分析OpenCV图像输入输出基本框架
2015-09-23 21:57
615 查看
分析OpenCV图像输入输出基本框架
转载▼
opencv其实是使用第三方库来对输入和输出图像格式进行解析,那么这个过程是怎么实现的?本着追根溯源的hack精神,让我们一起探索一番,首先看一下一般的图像处理过程:
一个典型的计算机视觉算法,应该包含以下一些步骤:
(1)数据获取(对OpenCV来说,就是图片);
(2)预处理;
(3)特征提取;
(4)特征选择;
(5)分类器设计与训练;
(6)分类判别;
而OpenCV对这六个部分,分别提供了API(这些API是相互独立的,但是共享一个图像基本数据结构)。其实其他的信号系统为基础的处理库也差不多是这个形式。
opencv中使用了图像的读取引擎来实现对不同输入图像文件的解析获得数据区以及图像的基本信息等,以读入图像文件为例,opencv使用文件读入操作将硬盘上的文件读入内存,然后判断文件头中的前几个字节信息来确定读入的文件是否是图像和该图像的类型,然后调用相关的图像解码引擎来对图像文件解析,获取长宽,颜色信息等内容,具体的流程是:
源代码位于:C:\opencv_vs2008\2.3.1\modules\highgui\src
1.C:\opencv_vs2008\2.3.1\modules\highgui\src\loadsave.cpp这个文件提供了基本的读入和写出函数的实现:
读入函数:
Matimread( conststring& filename,int flags )
{
Matimg;
imread_(filename, flags,LOAD_MAT,
&img );
returnimg;
}
写出函数:
boolimwrite( conststring& filename,InputArray _img,constvector<<SPAN
style="COLOR: #0000ff">int>¶ms )
{
Matimg = _img.getMat();
returnimwrite_(filename,img, params,false);
}
其中的
imread_(filename, flags,LOAD_MAT,
&img );
imwrite_(filename,img, params, false);
是其实现的具体函数,使用了ImageDecoder 和ImageEncoder引擎来解析和存储图像文件。
2.C:\opencv_vs2008\2.3.1\modules\highgui\src\grfmt_base.hpp和C:\opencv_vs2008\2.3.1\modules\highgui\src\grfmt_base.cpp
实现了虚基类ImageDecoder 和ImageEncoder,在这个类中统一调用需要的图像文件解码器:
在这个类中使用了智能指针:
typedefPtr<<SPAN
style="COLOR: #010001">BaseImageEncoder>ImageEncoder;
typedefPtr<<SPAN
style="COLOR: #010001">BaseImageDecoder>ImageDecoder;
分析找出了Ptr的出处:c:\opencv_vs2008\2.3.1\include\opencv2\core\core.hpp的1223行
如下:
//////////////////// generic_type ref-counting pointer class for C/C++ objects ////////////////////////
template<</SPAN>typename_Tp> classCV_EXPORTS Ptr
{
public:
//! empty constructor
Ptr();
//! take ownership of the pointer. The associated reference counter is allocated
and set to 1
Ptr(_Tp*_obj);
//! calls release()
~Ptr();
//! copy constructor. Copies the members and calls addref()
Ptr(constPtr& ptr);
//! copy operator. Calls ptr.addref() and release() before copying the members
Ptr&operator =
(constPtr& ptr);
//! increments the reference counter
voidaddref();
//! decrements the reference counter. If it reaches 0, delete_obj() is called
voidrelease();
//! deletes the object. Override if needed
voiddelete_obj();
//! returns true iff obj==NULL
boolempty() const;
//! helper operators making "Ptr ptr" use very similar to "T* ptr".
_Tp*operator ->
();
const_Tp* operator ->
()const;
operator_Tp*
();
operatorconst _Tp*()const;
protected:
_Tp*obj; //<
the object pointer.
int*refcount; //<
the associated reference counter
};
结合网上资源:http://hi.baidu.com/maxint/blog/item/fc817c2f29881f331e3089ef.html
知道了openCV2.0以后使用了安全指针(也叫智能指针)Ptr template。据说这个是参考了C++0x和Boost库的相关技术。
简单地说,就是加了个指针引用数(refcount)和一些方便调用的操作符重装(operator ->;())。值得注意的是,Ptr template 对指针指向的对象有一个要求,就是可以用 delete 操作土符来释放内存。你可能就想到 IplImage 就不满足这个要求了,这怎么办?可以使用模板特化(template specialization)重载
Ptr::delete_obj() 函数:
template<> inline void Ptr::delete_obj()
{ cvReleaseImage(&obj); }PS:考虑到多线程时,CV2.0中的一些基本操作(如加法运算CV_ADD)都写成了函数或宏,保证互斥资源访问安全,看源代码时可注意下。
到这个时候就知道了ImageEncoder 和ImageDecoder 就是纯虚基类的智能指针模板了,而且BaseImageDecoder 和BaseImageEncoder 着两个纯虚基类提供了相关的解码引擎函数的接口,主要有:
///////////////////////////////// base class for decoders ////////////////////////
classBaseImageDecoder
{
public:
BaseImageDecoder();
virtual ~BaseImageDecoder()
{};
intwidth() const {return m_width;
};
intheight() const {return m_height;
};
virtualint type() const { return m_type;
};
virtualbool setSource(const string&filename );
virtualbool setSource(const Mat& buf );
virtualbool readHeader()
= 0;
virtualbool readData(Mat& img )
= 0;
virtualsize_t signatureLength()const;
virtualbool checkSignature(const string&signature ) const;
virtualImageDecoder newDecoder()const;
protected:
intm_width; //
width of the image ( filled by readHeader )
intm_height; //
height of the image ( filled by readHeader )
intm_type;
stringm_filename;
stringm_signature;
Matm_buf;
boolm_buf_supported;
};
///////////////////////////// base class for encoders ////////////////////////////
classBaseImageEncoder
{
public:
BaseImageEncoder();
virtual ~BaseImageEncoder()
{};
virtualbool isFormatSupported(int depth )const;
virtualbool setDestination(const string&filename );
virtualbool setDestination(vector<<SPAN
style="COLOR: #010001">uchar>&buf );
virtualbool write(const Mat& img, const vector<<SPAN
style="COLOR: #0000ff">int>¶ms ) = 0;
virtualstring getDescription()const;
virtualImageEncoder newEncoder()const;
protected:
stringm_description;
stringm_filename;
vector<<SPAN style="COLOR: #010001">uchar>*m_buf;
boolm_buf_supported;
};
以上这些纯虚接口,然后不同的图像文件采用不同的文件解析引擎来得到具体的图像数据;
3.回到C:\opencv_vs2008\2.3.1\modules\highgui\src\loadsave.cpp中查看具体的引擎是怎么调用的:
首先看imread中的imread_函数是怎么执行的:
imread_(const string&filename, intflags, inthdrtype, Mat*mat=0
)
{
IplImage*image =
0;
CvMat *matrix =
0;
Mattemp,
*data = &temp;
ImageDecoderdecoder = findDecoder(filename);
if(decoder.empty()
)
return 0;
decoder->setSource(filename);
if( !decoder->readHeader()
)
return 0;
CvSizesize;
size.width =decoder->width();
size.height =decoder->height();
inttype = decoder->type();
if(flags !=
-1 )
{
if( (flags &CV_LOAD_IMAGE_ANYDEPTH)
== 0 )
type =CV_MAKETYPE(CV_8U,CV_MAT_CN(type));
if( (flags &CV_LOAD_IMAGE_COLOR)
!= 0 ||
((flags &CV_LOAD_IMAGE_ANYCOLOR)
!= 0 && CV_MAT_CN(type) > 1) )
type =CV_MAKETYPE(CV_MAT_DEPTH(type),
3);
else
type =CV_MAKETYPE(CV_MAT_DEPTH(type),
1);
}
if(hdrtype == LOAD_CVMAT ||hdrtype == LOAD_MAT )
{
if(hdrtype == LOAD_CVMAT )
{
matrix =cvCreateMat( size.height,size.width,type );
temp =cvarrToMat(matrix);
}
else
{
mat->create(size.height,size.width,type );
data =mat;
}
}
else
{
image =cvCreateImage( size,cvIplDepth(type),CV_MAT_CN(type)
);
temp =cvarrToMat(image);
}
if( !decoder->readData(
*data ))
{
cvReleaseImage( &image );
cvReleaseMat( &matrix );
if(mat )
mat->release();
return 0;
}
returnhdrtype == LOAD_CVMAT ?
(void*)matrix :
hdrtype ==LOAD_IMAGE ?
(void*)image : (void*)mat;
}
其中的关键函数:
ImageDecoderdecoder = findDecoder(filename);
从文件名获取了这个图像文件的解码引擎,现在分析这个函数:
staticvector<<SPAN
style="COLOR: #010001">ImageDecoder>decoders;
ImageDecoderfindDecoder( conststring& filename )
{
size_ti, maxlen =
0;
for(i =
0; i < decoders.size(); i++
)
{
size_tlen = decoders[i]->signatureLength();
maxlen =std::max(maxlen,len);
}
FILE*f= fopen( filename.c_str(), "rb" );
if( !f )
returnImageDecoder();
stringsignature(maxlen,'
');
maxlen =fread(
&signature[0], 1,maxlen, f );
fclose(f);
signature =signature.substr(0,maxlen);
for(i =
0; i < decoders.size(); i++
)
{
if(decoders[i]->checkSignature(signature)
)
returndecoders[i]->newDecoder();
}
returnImageDecoder();
}
首先判断当前解码引擎容器中有多少个引擎,然后获取最大的文件后缀名(这个地方的decoders[i]->signatureLength()是不是后缀来?)的长度为maxlen :
for(i =
0; i < decoders.size(); i++
)
{
size_tlen = decoders[i]->signatureLength();
maxlen =std::max(maxlen,len);
}
接着打开这个文件,从文件头读取maxlen 长度的二进制信息到signature这个数组中,关闭文件:
FILE*f= fopen( filename.c_str(), "rb" );
if( !f )
returnImageDecoder();
stringsignature(maxlen,'
');
maxlen =fread(
&signature[0], 1,maxlen, f );
fclose(f);
接着获取这个字符串的长度为maxlen的字串作为关键词:
signature =signature.substr(0,maxlen);
最后依次从解码引擎中寻找对应图像的解码引擎,然后生成这个引擎的一个实例并且返回:
decoders[i]->checkSignature(signature);
decoders[i]->newDecoder();
returnImageDecoder();
这样就完成了对于某一种图像格式的解码引擎的查找和初始化。
回到imread_(const string&filename, intflags, inthdrtype, Mat*mat=0
)中继续查看怎么获取图像的信息:
首先用decoder->setSource(filename); //通过文件名获取图像
decoder->readHeader();//获取文件头信息
CvSizesize;
size.width =decoder->width();
size.height =decoder->height();
inttype = decoder->type(); //获取文件的长宽和图像数据类型
然后用这些长和宽信息申请内存空间:
matrix =cvCreateMat( size.height,size.width,type );
mat->create(size.height,size.width,type );
image =cvCreateImage( size,cvIplDepth(type),CV_MAT_CN(type)
);
最后得到图像的数据区:
decoder->readData(
*data ) ;
接下来释放一些临时资源就OK了,这样一幅图像就读入内存并且生成为opencv特有的格式mat了。
而这个Mat结构的生成也是直接向这个缓存区填写图像数据得到的。
4.一些细节方面的东西:
查看一个具体的读图引擎BMP位图的:
C:\opencv_vs2008\2.3.1\modules\highgui\src\grfmt_bmp.hpp
C:\opencv_vs2008\2.3.1\modules\highgui\src\grfmt_bmp.cpp
(1)获取特征码:
staticconst char*fmtSignBmp = "BM";
m_signature =fmtSignBmp;
然后纯虚函数接口中规定:
size_tBaseImageDecoder::signatureLength()const
{
returnm_signature.size();
}
返回的是m_signature的长度,也就是这个文件中的"BM"的长度作为特征码。
(2)读取文件的方式:
分析读取bmp位图文件头信息的代码:
boolBmpDecoder::readHeader()
{
boolresult = false;
booliscolor = false;
if( !m_buf.empty()
)
{
if( !m_strm.open(m_buf )
)
returnfalse;
}
elseif(
!m_strm.open(m_filename ))
returnfalse;
try
{
m_strm.skip(
10 );
m_offset =m_strm.getDWord();
intsize = m_strm.getDWord();
if(size >=
36 )
{
m_width =m_strm.getDWord();
m_height =m_strm.getDWord();
m_bpp =m_strm.getDWord()
>> 16;
m_rle_code = (BmpCompression)m_strm.getDWord();
m_strm.skip(12);
intclrused = m_strm.getDWord();
m_strm.skip(size -
36 );
if(m_width >
0 && m_height != 0 &&
(((m_bpp == 1 ||m_bpp ==
4 || m_bpp == 8 ||
m_bpp == 24 ||m_bpp ==
32 ) && m_rle_code ==BMP_RGB) ||
(m_bpp == 16 && (m_rle_code ==BMP_RGB || m_rle_code ==BMP_BITFIELDS))
||
(m_bpp == 4 &&m_rle_code == BMP_RLE4)
||
(m_bpp == 8 &&m_rle_code == BMP_RLE8)))
{
iscolor =true;
result =true;
if(m_bpp <=
8 )
{
memset(m_palette,
0, sizeof(m_palette));
m_strm.getBytes(m_palette,
(clrused == 0? 1<<m_bpp :clrused)*4
);
iscolor =IsColorPalette( m_palette,m_bpp );
}
elseif( m_bpp ==
16 &&m_rle_code == BMP_BITFIELDS )
{
intredmask = m_strm.getDWord();
intgreenmask = m_strm.getDWord();
intbluemask = m_strm.getDWord();
if(bluemask ==
0x1f && greenmask == 0x3e0 && redmask == 0x7c00 )
m_bpp = 15;
elseif( bluemask ==
0x1f &&greenmask == 0x7e0 && redmask == 0xf800 )
;
else
result =false;
}
elseif( m_bpp ==
16 &&m_rle_code == BMP_RGB )
m_bpp = 15;
}
}
elseif( size ==
12 )
{
m_width =m_strm.getWord();
m_height =m_strm.getWord();
m_bpp =m_strm.getDWord()
>> 16;
m_rle_code =BMP_RGB;
if(m_width >
0 && m_height != 0 &&
(m_bpp == 1 ||m_bpp ==
4 || m_bpp == 8 ||
m_bpp == 24 ||m_bpp ==
32 ))
{
if(m_bpp <=
8 )
{
ucharbuffer[256*3];
intj, clrused =
1 <<m_bpp;
m_strm.getBytes(buffer, clrused*3
);
for(j =
0; j < clrused; j++ )
{
m_palette[j].b =buffer[3*j+0];
m_palette[j].g =buffer[3*j+1];
m_palette[j].r =buffer[3*j+2];
}
}
result =true;
}
}
}
catch(...)
{
}
m_type =iscolor ? CV_8UC3 :CV_8UC1;
m_origin =m_height >
0 ? IPL_ORIGIN_BL :IPL_ORIGIN_TL;
m_height =std::abs(m_height);
if( !result )
{
m_offset = -1;
m_width =m_height =
-1;
m_strm.close();
}
returnresult;
}
包含一个关键类型:RLByteStreamm_strm;
这个RLByteStream 类位于:C:\opencv_vs2008\2.3.1\modules\highgui\src\bitstrm.hpp中
描述为:
class RLByteStream - uchar-oriented stream.
l in prefix means that the least significant uchar of a multi-uchar value goes first
也就是说:
他作用于uchar类型的流文件,前缀中的L表示在多个uchar值中最短的有意义uchar值优先。
他继承自:
class RLByteStream : public RBaseStream
{
public:
virtual ~RLByteStream();
intgetByte();
intgetBytes( void*buffer, intcount );
intgetWord();
intgetDWord();
};
这个RBaseStream工厂模式的实现要素就是按照一定的顺序从流文件中读取数据出来:
//class RBaseStream - base class for other reading streams.
classRBaseStream
{
public:
//methods
RBaseStream();
virtual ~RBaseStream();
virtualbool open( const string& filename );
virtualbool open( const Mat& buf );
virtualvoid close();
boolisOpened();
voidsetPos( intpos );
intgetPos();
voidskip( int bytes );
protected:
boolm_allocated;
uchar*m_start;//文件的首地址
uchar*m_end;//文件的尾地址
uchar*m_current;//文件的当前位置指针
FILE*m_file;//文件指针
intm_block_size;//块大小
intm_block_pos;//当前文件位置
boolm_is_opened;
virtualvoid readBlock();
virtualvoid release();
virtualvoid allocate();
};
他的实现是:
constint BS_DEF_BLOCK_SIZE =
1<<15;
RBaseStream::RBaseStream()
{
m_start =m_end = m_current =
0;
m_file = 0;
m_block_size =BS_DEF_BLOCK_SIZE;
m_is_opened =false;
m_allocated =false;
}
也就是:
RBaseStream::RBaseStream()
{
m_start =m_end = m_current =
0;//首尾指针都是零初始化
m_file = 0;//文件没有读入
m_block_size =1<<15;//每次读取文件1<<15个字节存在一个数组里面
m_is_opened =false;//文件没有打开
m_allocated =false;//空间没有申请
}
其他函数功能还是很简单的,看代码就可以明白了。
需要注意的其中一个知识点有:assert 宏,断言assert 是仅在Debug 版本起作用的宏,它用于检查“不应该”发生的情况。
在运行过程中,如果assert 的参数为假,那么程序就会中止(一般地还会出现提示对话,说明在什么地方引发了assert)。
assert 不是一个仓促拼凑起来的宏。为了不在程序的Debug 版本和Release 版本引起差别,assert 不应该产生任何副作用。所以assert
不是函数,而是宏。程序员可以把assert看成一个在任何系统状态下都可以安全使用的无害测试手段。[b]如果程序在 assert 处终止了,并不是说含有该assert 的函数有错误,而是调用者出了差错,assert 可以帮助我们找到发生错误的原因。[/b]
(在林锐的《高质量C/C++编程指南-第一版》[b]中有详细的介绍)[/b]
然后调用子类的GetByte()获得一个字节 GetWord()获得双字节 即一个字:
继承自他的RLByteStream 中的:intgetWord()和intgetDWord();函数就是这个功能。
继续返回到boolBmpDecoder::readHeader()函数中看怎么读取BMP文件的头部:
看一下BMP头的构成
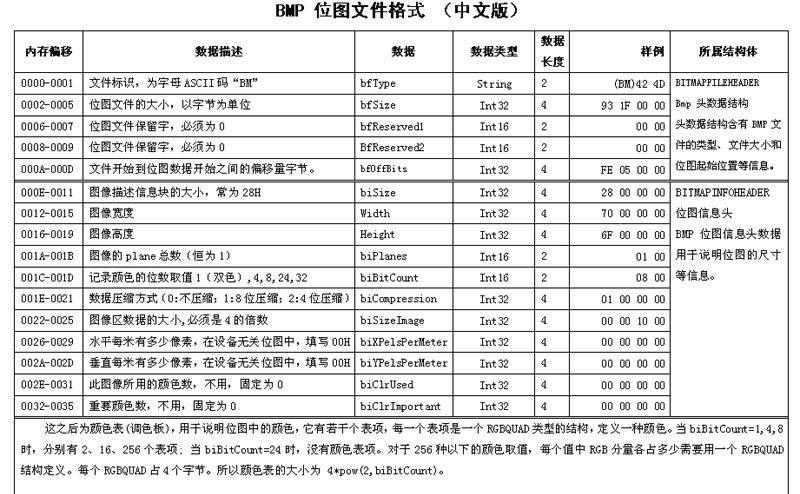
m_strm.open(m_filename ) 用来打开对于文件
m_strm.skip(
10 );//跳过10bytes(10个字节),跳过的这10字节从0000-0009基本没有含义
m_offset =m_strm.getDWord();//获取双字,就是4字节,000A-000D,是文件开始到位图数据之间的偏移量
intsize = m_strm.getDWord(); //获取四字节,000E-0011,得到图像描述信息快大小
<1>当if(size >=
36 ) 的时候:
m_width =m_strm.getDWord();//获取四字节,0012-0015,图像的宽度
m_height =m_strm.getDWord(); //获取四字节,0016-0019,图像的高度
然后:
m_bpp =m_strm.getDWord()
>> 16; //获取四字节,001A-001D,再右移16位,应该是获取图像的颜色数?
m_rle_code = (BmpCompression)m_strm.getDWord(); //获取四字节,001E-0021,获取是否是压缩
m_strm.skip(12);//然后跳过12字节
intclrused = m_strm.getDWord(); ////获取四字节,002E-0031,这儿就是获取这个bmp图像使用的颜色数
然后:
m_strm.skip(size -
36 ); //跳过(size - 36)字节,size是图像描述信息快大小,就是说图像信息块的总大小减去36字节,就是4字节
到现在为止,已经到跳出了位图文件的整个头部,进入了数据区,那么接下来的工作很自然的就是根据位图文件的颜色数m_bpp来正确的读取数据了:
if(m_width >
0 && m_height != 0 &&
(((m_bpp == 1 ||m_bpp ==
4 || m_bpp == 8 ||
m_bpp == 24 ||m_bpp ==
32 ) && m_rle_code ==BMP_RGB) ||
(m_bpp == 16 && (m_rle_code ==BMP_RGB || m_rle_code ==BMP_BITFIELDS))
||
(m_bpp == 4 &&m_rle_code == BMP_RLE4)
||
(m_bpp == 8 &&m_rle_code == BMP_RLE8)))
这些就是颜色数和是否压缩之间的判断关系,然后就是根据m_bpp来读取数据了,详细代码就不分析了。
<2>elseif( size ==
12 ) 就是说信息头的大小是12字节的时候
这个时候和上面的分析差不多,不多说了。
同理,其他格式的支持也是这个流程,在设计模式上就是一个工厂模式的实现,谢谢大家的支持,有任何的评论请留言。

相关文章推荐
- shell 解释器
- no ocijdbc11 in java.library.path linux
- Docker awesome commands
- linux中断原理专题
- Linux使用笔记: 定制core dump文件的文件名
- Android访问百度网站
- Install R and RStudio on Ubuntu
- linux面试题
- shell第一个例子清理日志
- Linux下面的终端编程 做一个简单的菜单
- tnsnames linux找的位置顺序
- 项目24.2 油量监控
- Linux Makefile与Kconfig文件详解
- linux centos svn 安装配置自动同步更新web服务
- Apache或者nginx反向代理时,request.getservername()出现的问题!
- shell数组
- hadoop学习之hadoop集群功能简单测试验证
- Linux系统编程获取系统的CPU资源
- 从需求的角度去理解Linux系列:总线、设备和驱动
- centos下rpm打包简单实例