交给多的一端维护,而且从一的一端也能够看到多的一端。这样就很好的解决了一对多单向关联的缺陷,优化之后的它查询数据,不管是一的一端还是多的一端,只需要一个sql语句就搞定了。要知道他不是由于需求驱动而设计的。
今天,说了多对一,一对多单向,一对多双向。总之,就是一与多之间的关系。下篇博客将讲述多对多关联映射,一对一主键关联映射,一对一唯一外键关联映射。
Java代码
public class Customer {
private int id;
private String name;
private Set orders = new HashSet();
•••
}
即Customer类具有一个set集合属性orders,其中Order是一个普通的类:
Java代码
public class Order {
private int id;
private String orderName;
•••
}
数据库中表的结构:
Java代码
t_customer: 两个字段:id name
t_order: 三个字段:id orderName customerid
Customer类的映射文件:Customer.hbm.xml (Order类的映射文件忽略)
Java代码
<hibernate-mapping>
<class name="test.Customer" table="t_customer" lazy="false">
<id name="id">
<generator class="native"/>
</id>
<property name="name"/>
<set name="orders" cascade="save-update" lazy="false">
<key column="customerid"/>
<one-to-many class="test.Order"/>
</set>
</class>
</hibernate-mapping>
执行如下代码:
Java代码
Set orders = new HashSet();
Order o1 = new Order();
o1.setOrderName("o1");
Order o2 = new Order();
o2.setOrderName("o2");
orders.add(o1);
orders.add(o2);
Customer c = new Customer();
c.setName("aaa");
c.setOrders(orders);
session.save(c);
此时Hibernate发出的sql语句如下:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: update t_order set customerid=? where id=?
Hibernate: update t_order set customerid=? where id=?
查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 1
2 o2 1
保存Customer对象时,首先发出insert into t_customer (name) values (?)语句将c同步到数据库,由于在<set>映射中设置cascade="save-update",所以会同时保存orders集合中的Order类型的o1,o2对象(如果没有这个设置,即cascade="save-update"),那么Hibenrate不会自动保存orders集合中的对象,那么在更新时将会抛出如下异常:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: update t_order set customerid=? where id=?
org.hibernate.TransientObjectException: test.Order
••••••
抛出这一异常的原因是:<set>映射默认"inverse=fasle"即由Customer对象作为主控方,那么它要负责关联的维护工作,在这里也就是负责更新t_order表中的customerid字段的值,但由于未设置cascade="save-update",所以orders集合中的对象不会在保存customer时自动保存,因此会抛出异常(如果未设置,需要手动保存)。
现在设置cascade="save-update",同时设置inverse="true",即:
Java代码
•••
<set name="orders" cascade="save-update" inverse="true" lazy="false">
<key column="customerid"/>
<one-to-many class="test.Order"/>
</set>
•••
同样执行上述代码,发出如下语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName) values (?)
Hibernate: insert into t_order (orderName) values (?)
相比上一次执行,少了两条update语句,查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 NULL
2 o2 NULL
发现t_order表中customerid的值为NULL,这是由于设置了inverse="true",它意味着
Customer不再作为主控方,而将关联关系的维护工作交给关联对象Orders来完成。在保存Customer时,Customer不在关心Orders的customerid属性,必须由Order自己去维护,即设置order.setCustomer(customer);
如果需要通过Order来维护关联关系,那么这个关联关系转换成双向关联。
修改Order类代码:
Java代码
public class Order {
private int id;
private String orderName;
private Customer customer;
•••
}
Order.hbm.xml:
Java代码
<hibernate-mapping>
<class name="test.Order" table="t_order">
<id name="id">
<generator class="native"/>
</id>
<property name="orderName"/>
<many-to-one name="customer" column="customerid"/>
</class>
</hibernate-mapping>
此时数据库中表的结构不会变化。
再次执行上述代码,发出如下sql语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
发现在保存Order对象时为customerid字段赋值,因为Order对象中拥有Customer属性,对应customerid字段,查看数据库表:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 NULL
2 o2 NULL
发现customerid的值仍为NULL,因为在上述代码中并未设置Order对象的Customer属性值,由于设置了inverse="true",所以Order对象需要维护关联关系,所以必须进行设置,即
order.setCustomer(customer);
修改上述代码为:
Java代码
•••
Customer c = new Customer();
Set orders = new HashSet();
Order o1 = new Order();
o1.setOrderName("o1");
o1.setCustomer(c);
Order o2 = new Order();
o2.setOrderName("o2");
o2.setCustomer(c);
orders.add(o1);
orders.add(o2);
c.setName("aaa");
c.setOrders(orders);
session.save(c);
•••
执行上述代码,发出如下语句:
Java代码
Hibernate: insert into t_customer (name) values (?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
Hibernate: insert into t_order (orderName, customerid) values (?, ?)
查看数据库:
Java代码
t_customer : t_order:
id | name id | orderName | customerid
1 aaa 1 o1 1
2 o2 1
发现已经设置了customerid的值。
在一对多关联中,在多的一方设置inverse="true",有助于性能的改善。通过上述分析可以发现少了update语句。
在我们以前的数据库设计中,设计表就不是一件轻松的事情。多种事物之间往往都是有这样那样的关系的。那怎样设计表格,才能既将事情描述明白,又能使数据库设计的比较合理呢?那里我们提供了好多规范,好多约束来满足这些事情。在hibernate中,通过对象来创建表,当然也需要有一些东西来维护各个对象之间的关系,以创建出合适的表。这个东西就是映射。通过映射,可以轻松的将对象间的关系表述的非常清楚明白。对象间关系搞明白了,数据库表自然也就出来了。那我们先看一下关联映射。关联映射就是将关联关系映射到数据库中,所谓的关联关系在对象模型中就是一个或多个引用。
首先来看一下多对一。举个例子来说用户和组。一个组中有多个用户,一个用户只能属于一组。用户和组之间就是一个多对一的关系的。如下图
这个关系我们要怎样维护呢?我们想象一下,假如在一的一端维护关系,即在group一端加一个字段userId来标识学生。那设计出来的表格存储数据是这个样子的。
不解释,直接看在多的一端维护关系
不用说,大家就知道在多的一端维护数据冗余要少的多。怎么来解释这个问题呢?大家想一下是多的记少的容易记,还是少的记多的容易记呢?举个例子员工和老板。你说是老板记员工比较容易还是员工记老板比较容易呢?很明显记少的比较容易啊,能维护二者的关系也能减少工作量。hibernate当然也是这么做的。看一下实体和配置文件。这里只显示部分代码。
| public class Group { private int id; private String name; ************* 省略get,set方法 ************* } 从这里我们可以看出,group并不知道user的存在。 | public class User { private int id; private String name; private Group group; ************* 省略get,set方法 ************* } user中包含group属性,来维持关系。 |
| Group.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.Group"table="t_group"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> </class> </hibernate-mapping> | User.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.User"table="t_user"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> <!—这里用来维系与group的关系。解释一下cascade级联,意思是指定两个对象之间的操作联动关系,对一个对象执行了操作(他是对象之间的连锁操作,只影响添加,删除和修改。)之后,对其指定的级联对象也需要执行相同的操作。可以取值为all,none,save-update,delete。all代表在所有的情况下都执行级联操作。none指在所有情况下都不执行级联操作。save-update指在保存和更新的时候执行级联操作。delete指在删除的时候执行级联操作。 --> <many-to-one name="group"column="groupid"cascade="save-update"/> </class> </hibernate-mapping> |
| public class Group { private int id; private String name; private Set users; ************* 省略get,set方法 ************* } | public class User { private int id; private String name; ************* 省略get,set方法 ************* } |
| Group.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.Group"table="t_group"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> <set name=”users”> <key column=”groupId”/> <one-to-many class="com.bjpowernode.hibernate.User"> </set> </class> </hibernate-mapping> | User.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.User"table="t_user"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> </class> </hibernate-mapping> |
刚开始我们说过,不管是一对多还是多对一,都是在多的一端维护关系。从程序的执行状况来解释一下这样做的原因。若在一的一端维护关系,多的一端User并不知道Group的存在。所以在保存User的时候,关系字段groupId是为null的。如果将该关系字段设置为非空,则将无法保存数据。另外因为User不维护关系,Group维护关系,则在对Group进行操作时,Group就会发出多余的update语句,去维持Group与User的关系,这样加载Group的时候才会把该Group对应的学生加载进来。可见一对多关联映射是存在这很大的问题的。那怎么解决这些问题呢?看一下下面的一对多双向关联。
实体类实现
| public class Group { private int id; private String name; private Set users; ************* 省略get,set方法 ************* } | public class User { private int id; private String name; private Group group; ************* 省略get,set方法 ************* } |
| group.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.Group"table="t_group"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> <!—inverse属性他可以用在一对多和多对多双向关联上,inverse默认为false,false表示本端可以维护关系,如果inverse为true,则表示本端不能维护关系,会交给另一端维护关系,本端失效。此处我们让多的一端维护关系,一的一端失效。所以,此处设置为true --> <set name=”users” inverse=”true”> <key column=”groupId”/> <one-to-many class="com.bjpowernode.hibernate.User"> </set> </class> </hibernate-mapping> | User.hbm.xml <hibernate-mapping> <classname="com.bjpowernode.hibernate.User"table="t_user"> <idname="id"> <generatorclass="native"/> </id> <propertyname="name"/> <many-to-one name=”groupId”/> </class> </hibernate-mapping> 这里要注意many-to-one的值要与key的值保持一致。 |
今天,说了多对一,一对多单向,一对多双向。总之,就是一与多之间的关系。下篇博客将讲述多对多关联映射,一对一主键关联映射,一对一唯一外键关联映射。

相关文章推荐
- Mod 与 RequireJS/SeaJS 的那些事
- Permutation Sequence 解答
- android多分辨率多屏幕密度下UI适配方案
- 2015 NEERC F. Gourmet and Banquet
- 控制器管理UINavigationController、UINavigationBar
- UIScrollView
- 物理引擎UIDynamic
- 呈现样式UIModalPresentation
- Hibernate的命名查询(NamedQuery)
- 百度编辑器ueditor的简单使用
- QuickFix/N简介
- QuickFIX/N入门:(三)如何配置QuickFIX/N
- InvokeRequired和Invoke
- HDU 5504 GT and sequence(排除陷阱就是正解)——BestCoder Round #60
- hdoj 5504 GT and sequence 【脑子 抽了】
- October Challenge 2015 Rupsa and Equilateral Triangle
- HDU GT and sequence (数的乘积最大)
- /proc/cpuinfo 文件分析(查看CPU信息)
- Juint4源码解读
- String和StringBuilder的相互转化