7.基于yarn的Spark集群搭建
2015-09-21 15:50
274 查看
构造分布式的Spark1.0.2集群
下载Scala 2.10.4,具体下载地址:
http://www.scala-lang.org/download/2.10.4.html
在Ubuntu机器上Scala会帮助我们自动选择“scala-2.10.4.tgz”进行下载;
安装和配置Scala
我们需要在master、slave1以及slave2上分别安装Scala

安装Scala
将Scala安装包拷贝到各台机器上

解压

新建目录/usr/lib/scala

将上述解压之后的文件夹scala-2.10.4拷贝到/usr/lib/scala下


修改配置:vim ~/.bashrc



修改配置/etc/environment,修改PATH,CLASSPATH和JAVA_HOME




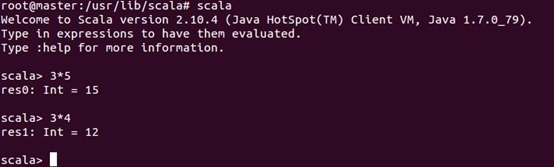
在每台机器上安装完成后可以进行一下验证:

下载Spark 1.0.2,具体下载地址:
http://www.apache.org/dyn/closer.cgi/spark/spark-1.0.2/spark-1.0.2-bin-hadoop2.tgz
在master上安装和配置Spark 1.0.2集群
把下载后“spark-1.0.2-bin-hadoop2.tgz”解压到“/usr/local/spark”目录之下:
新建目录/usr/local/spark

将安装包拷贝到/usr/local/spark下并解压

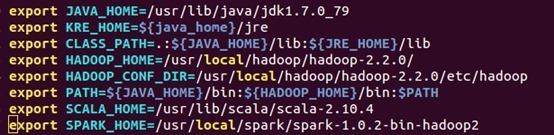
配置“~/.bashrc”,设置“SPARK_HOME”并把Spark的bin目录加入到PATH之中(修改environment文件),配置完成后使用source命令使配置生效。


修改/etc/environment中的PATH



进入spark的conf目录:

第一步修改slaves文件,首先打开该文件:

我们把slaves文件的内容修改为:

第二步:配置spark-env.sh
首先把spark-env.sh.template拷贝到spark-env.sh:

打开“spark-env.sh”文件

在文件末尾加入以下内容

slave1和slave2采用和master完全一样的Spark安装配置。
启动Spark分布式集群并查看信息。
第一步:启动Hadoop集群,在master使用jps命令, 在slave1和slave2上使用jps




第二步:启动Spark集群
在Hadoop集群成功启动的基础上,启动Spark集群需要使用Spark的sbin目录下“start-all.sh”:

使用jps查看集群信息


在web页面访问Spark集群http://master:8080
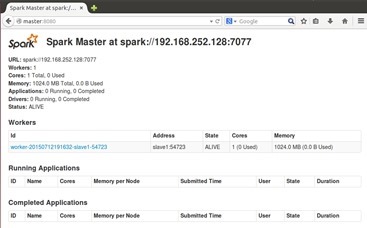
从页面上可以看到Work节点及其信息
此时,进入Spark的bin目录,使用spark-shell控制台

此时我们进入了Spark的shell环境,根据输出的信息,我们可以通过“http://master:4040” 从Web的角度看一下SparkUI的情况,如下图所示:

当然,你也可以查看一些其它的信息,例如Environment:

同时,我们也可以看一下Executors:
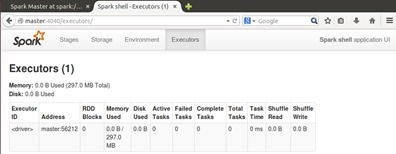
至此,我们 的Spark集群搭建成功。
下载Scala 2.10.4,具体下载地址:
http://www.scala-lang.org/download/2.10.4.html
在Ubuntu机器上Scala会帮助我们自动选择“scala-2.10.4.tgz”进行下载;
安装和配置Scala
我们需要在master、slave1以及slave2上分别安装Scala

安装Scala
将Scala安装包拷贝到各台机器上

解压

新建目录/usr/lib/scala

将上述解压之后的文件夹scala-2.10.4拷贝到/usr/lib/scala下


修改配置:vim ~/.bashrc



修改配置/etc/environment,修改PATH,CLASSPATH和JAVA_HOME




在每台机器上安装完成后可以进行一下验证:


下载Spark 1.0.2,具体下载地址:
http://www.apache.org/dyn/closer.cgi/spark/spark-1.0.2/spark-1.0.2-bin-hadoop2.tgz
在master上安装和配置Spark 1.0.2集群
把下载后“spark-1.0.2-bin-hadoop2.tgz”解压到“/usr/local/spark”目录之下:
新建目录/usr/local/spark

将安装包拷贝到/usr/local/spark下并解压

配置“~/.bashrc”,设置“SPARK_HOME”并把Spark的bin目录加入到PATH之中(修改environment文件),配置完成后使用source命令使配置生效。

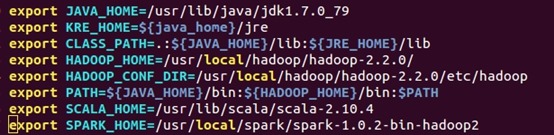

修改/etc/environment中的PATH



进入spark的conf目录:

第一步修改slaves文件,首先打开该文件:

我们把slaves文件的内容修改为:

第二步:配置spark-env.sh
首先把spark-env.sh.template拷贝到spark-env.sh:

打开“spark-env.sh”文件
在文件末尾加入以下内容

slave1和slave2采用和master完全一样的Spark安装配置。
启动Spark分布式集群并查看信息。
第一步:启动Hadoop集群,在master使用jps命令, 在slave1和slave2上使用jps



第二步:启动Spark集群
在Hadoop集群成功启动的基础上,启动Spark集群需要使用Spark的sbin目录下“start-all.sh”:
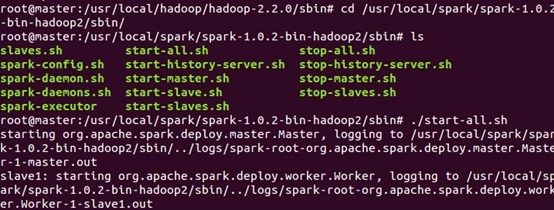
使用jps查看集群信息


在web页面访问Spark集群http://master:8080

从页面上可以看到Work节点及其信息
此时,进入Spark的bin目录,使用spark-shell控制台

此时我们进入了Spark的shell环境,根据输出的信息,我们可以通过“http://master:4040” 从Web的角度看一下SparkUI的情况,如下图所示:
当然,你也可以查看一些其它的信息,例如Environment:
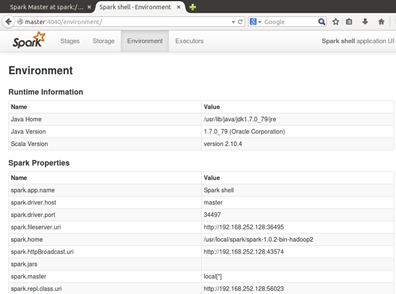
同时,我们也可以看一下Executors:

至此,我们 的Spark集群搭建成功。

相关文章推荐
- python启动浏览器崩溃
- "未能加载文件或程序集“MySql.Data, Version=6.9.3.0”或它的某一个依赖项。
- 利用TaskManager爬取2万条代理IP实现自动投票功能
- C++ STL map资料
- raid5实现原理
- 安卓新闻客户端编写(一) JSOUP抓取网页信息
- Android快速开发工具GsonFormat使用教程
- android弹出下拉选择菜单,单选,多选【运行截图——图】
- Windows下Redis的安装使用
- HDFS的快照原理和Hbase基于快照的表修复
- Cisco UCS 62XX firmware 升级
- Silverlight 新闻列表、编辑、保存方式
- jvm的快照获取与浏览
- 单位长度闭区间包含所有点集
- JSP,html的submit button的背景设置和表格的黑线样式代码
- JS实现仿微博可关闭弹出层效果
- 判断当前时间为第几周,周几
- android Bitmap getByteCount和getRowBytes
- Ubuntu12.04_X64 apt-get install 报错404
- android studio集成svn