大数据学习篇:hadoop深入浅出系列之HDFS(七) ——小文件解决方案
2015-09-30 14:24
791 查看
上一篇文章讲了HDFS的java操作,今天讲HDFS的小文件解决方案
小文件指的是那些size比HDFS的block size(默认128M)小的多的文件。任何一个文件,目录和block,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个object占用150 bytes的内存空间。所以,如果有10million个文件,每一个文件对应一个block,那么就将要消耗namenode 3G的内存来保存这些block的信息。如果规模再大一些,那么将会超出现阶段计算机硬件所能满足的极限。
重点说下几种解决方案
1)应用程序自己控制
2)archive
3)Sequence File
4)Map File
5)合并小文件,如HBase部分的compact
6)*CombineFileInputFormat
一)应用程序控制
向hdfs写数据的时候,先把文件都合并在一起了,如果你再想看每个合并的文件,那是不可能的哟
使用情况:如果你每天产生日志文件,但是你需要按月的文件,就可以这样搞
二)archive 归档
Hadoop Archives (HAR files)是在0.18.0版本中引入的,它的出现就是为了缓解大量小文件消耗namenode内存的问题。HAR文件是通过在HDFS上构建一个层次化的文件系统来工作。一个HAR文件是通过hadoop的archive命令来创建,而这个命令实 际上也是运行了一个MapReduce任务来将小文件打包成HAR。对于client端来说,使用HAR文件没有任何影响。所有的原始文件都
(using har://URL)。但在HDFS端它内部的文件数减少了。
通过HAR来读取一个文件并不会比直接从HDFS中读取文件高效,而且实际上可能还会稍微低效一点,因为对每一个HAR文件的访问都需要完成两层 index文件的读取和文件本身数据的读取。并且尽管HAR文件可以被用来作为MapReduce job的input,但是并没有特殊的方法来使maps将HAR文件中打包的文件当作一个HDFS文件处理。
把每个小文件放到一个har包中,如下,首先检查下d1和d2文件夹,发现d1有两个文件 大小分别是1366和19,d2没有文件,现在我们执行har命令
-----------------------------------------------------------------------------

-----------------------------------------------------------------------------
bin/hadoop archive -archiveName test.har -p /d1 /d2
其中test.har 是文件名 d1是要被打包的文件夹 d2是目标文件夹
-----------------------------------------------------------------------------
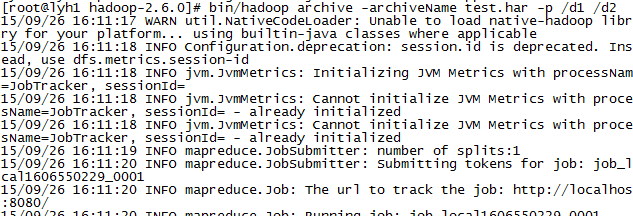
-----------------------------------------------------------------------------
之后,我们回到d2中,查看多了一个test.har文件,再细看一下前面居然是d,代表文件类型是目录
-----------------------------------------------------------------------------

-----------------------------------------------------------------------------
既然是个目录,就可以使用ls查看

-----------------------------------------------------------------------------
我们看到了一个大小为1385的文件,正好是刚才d1中两个文件的大小之和(1366+19),原来只是合并啊,没有压缩,har的作用就是把大量的小文件打包存放
那么是否可以查看合并之和的内容呢。当然可以了
hadoop fs -lsr har:///dest/xxx.har
注:相对于应用程序合并来说,har归档之后的文件打包是可以查看的
三)Sequence File
通常对于“the small files problem”的回应会是:使用SequenceFile。这种方法是说,使用filename作为key,并且file contents作为value。实践中这种方式非常管用。回到10000个100KB的文件,可以写一个程序来将这些小文件写入到一个单独的 SequenceFile中去,然后就可以在一个streaming fashion(directly
or using mapreduce)中来使用这个sequenceFile。不仅如此,SequenceFiles也是splittable的,所以mapreduce 可以break them into chunks,并且分别的被独立的处理。和HAR不同的是,这种方式还支持压缩。block的压缩在许多情况下都是最好的选择,因为它将多个 records压缩到一起,而不是一个record一个压缩。
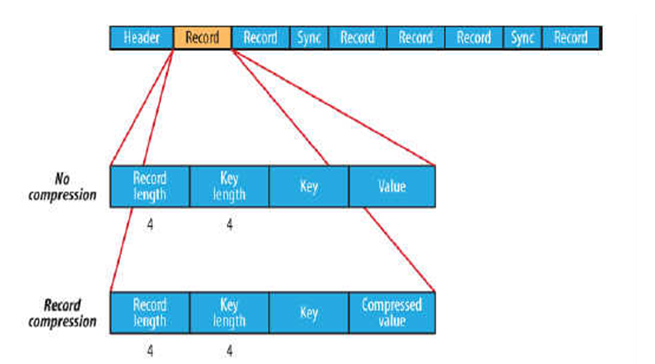
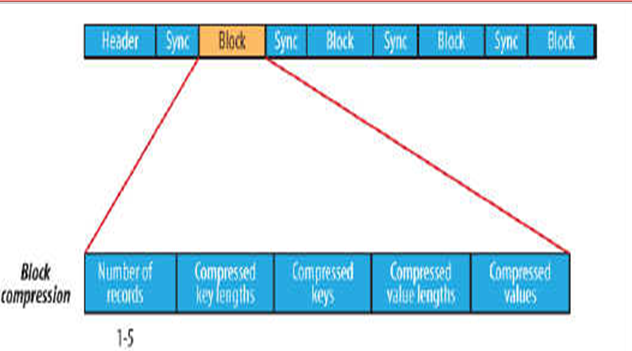
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成。
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如上图。
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的。
SequenceFile是键值对的形式
四)MapFile
MapFile是有序的,方便查找,以前的hadoop的底层用额就是MapFile,现在不是了,但是他依然有意义
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
<span style="font-family:KaiTi_GB2312;font-size:18px;">Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path mapFile=new Path("mapFile.map");
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型
MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
//通过writer向文档中写入记录
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//关闭write流
//Reader内部类用于文件的读取操作
MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
//通过reader从文档中读取记录
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(key);
}
IOUtils.closeStream(reader);//关闭read流
</span>
要放假了,第五和第六条后续补上,敬请关注
上一篇文章讲了HDFS的java操作,今天讲HDFS的小文件解决方案
小文件指的是那些size比HDFS的block size(默认128M)小的多的文件。任何一个文件,目录和block,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个object占用150 bytes的内存空间。所以,如果有10million个文件,每一个文件对应一个block,那么就将要消耗namenode 3G的内存来保存这些block的信息。如果规模再大一些,那么将会超出现阶段计算机硬件所能满足的极限。
重点说下几种解决方案
1)应用程序自己控制
2)archive
3)Sequence File
4)Map File
5)合并小文件,如HBase部分的compact
6)*CombineFileInputFormat
一)应用程序控制
向hdfs写数据的时候,先把文件都合并在一起了,如果你再想看每个合并的文件,那是不可能的哟
<span style="font-family:KaiTi_GB2312;font-size:18px;">final Path path = new Path("/combinedfile");
final FSDataOutputStream create = fs.create(path);
final File dir = new File("C:\\Windows\\System32\\drivers\\etc");
for(File fileName : dir.listFiles()) {
System.out.println(fileName.getAbsolutePath());
final FileInputStream fileInputStream = new FileInputStream(fileName.getAbsolutePath());
final List<String> readLines = IOUtils.readLines(fileInputStream);
for (String line : readLines) {
create.write(line.getBytes());
}
fileInputStream.close();
}
create.close();</span>使用情况:如果你每天产生日志文件,但是你需要按月的文件,就可以这样搞
二)archive 归档
Hadoop Archives (HAR files)是在0.18.0版本中引入的,它的出现就是为了缓解大量小文件消耗namenode内存的问题。HAR文件是通过在HDFS上构建一个层次化的文件系统来工作。一个HAR文件是通过hadoop的archive命令来创建,而这个命令实 际上也是运行了一个MapReduce任务来将小文件打包成HAR。对于client端来说,使用HAR文件没有任何影响。所有的原始文件都
(using har://URL)。但在HDFS端它内部的文件数减少了。
通过HAR来读取一个文件并不会比直接从HDFS中读取文件高效,而且实际上可能还会稍微低效一点,因为对每一个HAR文件的访问都需要完成两层 index文件的读取和文件本身数据的读取。并且尽管HAR文件可以被用来作为MapReduce job的input,但是并没有特殊的方法来使maps将HAR文件中打包的文件当作一个HDFS文件处理。
把每个小文件放到一个har包中,如下,首先检查下d1和d2文件夹,发现d1有两个文件 大小分别是1366和19,d2没有文件,现在我们执行har命令
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
bin/hadoop archive -archiveName test.har -p /d1 /d2
其中test.har 是文件名 d1是要被打包的文件夹 d2是目标文件夹
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
之后,我们回到d2中,查看多了一个test.har文件,再细看一下前面居然是d,代表文件类型是目录
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
既然是个目录,就可以使用ls查看
-----------------------------------------------------------------------------
我们看到了一个大小为1385的文件,正好是刚才d1中两个文件的大小之和(1366+19),原来只是合并啊,没有压缩,har的作用就是把大量的小文件打包存放
那么是否可以查看合并之和的内容呢。当然可以了
hadoop fs -lsr har:///dest/xxx.har
注:相对于应用程序合并来说,har归档之后的文件打包是可以查看的
三)Sequence File
通常对于“the small files problem”的回应会是:使用SequenceFile。这种方法是说,使用filename作为key,并且file contents作为value。实践中这种方式非常管用。回到10000个100KB的文件,可以写一个程序来将这些小文件写入到一个单独的 SequenceFile中去,然后就可以在一个streaming fashion(directly
or using mapreduce)中来使用这个sequenceFile。不仅如此,SequenceFiles也是splittable的,所以mapreduce 可以break them into chunks,并且分别的被独立的处理。和HAR不同的是,这种方式还支持压缩。block的压缩在许多情况下都是最好的选择,因为它将多个 records压缩到一起,而不是一个record一个压缩。
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成。
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如上图。
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的。
SequenceFile是键值对的形式
<span style="font-family:KaiTi_GB2312;font-size:18px;">Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path seqFile=new Path("seqFile.seq");
//Reader内部类用于文件的读取操作
SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型
SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
//通过writer向文档中写入记录
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//关闭write流
//通过reader从文档中读取记录
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(value);
}
IOUtils.closeStream(reader);//关闭read流</span><span style="font-family:KaiTi_GB2312;font-size:18px;"> </span>
四)MapFile
MapFile是有序的,方便查找,以前的hadoop的底层用额就是MapFile,现在不是了,但是他依然有意义
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
<span style="font-family:KaiTi_GB2312;font-size:18px;">Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path mapFile=new Path("mapFile.map");
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型
MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
//通过writer向文档中写入记录
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//关闭write流
//Reader内部类用于文件的读取操作
MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
//通过reader从文档中读取记录
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(key);
}
IOUtils.closeStream(reader);//关闭read流
</span>
要放假了,第五和第六条后续补上,敬请关注

相关文章推荐
- JBoss AS7中的新概念-Domain[master配置domain.xml和host.xml和自己的管理员账号以及用于slave连接验证的账号,slave只需要配置host.xml配置文件即可]
- P22 (*) Create a list containing all integers within a given range
- usaco Drainage Ditches
- @property中retain assign copy详解
- freeswitch语音信箱(Voice Mail)功能调试
- RAID 级别和特征
- Loadrunner:场景运行较长时间后报错:Message id [-17999] was not saved - Auto Log cache is too small to contain the message.
- Loadrunner:error -86401 Failed to connceted xxx.xxx.xxx.xxx:25问题解决
- Loadrunner:场景运行较长时间后报错:Message id [-17999] was not saved - Auto Log cache is too small to contain the message.
- 数据挖掘十大经典算法
- saiku中默认页改为“打开查询”
- Cannot retrieve metalink for repository: epel. Please verify its path and try again
- Jolla 正式发布 Sailfish OS 2.0
- 关于微赞,微擎,微动力模块安装时出现 版权保护,未在云平台注册 的解决办法
- Light oj 1252 - Maintaining Communities(树形dp)
- hdu 5469 Antonidas (dfs+剪枝)2015 ACM/ICPC Asia Regional Shanghai Online
- 基于大数据的精准营销咨询
- 【bzoj1260】 [CQOI2007]涂色paint
- 【POJ 3007】 Organize Your Train part II (字符串HASH)
- 【DATAGUARD】物理dg配置客户端无缝切换 (八.2)--Fast-Start Failover 的配置