从零自学Hadoop(08):第一个MapReduce
2015-10-08 09:37
211 查看
阅读目录
序数据准备
wordcount
Yarn
新建MapReduce
示例下载
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们的Eclipse插件搞定,那开始我们的MapReduce之旅。
在这里,我们先调用官方的wordcount例子,然后再手动创建个例子,这样可以更好的理解Job。
数据准备
一:说明
wordcount这个类是对不同的word进行统计个数,所以这里我们得准备数据,当然也不需要很大的数据量,毕竟是自己做试验对吧。二:造数据
打开记事本,输入各种word,有相同的,不同的。然后保存为words_01.txt。public static void main(String[] args) throws Exception {
//配置信息
Configuration conf = new Configuration();
//job名称
Job job = Job.getInstance(conf, "mywordcount");
job.setJarByClass(WordCountEx.class);
job.setMapperClass(MyMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//输入、输出path
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//结束
System.exit(job.waitForCompletion(true) ? 0 : 1);
}View Code
六:导出jar包
导出我们写好的jar包。命名为com.first.jar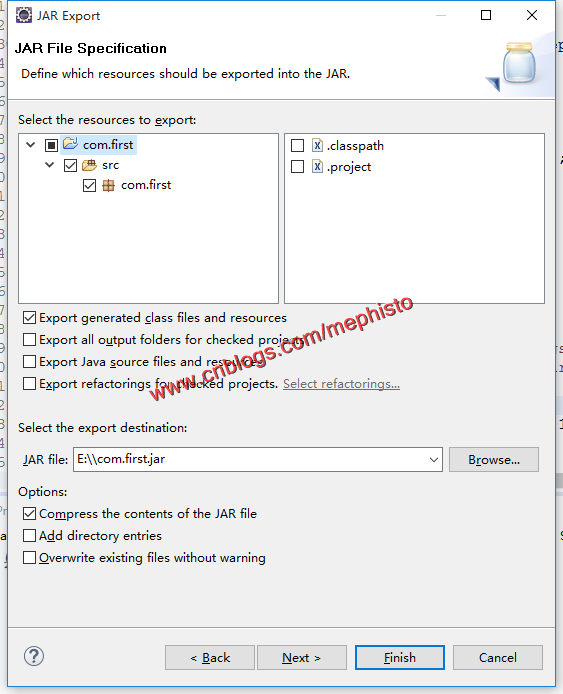
七:放入Linux
将导出的jar包放到H31的/var/tmp下cd /var/tmp ls
八:执行
大家仔细看下命令和结果会发现有什么不同yarn jar com.first.jar /tmp/input/words_01.txt /tmp/output/1007_03
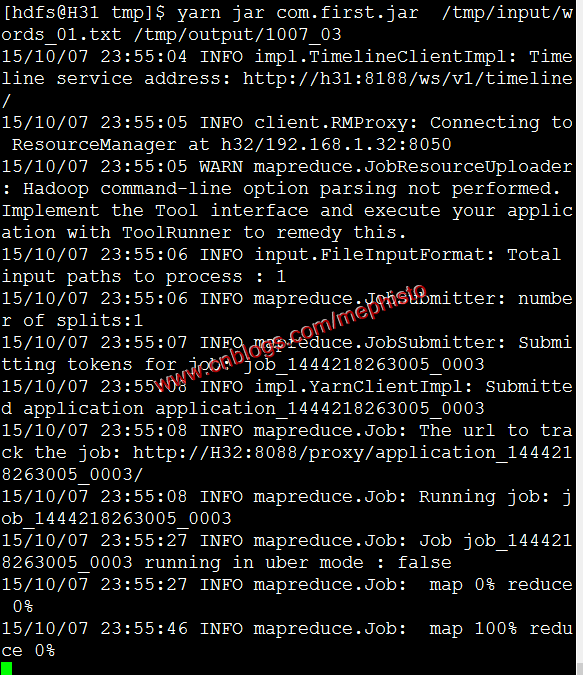
如果是仔细看了,发现少个wordcount对吧,为什么列,因为在导出jar包的时候制定的main函数。
九:导出不指定main入口的jar包
我们在导出的时候,不指定main的入口。十:执行2
我们发现这里就得多带一个参数了,就是方法的入口,这里得全路径。yarn jar com.first.jar com.first.WordCountEx /tmp/input/words_01.txt /tmp/output/1007_04
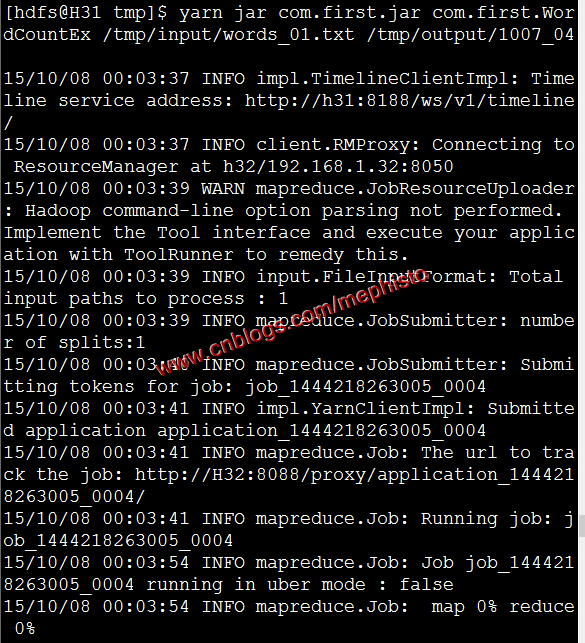
十一:结果
我们看下输出的结果,可以明显的看到少于5个长度的被排除了,而且结果的count都乘以了2。前缀乱码的不要纠结了,换个编码方式就好了。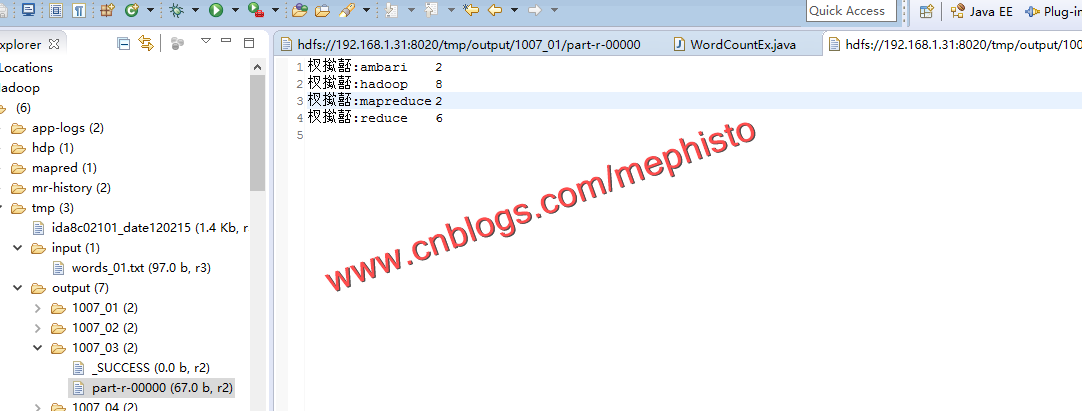
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
示例下载
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink

相关文章推荐
- linux常用小命令
- centos安装g++
- tomcat conf
- SRM 667 DIV2 OrderOfOperationsDiv2 500-point
- java程序执行Linux命令
- 一步步安装nginx搭建流媒体服务器
- Linux系统目录
- Ubuntu必备软件
- Linux_1
- Property属性, KVC键值编码OC…
- Markdown编辑器中改变图片尺寸(eg:haroopad)
- Property属性, KVC键值编码OC…
- 网站论坛同步用户,整合api,实现…
- 网站论坛同步用户,整合api,实现…
- 如何在 Linux 中整理磁盘碎片
- 网站文件夹命名规则
- 如何在 Linux 中整理磁盘碎片
- 如何在 Linux 中整理磁盘碎片
- 通过DNS TXT记录执行powershell
- TomCat用法,常用方法和例子