DynamoDB中的二级索引(global secondary index)
2015-09-23 09:09
323 查看
DynamoDB属于NoSql类型的数据库,Nosql不代表没有索引,相反DynamoDB也存在全局索引和全局二级索引。但DynamoDB的索引和oracle,mysql这些关系式数据库的索引有很大不同。下面,就简单讲解一下DynamoDB中的全局二级索引。
为什么只提全局二级索引,而不谈全局索引呢?这是因为在创建DynamoDB时,一定要指定一个hash键。如果不指定表的hash键,那么DynamoDB是不允许创建这张表的。指定的这个hash键就是全局索引(详情请点击这里查看)。因此DynamoDB中每张表都会存在一个全局索引,这个索引有至少一个hash键和多个range键共同组成。但DynamoDB表中不一定都存在全局二级索引。全局二级索引更多是为适应应用程序逻辑而设置的。下面我们看一下何为全局二级索引。
DynamoDB的全局二级索引同样是由一个hash键和多个range键所组成,但与全局索引有所不同的是,全局二级索引的键属性不一定需要和原始表中的键属性保持一致。例如我们有如下一张表:
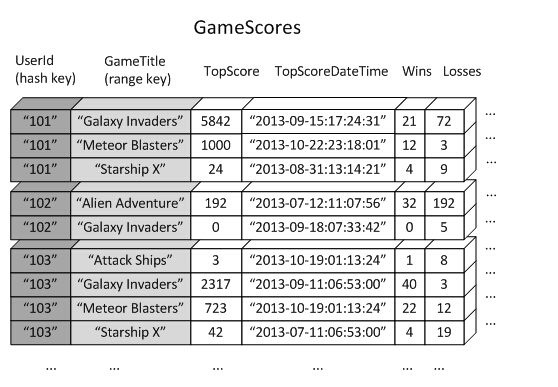
userid是hash类型,GameTitle是range类型。我们创建一个全局二级索引,名为:global secondary index。global secondary index索引中的hash键设定为GameTile,range键则设定为TopScrore。因为原表中的hash键会存在于任意一个全局二级索引中,所以global secondary index最终所包含的数据将是下面的数据:

这只是全局二级索引和全局索引第一个不同点。在全局索引中,必须保证索引值唯一不重复。但在全局二级索引中,就不需要保证所有索引值保持唯一了,例如下图所示:
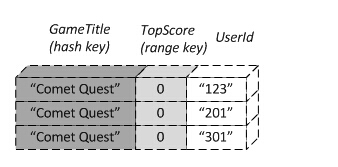
在全局索引中,userid+gameTitle保持了唯一性,但在全局二级索引中,因为gameTile+TopScore是索引键值,所以出现了重复。这点在全局二级索引中是合法的。这就是第二点不同。
第三点,就是二级索引所包含的数据是有要求的。在全局索引中,如果所插入的记录中有一个全局索引键不存在,那么插入会失败。这点
9c53
再全局二级索引中同样存在,例如下图:
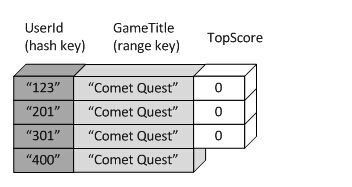
userid=400,GateTile=Comet Quest的记录项,因为满足全局索引要求,所以可以成功插入到DynamoDB表中。但不满足全局二级索引的键值要求(全局二级索引键值为GameTitle+TopScore,此记录TopScore为空),因此在全局二级索引中,将不会包括此条记录。最终的数据如下:
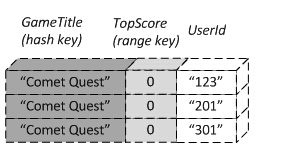
这样就引出了下面我们的讨论话题:二级索引是如何保存记录项的?
在DynamoDB中存在一个概念:投影属性。所谓的投影指的是全局二级索引从源表中所获取数据的集合。正如上图我们所看到的那三条记录就是全局二级索引投影中的一部分。
如果对于投影的概念不好理解,就可以类比为oracle中的视图概念。符合视图筛选SQL规则的数据都会囊括到视图中,而视图本身是不存储数据的。投影同视图类似,都是结果的集合体。
每个二级索引在创建时,都需要指定投影规则,目前有三个规则:
KEYS_ONLY,INCLUDE 和ALL(具体概念请参看这里),这三个规则中,KEYS_ONLY只包含源表的HASH键+range键,素以所创建的投影面积最小。而ALL将包含源表所有的键,因此所创建的投影面积将最大。INCLUDE可以根据用户自己的条件添加相关键,属于定制类型。
下面是使用三条规则的建议,仅供参考:
如果只需要访问少量属性,同时尽可能降低延迟,就应考虑仅将键属性投影到global secondary index。索引越小,存储索引所需的成本越少,并且写入成本也会越少。
如果应用程序频繁访问某些非键属性,应考虑将这些属性投影到global secondary index。global secondary index的额外存储成本会抵消执行频繁表扫描的成本。
如果您需要频繁访问大多数非键属性,就可以将这些属性(甚至是整个源表)投影到global secondary index。这样可获得最大的灵活性;但是,存储成本会增加,甚至是加倍。
如果您的应用程序并不会频繁查询表,但必须要对表中的数据执行大量写入或更新操作,就应考虑投影 KEYS_ONLY。这是最小的global secondary index,但仍可用于查询活动。
在使用oracle时,可以指定sql语句使用哪条索引去检索。在DynamoDB中同样也可以指定查询所使用的全局二级索引名称,下面就是使用query时指定索引名称的代码示例:
在Oracle中,视图中的数据是实时同步的,或者说是查询视图时,oracle会再次刷新视图的。那么DynamoDB中的全局二级索引是如何同步数据的呢?因为DynamoDB是分布式数据库,所以全局二级索引数据同步注定不会是实时同步,多少会存在一些延时。虽然DynamoDB会通过一致性检查来保证,源表插入或者删除数据时,全局二级索引会同步插入删除数据,但用户仍然需要考虑到延时的可能性。
以上就是DynamoDB中全局二级索引使用的一些入门知识。
为什么只提全局二级索引,而不谈全局索引呢?这是因为在创建DynamoDB时,一定要指定一个hash键。如果不指定表的hash键,那么DynamoDB是不允许创建这张表的。指定的这个hash键就是全局索引(详情请点击这里查看)。因此DynamoDB中每张表都会存在一个全局索引,这个索引有至少一个hash键和多个range键共同组成。但DynamoDB表中不一定都存在全局二级索引。全局二级索引更多是为适应应用程序逻辑而设置的。下面我们看一下何为全局二级索引。
DynamoDB的全局二级索引同样是由一个hash键和多个range键所组成,但与全局索引有所不同的是,全局二级索引的键属性不一定需要和原始表中的键属性保持一致。例如我们有如下一张表:
userid是hash类型,GameTitle是range类型。我们创建一个全局二级索引,名为:global secondary index。global secondary index索引中的hash键设定为GameTile,range键则设定为TopScrore。因为原表中的hash键会存在于任意一个全局二级索引中,所以global secondary index最终所包含的数据将是下面的数据:
这只是全局二级索引和全局索引第一个不同点。在全局索引中,必须保证索引值唯一不重复。但在全局二级索引中,就不需要保证所有索引值保持唯一了,例如下图所示:
在全局索引中,userid+gameTitle保持了唯一性,但在全局二级索引中,因为gameTile+TopScore是索引键值,所以出现了重复。这点在全局二级索引中是合法的。这就是第二点不同。
第三点,就是二级索引所包含的数据是有要求的。在全局索引中,如果所插入的记录中有一个全局索引键不存在,那么插入会失败。这点
9c53
再全局二级索引中同样存在,例如下图:
userid=400,GateTile=Comet Quest的记录项,因为满足全局索引要求,所以可以成功插入到DynamoDB表中。但不满足全局二级索引的键值要求(全局二级索引键值为GameTitle+TopScore,此记录TopScore为空),因此在全局二级索引中,将不会包括此条记录。最终的数据如下:
这样就引出了下面我们的讨论话题:二级索引是如何保存记录项的?
在DynamoDB中存在一个概念:投影属性。所谓的投影指的是全局二级索引从源表中所获取数据的集合。正如上图我们所看到的那三条记录就是全局二级索引投影中的一部分。
如果对于投影的概念不好理解,就可以类比为oracle中的视图概念。符合视图筛选SQL规则的数据都会囊括到视图中,而视图本身是不存储数据的。投影同视图类似,都是结果的集合体。
每个二级索引在创建时,都需要指定投影规则,目前有三个规则:
KEYS_ONLY,INCLUDE 和ALL(具体概念请参看这里),这三个规则中,KEYS_ONLY只包含源表的HASH键+range键,素以所创建的投影面积最小。而ALL将包含源表所有的键,因此所创建的投影面积将最大。INCLUDE可以根据用户自己的条件添加相关键,属于定制类型。
下面是使用三条规则的建议,仅供参考:
如果只需要访问少量属性,同时尽可能降低延迟,就应考虑仅将键属性投影到global secondary index。索引越小,存储索引所需的成本越少,并且写入成本也会越少。
如果应用程序频繁访问某些非键属性,应考虑将这些属性投影到global secondary index。global secondary index的额外存储成本会抵消执行频繁表扫描的成本。
如果您需要频繁访问大多数非键属性,就可以将这些属性(甚至是整个源表)投影到global secondary index。这样可获得最大的灵活性;但是,存储成本会增加,甚至是加倍。
如果您的应用程序并不会频繁查询表,但必须要对表中的数据执行大量写入或更新操作,就应考虑投影 KEYS_ONLY。这是最小的global secondary index,但仍可用于查询活动。
在使用oracle时,可以指定sql语句使用哪条索引去检索。在DynamoDB中同样也可以指定查询所使用的全局二级索引名称,下面就是使用query时指定索引名称的代码示例:
{
"TableName": "GameScores",
"IndexName": "GameTitleIndex",
"KeyConditionExpression": "GameTitle = :v_title",
"ExpressionAttributeValues": {
":v_title": {"S": "Meteor Blasters"}
},
"ProjectionExpression": "UserId, TopScore",
"ScanIndexForward": false
}在Oracle中,视图中的数据是实时同步的,或者说是查询视图时,oracle会再次刷新视图的。那么DynamoDB中的全局二级索引是如何同步数据的呢?因为DynamoDB是分布式数据库,所以全局二级索引数据同步注定不会是实时同步,多少会存在一些延时。虽然DynamoDB会通过一致性检查来保证,源表插入或者删除数据时,全局二级索引会同步插入删除数据,但用户仍然需要考虑到延时的可能性。
以上就是DynamoDB中全局二级索引使用的一些入门知识。

相关文章推荐
- 哪些因素决定产品经理在互联网人中的薪水
- 浅谈HTTP中Get与Post的区别
- 在UILable内显示HTML页面内容
- OpenJudge题目解析-中缀表达式的值
- C语言 判断0~3000之间的闰年
- MessagePack介绍
- Umeng推送消息的坑,Android Service的android:exported详解
- UFLDL接听教程练习(来自编码器和矢量编程疏)
- VM中 Ubuntu14.04 中Samba的安装配置和使用
- 基于ThinkPHP+uploadify+upload+PHPExcel 无刷新导入数据
- AFNetworking判断当前手机的网络状态
- UVA 12673 贪心
- 我的ASPxGridView控件的数据是在后台绑定的,但是实现不了筛选和分页的功能,只能显示一页的数据?
- 优先队列(堆)
- ASIHTTPRequest详解 [经典]
- ASIHTTPRequest-插件的使用
- 刘强东内部分享:京东为什么能成功?因为做到了这一点
- 【jQuery应用】导航栏滑块随鼠标移动
- Android Studio快捷键
- Activity的launch mode