Cluster: EM
2015-10-12 18:57
127 查看
最近项目需要对Cluster进行一个survey,需要利用cluster进行feature selection,觉得EM聚类也算是一个比较经典算法。
1.EM算法
在实际问题我们的模型中需要假设关键的隐变量,这些隐变量对模型的结果起着决定性影响,而我们又无法直接给出这组隐变量,于是可以通过最大似然估计来对这组隐变量进行嗅探(其实就是不断的try-do,不过这个try-do并有理论依据的trend)。
EM其实就是这两个过程:Expectation - Maximization,E阶段完成对参数估计,
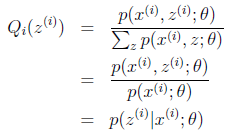
M阶段完成最大化似然估计,
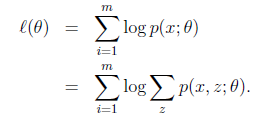
停止条件便是最大化似然估计较上次提升不大(小于预先设定阈值)或者达到预定迭代次数,首次隐变量可以通过根据实际情况采取先验办法或者随机取值。
EM看起来比较简单直观,一些领域算法中包含EM,如NLP中HMM的第三个问题(求模型参数),对于一些模型求隐变量是一个很有用的办法,当然写到这里感觉采用随机抽样的办法可不可以做为EM的initial呢?对于EM缺陷几乎是所有ML算法的通病-局部最优。
关于EM的理论证明基础便是凸凹基集(Jensen不等式,高数)+证明收敛,具体可以看看
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://blog.csdn.net/abcjennifer/article/details/8170378。
2.EM聚类
上面公式中p是指概率,z表示隐变量,x表示数据点,同k-means一样每个数据点隶属不同的cluster,不过这里采用soft即每个数据点依照不同分布概率隶属于不同的cluster,weka里面采用常见的高斯混合,假设了数据的每个属性之间独立,离散属性和连续属性不同的概率计算方式。
weka中-M参数设置-1时候可以通过交叉验证方式获取最好的聚类个数,划分方法是k-means,主要是分10-fold,每一个fold计算loglikelihood最后求average,当然这里可以通过对k进行EM,等于使用了两层的EM。
weka里面有经典的EM聚类算法实现,具体代码讲解请看:
http://www.360doc.com/content/13/0722/21/13256259_301813491.shtml
1.EM算法
在实际问题我们的模型中需要假设关键的隐变量,这些隐变量对模型的结果起着决定性影响,而我们又无法直接给出这组隐变量,于是可以通过最大似然估计来对这组隐变量进行嗅探(其实就是不断的try-do,不过这个try-do并有理论依据的trend)。
EM其实就是这两个过程:Expectation - Maximization,E阶段完成对参数估计,
M阶段完成最大化似然估计,
停止条件便是最大化似然估计较上次提升不大(小于预先设定阈值)或者达到预定迭代次数,首次隐变量可以通过根据实际情况采取先验办法或者随机取值。
EM看起来比较简单直观,一些领域算法中包含EM,如NLP中HMM的第三个问题(求模型参数),对于一些模型求隐变量是一个很有用的办法,当然写到这里感觉采用随机抽样的办法可不可以做为EM的initial呢?对于EM缺陷几乎是所有ML算法的通病-局部最优。
关于EM的理论证明基础便是凸凹基集(Jensen不等式,高数)+证明收敛,具体可以看看
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://blog.csdn.net/abcjennifer/article/details/8170378。
2.EM聚类
上面公式中p是指概率,z表示隐变量,x表示数据点,同k-means一样每个数据点隶属不同的cluster,不过这里采用soft即每个数据点依照不同分布概率隶属于不同的cluster,weka里面采用常见的高斯混合,假设了数据的每个属性之间独立,离散属性和连续属性不同的概率计算方式。
weka中-M参数设置-1时候可以通过交叉验证方式获取最好的聚类个数,划分方法是k-means,主要是分10-fold,每一个fold计算loglikelihood最后求average,当然这里可以通过对k进行EM,等于使用了两层的EM。
weka里面有经典的EM聚类算法实现,具体代码讲解请看:
http://www.360doc.com/content/13/0722/21/13256259_301813491.shtml

相关文章推荐
- mac 终端ssh远程连接到服务器
- 【UVA272】TEX Quotes
- iOS人脸识别核心代码(备用)
- StringReader使用过程中出现空指针异常
- vsftpd配置文件详解
- TabControl横向显示
- uva-455
- 【线性代数】 02 - 线性空间
- LeetCode OJ:First Bad Version(首个坏版本)
- JS添加可信站点、修改ActiveX安全设置,禁用弹出窗口阻止程序的方法
- django关于csrf防止跨站的ajax请求403处理
- 51nod建设国家
- POI操作Office导出Html文档
- POI操作Office导出Html文档
- linux内核之trap.c文件分析
- SSM框架 tomcat7部署不成功
- cocos2d 简单的日常高仿酷跑游戏
- android application类的用法
- 用VC自己动手做个录音机
- Unity Text 插入超链接