speech or no speech detection
2015-09-27 23:10
423 查看
http://python.developermemo.com/668_18026120/ speech or no speech detection
http://ibillxia.github.io/blog/2013/05/22/audio-signal-processing-time-domain-Voice-Activity-Detection/
端点检测(End-Point Detection,EPD)的目标是要决定信号的语音开始和结束的位置,所以又可以称为Speech Detection或Voice Activity Detection(VAD)。 端点检测在语音预处理中扮演着一个非常重要的角色。
常见的端点检测方法大致可以分为如下两类:
(1)时域(Time Domain)的方法:计算量比较小,因此比较容易移植到计算能力较差的嵌入式平台
(a)音量:只使用音量来进行端检,是最简单的方法,但是容易对清音造成误判。另外,不同的音量计算方法得到的结果也不尽相同,至于那种方法更好也没有定论。
(b)音量和过零率:以音量为主,过零率为辅,可以对清音进行较精密的检测。
(2)频域(Frequency Domain)的方法:计算量相对较大。
(a)频谱的变化性(Variance):有声音的频谱变化较规律,可以作为一个判断标准。
(b)频谱的Entropy:有规律的频谱的Entropy一般较小,这也可以作为一个端检的判断标准。
下面我们分别从这两个方面来探讨端检的具体方法和过程。
时域的端检方法分为只用音量的方法和同时使用音量和过零率的方法。只使用音量的方法最简单计算量也最小,我们只需要设定一个音量阈值,任何音量小于该阈值的帧 被认为是静音(silence)。这种方法的关键在于如何选取这个阈值,一种常用的方法是使用一些带标签的数据来训练得到一个阈值,使得误差最小。
下面我们来看看最简单的、不需要训练的方法,其代码如下:
其中计算音量的函数calVolume参见 音量及其Python实现一文。程序的运行结果如下图:
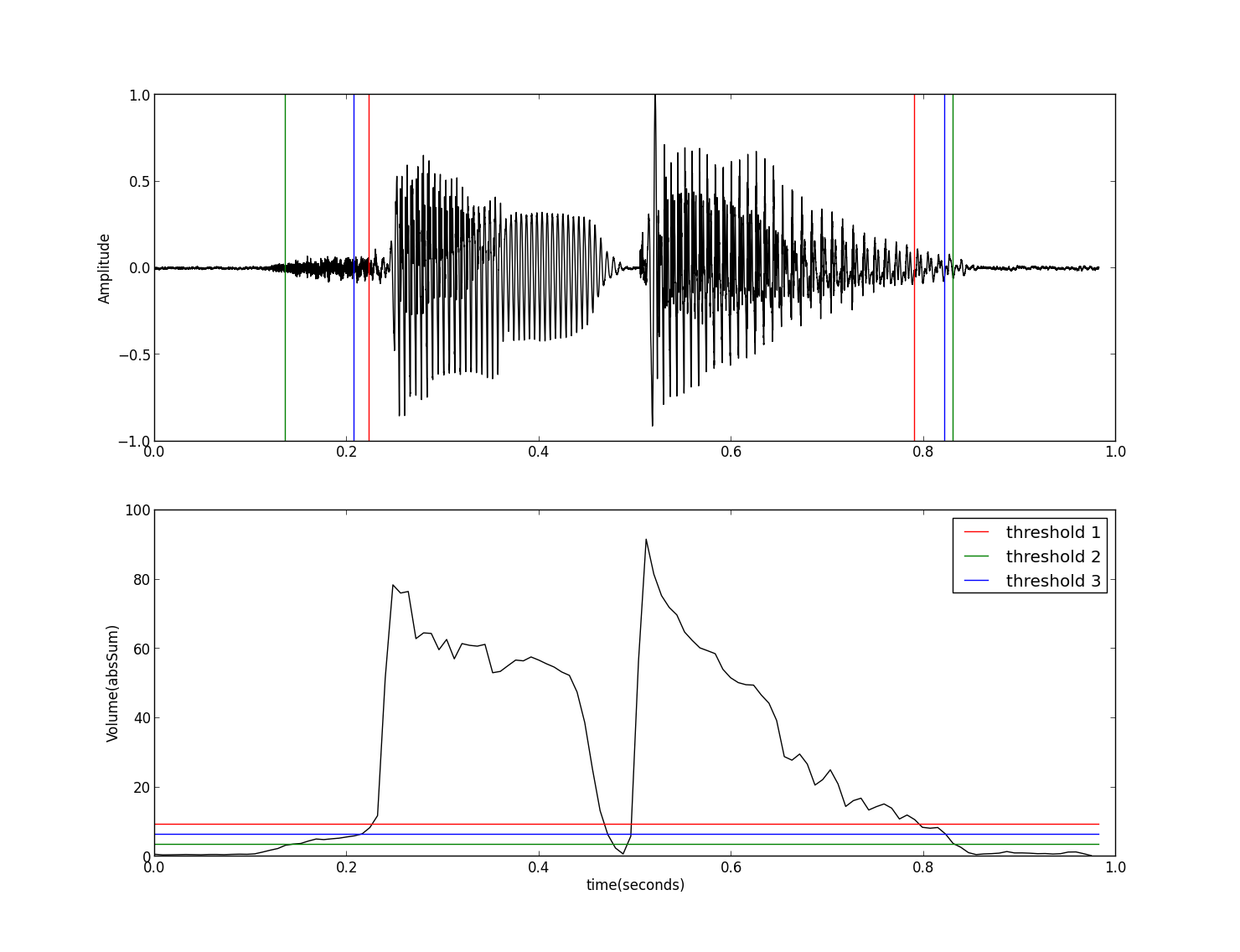
这里采用了三种设置阈值的方法,但这几种设置方法对所有的输入都是相同的,对于一些特定的语音数据可能得不到很好的结果,比如杂音较强、清音较多或音量 变化较大等语音信号,此时单一阈值的方法的效果就不太好了,虽然我们可以通过增加帧与帧之间的重叠部分,但相对而言计算量会比较大。下面我们利用一些更多的 特征来进行端点加测,例如使用过零率等信息,其过程如下:
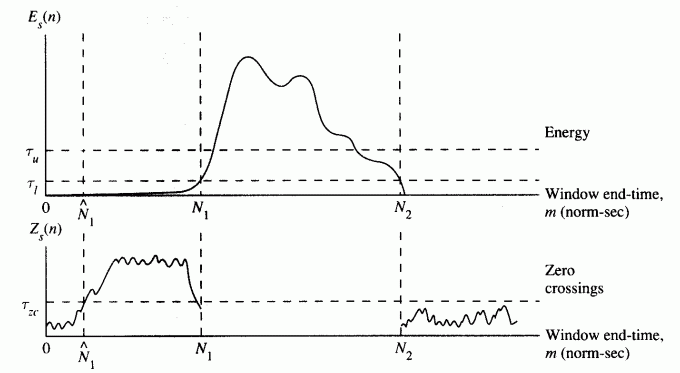
(1)以较高音量阈值(τu)为标准,找到初步的端点;
(2)将端点前后延伸到低音量阈值(τl)处;
(3)再将端点前后延伸到过零率阈值(τzc)处,以包含语音中清音的部分。
这种方法需要确定三个阈值(τu,τl,τzc),可以用各种搜寻方法来调整这三个参数。其示意图(参考[1])如下:
我们在同一个图中绘制出音量和过零率的阈值图如下:
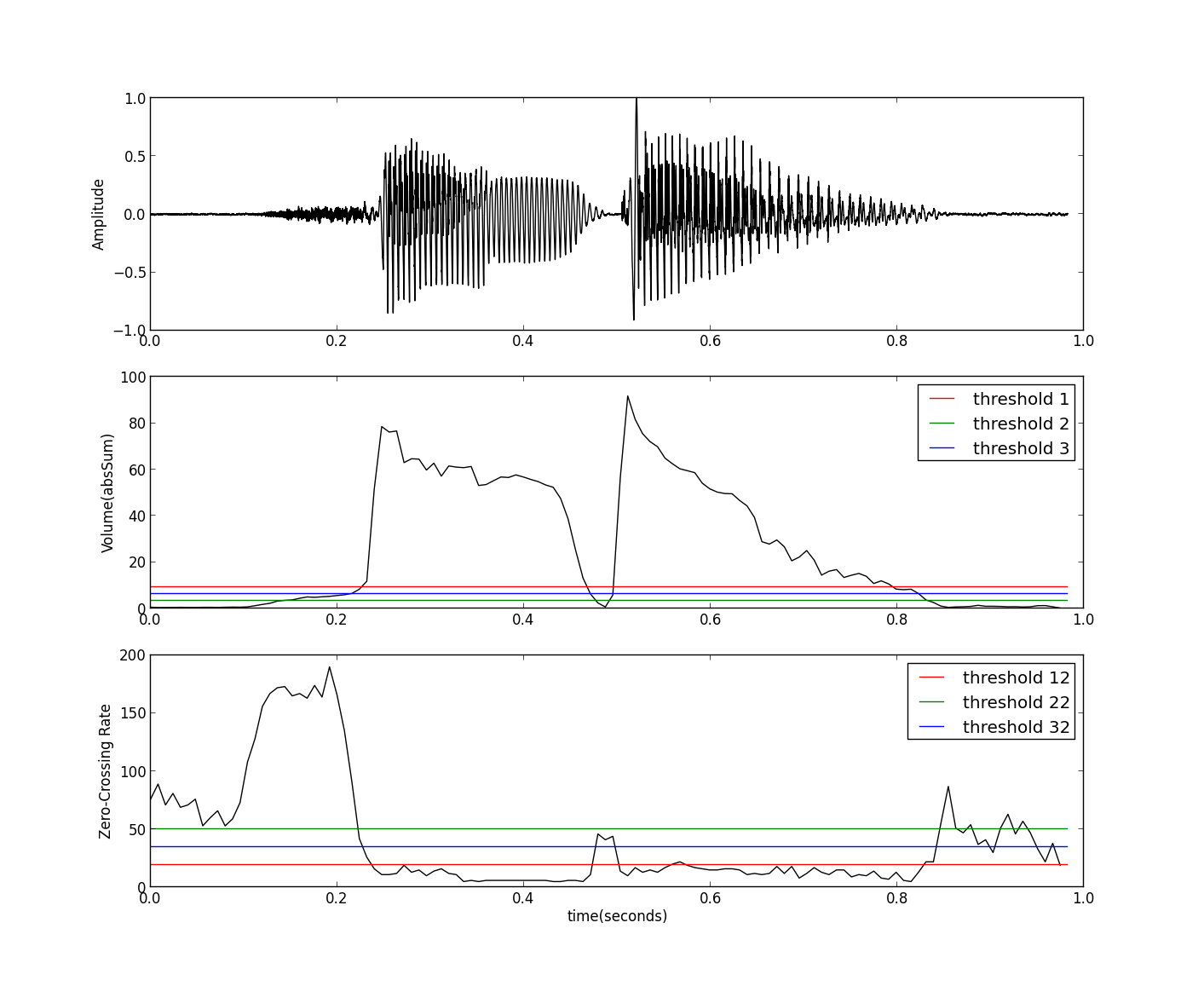
可以看到我们可以通过过零率的阈值来把错分的清音加入到语音部分来。上图使用到的阈值还是和音量的阈值选取方法相同,比较简单直接。
另外,我们还可以连续对波形进行微分,再计算音量,这样就可以凸显清音的部分,从而将其正确划分出来,详见参考[1]。
有声音的信号在频谱上会有重复的谐波结构,因此我们也可以使用频谱的变化性(Variation)或Entropy来进行端点检测,可以参见如下链接: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/paper/endPointDetection/ 总之,端点检测是语音预处理的重头戏,其实现方法也是五花八门,本文只给出了最简单最原始也最好理解的几种方法,这些方法要真正做到实用,还需要针对一些 特殊的情况在做一些精细的设置和处理,但对于一般的应用场景应该还是基本够用的。
[1]EPD in Time Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdTimeDomain.asp?title=6-2%20EPD%20in%20Time%20Domain
[2]EPD in Frequency Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdFreqDomain.asp?title=6-3%20EPD%20in%20Frequency%20Domain
Original Link: http://ibillxia.github.io/blog/2013/05/22/audio-signal-processing-time-domain-Voice-Activity-Detection/
Attribution - NON-Commercial - ShareAlike - Copyright © Bill Xia
Posted by Bill Xia May
22nd, 2013 Posted in ASSP Tagged with Python, Speech, 信号处理, 端点检测
jakang • 2
years ago
楼主,最近我也在看VAD,关于你的findIndex函数的作用,不知道我的理解对不对:遍历每一帧的音量值,如果遇到不满足阙值的帧,就把帧号放到index数组里?但我在运行这段程序时出错了,麻烦问下findIndex函数是不是有问题?
def findIndex(vol,thres):
l = len(vol)
ii = 0
index = np.zeros(4,dtype=np.int16) # index是一个4个元素的数组
for i in range(l-1): # vol数组的长度一般都肯定大于4
if((vol[i]-thres)*(vol[i+1]-thres)<0):
index[ii]=i # ii的递增在for循环内,当有4个以上符合条件的值时,
ii = ii+1 # index数组肯定会out of boundary吧。
return index[[0,-1]]
•
Reply
•
Share ›

Bill Xia Mod jakang • 2
years ago
这里只是一个简单的示例而已,index数组只包含4个元素不一定对所有语音文件都实用,其实用list或许更合理,可以动态扩展列表的大小。
这篇文章当时主要是参考以下教程来写的:
http://neural.cs.nthu.edu.tw/j...
•
Reply
•
Share ›

jakang Bill
Xia • 2
years ago
感谢回复,我用了list来动态扩展,效果不错。以后有语音方面的问题还麻烦你多指教:)。
•
Reply
•
Share ›
Bill Xia Mod jakang • 2
years ago
嗯,互相学习 ^-^
•
Reply
•
Share ›
http://ibillxia.github.io/blog/2013/05/22/audio-signal-processing-time-domain-Voice-Activity-Detection/
语音信号处理之时域分析-端点检测及Python实现
import audioop
import pyaudio as pa
import wav
class speech():
def __init__(self):
# soundtrack properties
self.format = pa.paInt16
self.rate = 16000
self.channel = 1
self.chunk = 1024
self.threshold = 150
self.file = 'audio.wav'
# intialise microphone stream
self.audio = pa.PyAudio()
self.stream = self.audio.open(format=self.format,
channels=self.channel,
rate=self.rate,
input=True,
frames_per_buffer=self.chunk)
def record(self)
while True:
data = self.stream.read(self.chunk)
rms = audioop.rms(data,2) #get input volume
if rms>self.threshold: #if input volume greater than threshold
break
# array to store frames
frames = []
# record upto silence only
while rms>threshold:
data = self.stream.read(self.chunk)
rms = audioop.rms(data,2)
frames.append(data)
print 'finished recording.... writing file....'
write_frames = wav.open(self.file, 'wb')
write_frames.setnchannels(self.channel)
write_frames.setsampwidth(self.audio.get_sample_size(self.format))
write_frames.setframerate(self.rate)
write_frames.writeframes(''.join(frames))
write_frames.close()| Is there a way I can differentiate between human voice and other noise in Python ? Hope somebody can find me a solution. | |
|
| I think that your issue is that at the moment you are trying to record without recognition of the speech so it is not discriminating - recognisable speech is anything that gives meaningful results after recognition - so catch 22. You could simplify matters by looking for an opening keyword. You can also filter on voice frequency range as the human ear and the telephone companies both do and you can look at the mark space ratio - I believe that there were some publications a while back on that but look out - it varies from language to language. A quick Google can be very informative. You may also find this article interesting. | |||
|
| I think waht you are looking for is VAD (voice activity detection). VAD can be used for preprocessing speech for ASR. Here is some open-source project for implements of VAD link. May it help you. |
端点检测
端点检测(End-Point Detection,EPD)的目标是要决定信号的语音开始和结束的位置,所以又可以称为Speech Detection或Voice Activity Detection(VAD)。 端点检测在语音预处理中扮演着一个非常重要的角色。常见的端点检测方法大致可以分为如下两类:
(1)时域(Time Domain)的方法:计算量比较小,因此比较容易移植到计算能力较差的嵌入式平台
(a)音量:只使用音量来进行端检,是最简单的方法,但是容易对清音造成误判。另外,不同的音量计算方法得到的结果也不尽相同,至于那种方法更好也没有定论。
(b)音量和过零率:以音量为主,过零率为辅,可以对清音进行较精密的检测。
(2)频域(Frequency Domain)的方法:计算量相对较大。
(a)频谱的变化性(Variance):有声音的频谱变化较规律,可以作为一个判断标准。
(b)频谱的Entropy:有规律的频谱的Entropy一般较小,这也可以作为一个端检的判断标准。
下面我们分别从这两个方面来探讨端检的具体方法和过程。
时域的端检方法
时域的端检方法分为只用音量的方法和同时使用音量和过零率的方法。只使用音量的方法最简单计算量也最小,我们只需要设定一个音量阈值,任何音量小于该阈值的帧 被认为是静音(silence)。这种方法的关键在于如何选取这个阈值,一种常用的方法是使用一些带标签的数据来训练得到一个阈值,使得误差最小。下面我们来看看最简单的、不需要训练的方法,其代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | import wave
import numpy as np
import matplotlib.pyplot as plt
import Volume as vp
def findIndex(vol,thres):
l = len(vol)
ii = 0
index = np.zeros(4,dtype=np.int16)
for i in range(l-1):
if((vol[i]-thres)*(vol[i+1]-thres)<0):
index[ii]=i
ii = ii+1
return index[[0,-1]]
fw = wave.open('sunday.wav','r')
params = fw.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
strData = fw.readframes(nframes)
waveData = np.fromstring(strData, dtype=np.int16)
waveData = waveData*1.0/max(abs(waveData)) # normalization
fw.close()
frameSize = 256
overLap = 128
vol = vp.calVolume(waveData,frameSize,overLap)
threshold1 = max(vol)*0.10
threshold2 = min(vol)*10.0
threshold3 = max(vol)*0.05+min(vol)*5.0
time = np.arange(0,nframes) * (1.0/framerate)
frame = np.arange(0,len(vol)) * (nframes*1.0/len(vol)/framerate)
index1 = findIndex(vol,threshold1)*(nframes*1.0/len(vol)/framerate)
index2 = findIndex(vol,threshold2)*(nframes*1.0/len(vol)/framerate)
index3 = findIndex(vol,threshold3)*(nframes*1.0/len(vol)/framerate)
end = nframes * (1.0/framerate)
plt.subplot(211)
plt.plot(time,waveData,color="black")
plt.plot([index1,index1],[-1,1],'-r')
plt.plot([index2,index2],[-1,1],'-g')
plt.plot([index3,index3],[-1,1],'-b')
plt.ylabel('Amplitude')
plt.subplot(212)
plt.plot(frame,vol,color="black")
plt.plot([0,end],[threshold1,threshold1],'-r', label="threshold 1")
plt.plot([0,end],[threshold2,threshold2],'-g', label="threshold 2")
plt.plot([0,end],[threshold3,threshold3],'-b', label="threshold 3")
plt.legend()
plt.ylabel('Volume(absSum)')
plt.xlabel('time(seconds)')
plt.show() |
这里采用了三种设置阈值的方法,但这几种设置方法对所有的输入都是相同的,对于一些特定的语音数据可能得不到很好的结果,比如杂音较强、清音较多或音量 变化较大等语音信号,此时单一阈值的方法的效果就不太好了,虽然我们可以通过增加帧与帧之间的重叠部分,但相对而言计算量会比较大。下面我们利用一些更多的 特征来进行端点加测,例如使用过零率等信息,其过程如下:
(1)以较高音量阈值(τu)为标准,找到初步的端点;
(2)将端点前后延伸到低音量阈值(τl)处;
(3)再将端点前后延伸到过零率阈值(τzc)处,以包含语音中清音的部分。
这种方法需要确定三个阈值(τu,τl,τzc),可以用各种搜寻方法来调整这三个参数。其示意图(参考[1])如下:
我们在同一个图中绘制出音量和过零率的阈值图如下:
可以看到我们可以通过过零率的阈值来把错分的清音加入到语音部分来。上图使用到的阈值还是和音量的阈值选取方法相同,比较简单直接。
另外,我们还可以连续对波形进行微分,再计算音量,这样就可以凸显清音的部分,从而将其正确划分出来,详见参考[1]。
频域的端检方法
有声音的信号在频谱上会有重复的谐波结构,因此我们也可以使用频谱的变化性(Variation)或Entropy来进行端点检测,可以参见如下链接: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/paper/endPointDetection/ 总之,端点检测是语音预处理的重头戏,其实现方法也是五花八门,本文只给出了最简单最原始也最好理解的几种方法,这些方法要真正做到实用,还需要针对一些 特殊的情况在做一些精细的设置和处理,但对于一般的应用场景应该还是基本够用的。
参考(References)
[1]EPD in Time Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdTimeDomain.asp?title=6-2%20EPD%20in%20Time%20Domain [2]EPD in Frequency Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdFreqDomain.asp?title=6-3%20EPD%20in%20Frequency%20Domain
Original Link: http://ibillxia.github.io/blog/2013/05/22/audio-signal-processing-time-domain-Voice-Activity-Detection/
Attribution - NON-Commercial - ShareAlike - Copyright © Bill Xia
Posted by Bill Xia May
22nd, 2013 Posted in ASSP Tagged with Python, Speech, 信号处理, 端点检测
jakang • 2
years ago
楼主,最近我也在看VAD,关于你的findIndex函数的作用,不知道我的理解对不对:遍历每一帧的音量值,如果遇到不满足阙值的帧,就把帧号放到index数组里?但我在运行这段程序时出错了,麻烦问下findIndex函数是不是有问题?
def findIndex(vol,thres):
l = len(vol)
ii = 0
index = np.zeros(4,dtype=np.int16) # index是一个4个元素的数组
for i in range(l-1): # vol数组的长度一般都肯定大于4
if((vol[i]-thres)*(vol[i+1]-thres)<0):
index[ii]=i # ii的递增在for循环内,当有4个以上符合条件的值时,
ii = ii+1 # index数组肯定会out of boundary吧。
return index[[0,-1]]
•
Reply
•
Share ›
Bill Xia Mod jakang • 2
years ago
这里只是一个简单的示例而已,index数组只包含4个元素不一定对所有语音文件都实用,其实用list或许更合理,可以动态扩展列表的大小。
这篇文章当时主要是参考以下教程来写的:
http://neural.cs.nthu.edu.tw/j...
•
Reply
•
Share ›
jakang Bill
Xia • 2
years ago
感谢回复,我用了list来动态扩展,效果不错。以后有语音方面的问题还麻烦你多指教:)。
•
Reply
•
Share ›
Bill Xia Mod jakang • 2
years ago
嗯,互相学习 ^-^
•
Reply
•
Share ›

相关文章推荐
- 机器学习读书笔记01 机器学习基础
- Java 信号量 Semaphore 介绍
- While中语句执行顺序的问题
- 我对Linux/Unix中的权限的理解
- 编写html时需要注意的.....
- html普通列表
- #include&lt;algorithm&gt;里的函…
- Fedora安装Wine
- Fedora获取权限命令
- ./configure,make,make&nbsp;insta…
- fedora&nbsp;学习笔记
- VMware中安装Debian&nbsp;linux暨…
- 2014.8.9日安装CentOS随记
- 宽带我世界和win8、win8.1的兼容性…
- Windows下自动编辑保存的文本文档…
- Windows下自动编辑保存的文本文档…
- linux下编辑的文本文档图标在Windo…
- KDE中文
- 关于VS2013中scanf()函数的C4996错…
- .obj文件