HDFS原理讲解
2015-09-17 09:12
471 查看
简介
本文是笔者在学习HDFS的时候的学习笔记整理, 将HDFS的核心功能的原理都整理在这里了。【广告】 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/xuanku/p/index.html
HDFS的基础架构
见下图, 核心角色: Client, NameNode, Secondary NameNode, DataNode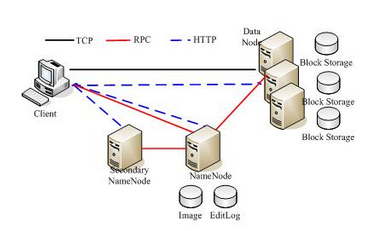
Client: 对用户提供系列操作工具&API
NameNode:
包含
map<filename, list<block_id>>, 以及
map<block_id, list<DataNode>>的数据结构
资源分配算法
DataNode:
管理好自己的磁盘, 上报数据给NameNode
读取过程
Client向NameNode读取数据分布式信息Client找到第一个数据块离自己最近的DataNode
跟这个DataNode交互并获取数据
读完之后开始跟下一个数据块离自己最近的DataNode交互
读完之后close连接
如果读取过程中读取失败, 将会依次读取该数据块下一个副本, 失败的节点将被记录, 不再连接
近的判断标准(NetworkTopology.sortByDistance):
如果客户端和某个Datanode在同一台机器上, 优先
如果客户端和某个Datanode在同一个rack上, 次优先
否则随机
详情请参考下图:
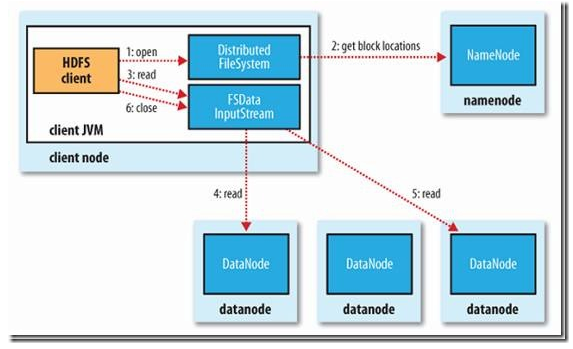
参考:
读取判断远近. http://blog.csdn.net/xhh198781/article/details/7256142
写入过程
流程客户端通知NameNode创建目录
客户端开始写数据, 先写到本地, 然后定期分块
要写新块的时候再跟NameNode打交道, 获取到新块的目标地址
同一个数据块的不同副本是链式同步, 客户端只跟第一个副本打交道
只有所有副本都写入成功, 才开始下一个块的写操作
如果有一个写失败, 则:
失败的DataNode会加一个标记, 根据这个标记, 这份不完全的数据回头会被删除
不再往失败的DataNode上面写, 其他两个DataNode继续写
告诉NameNode这份数据副本数不足, NameNode回头会异步的补上
如果副本数少于某个配置(比如1个), 整个写入就算失败
详情参考下图:

副本分配策略
选择一个本地节点
选择一个本地机架节点
选择一个远程节点
随机选择一个节点
调整同步顺序(以节约带宽为目标)
参考: http://www.linuxidc.com/Linux/2012-01/50864.htm
如何感知机架位
通过NameNode的一个配置: topology.script.file.name 来控制的, 该配置的值对应一个脚本, 脚本输入是一个IP/字符串, 输出一个机架位名称, 该名称可以用"/xx/xx"的树形结构来表示网络拓扑。
如果没有配置该值, 则代表所有机器一个机架位, 会增加机器网络带宽消耗。
参考: http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html
HDFS Append文件逻辑
首先要说明两个概念, block和replica, 在NN中叫block, 在DN中叫replica。block有四种状态:
complete. block的长度和时间戳都不再变化, 并且至少有一个DN对应的rpelica是finalized的状态。
under_construction. 文件被create和append的时候, 该block就处于under_construction的状态。该状态下文件是可以被读取的, 读取的长度是保证在所有的DN上副本都能读取到的长度;
under_recovery. 如果一个文件的最后一个block在under_construction的状态时, client异常掉线了, 那么需要有一段时间的lease过期和恢复释放锁和关闭文件的过程, 这段时间之内该block处于under_recovery的状态.
committed. 介于under_construction和complete之间的状态。client收到所有DN写成功的ARK, 但是NN还没有收到任何一个DN报replica已经finalized的状态。
replica状态要复杂一些:
Finalized. 写完事儿之后的状态。
rbw(replica being written). 类似under_construction, 在创建和写入过程中的replica。同under_construction, 也是可以被读取的;
rwr(rpelica waiting recovry). 异常之后, 等待lease过期的状态;
rur(replica under recovery). 异常之后, lease过期之后修复数据的状态;
Temporary. 类似rbw, 但是不是正常写的状态, 是比如集群间balance的状态。跟rbw不同的是, 同步中的文件不可读;
参考: http://yanbohappy.sinaapp.com/?p=175
SecondaryNameNode机制
SecondaryNameNode不是说NameNode挂了的备用节点他的主要功能只是定期合并日志, 防止日志文件变得过大
合并过后的镜像文件在NameNode上也会保存一份
SecondaryNameNode工作过程:
SecondaryNameNode向NameNode发起同步请求, 此时NameNode会将日志都写到新的日志当中
SecondaryNameNode向NameNode下载镜像文件+日志文件
SecondaryNameNode开始Merge这两份文件并生成新的镜像文件
SecondaryNameNode向NameNode传回新的镜像文件
NameNode文件将新的镜像文件和日志文件替换成当前正在使用的文件
详情请参考下图:
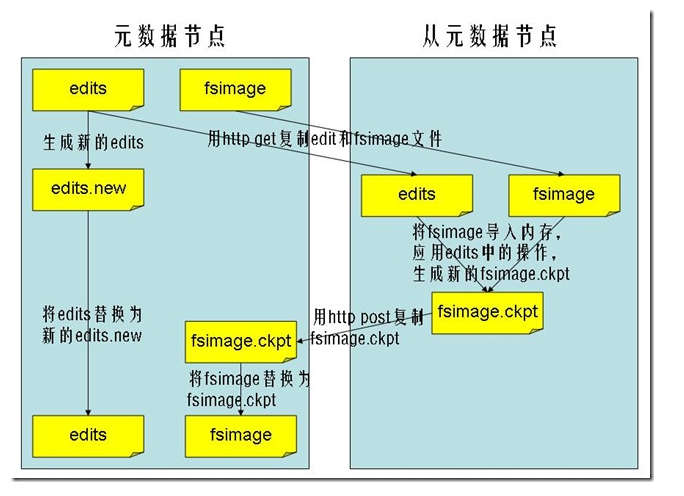
BackupNode机制
跟Mysql的Master-Slave机制类似, BackupNode是作为热备而存在, 同步更新NameNode节点的数据。NameNode HA机制
NameNode数据主要包含两类:map<filename, list<block_id>>即数据源信息
这一类数据主要存储在两个文件中:
fsimg,
editlog, 如上所说SecondaryNameNode的作用就是定期merge这两个文件。
在HA机制中, 流程为将editlog写入一个共享存储, 一般为QJM(Quorum Journal Manager)节点, 一般为3个节点。active NN的editlog实时写入qjm节点, standby的NN定期从editlog中同步数据到自己的节点信息当中。
每次日志都有一个自增的epoch_id, jn会对比自己已有的epoch_id和NN给的epoch_id, 如果NN给的epoch_id比较小, 则会忽略该命令, 以此方式来达到避免脑裂问题。
NN通过ZKFC(ZooKeeper Fail Controller)来控制当前到底是哪个节点为ActiveNameNode, 在每个NN上都单独启动了一个ZKFC的进程, 该进程一方面监控NN的状态信息, 另一方面跟ZK保持连接说明自己的状态。类似租约, 一旦NN节点挂了, ZK会自动更新该节点状态信息, 同时通知另外的节点, 另外的节点就好接替前一个NN的工作。
map<block_id, list<DataNode>>即block_id和DataNode的对应关系
这个本身信息是通过DataNode给NameNode上报来做到的, 增加了节点之后, DataNode跟每个NameNode都会上报一份信息。
类似qjm, DataNode也会维护一个自增的id, 当有NN切换的时候, 也会增加这个id, DN会拒绝比当前id还要小的控制命令。
HA的数据流图如下:
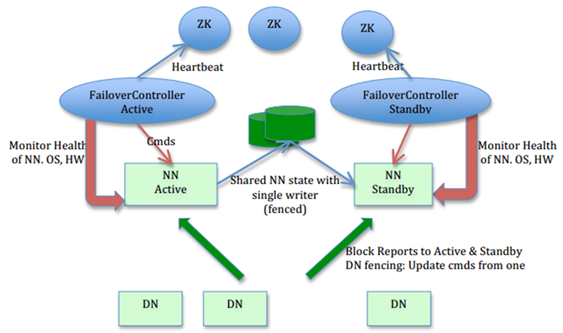
参考:
当前HDFS HA介绍. http://www.it165.net/admin/html/201407/3465.html
HDFS HA进化论. http://www.bubuko.com/infodetail_124006.html
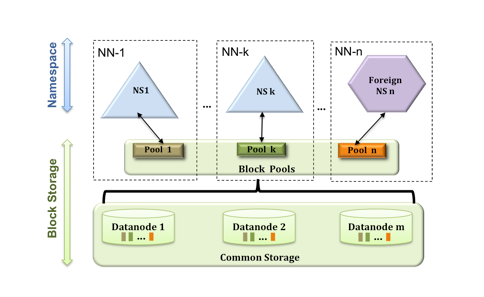
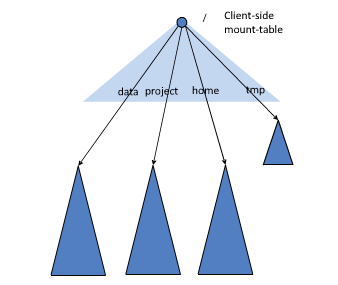
HDFS Federation
本身实现不复杂, 就是将原来所有信息都放在一个NameNode节点里, 变成了可以将NameNode信息拆分放到多个节点里, 一人分一个目录。注意有一个block pool的概念, 为了避免在分配DataNode上的打架, 为每个NameNode分配了一个专属的block pool, 这样大家就分开了, 需要一开始配置自己的NameNode需要多少空间, 即Namespace Volume。
如下图:
参考:
http://zh.hortonworks.com/blog/an-introduction-to-hdfs-federation/
http://blog.csdn.net/strongerbit/article/details/7013221/
https://issues.apache.org/jira/secure/attachment/12453067/high-level-design.pdf
HDFS distcp
distcp1:利用mapreduce来传输文件
为了保证文件内block的有序性, 所以map最小粒度为文件
问题出来了, 大文件会拖慢小文件, 导致整个拷贝效率不行
distcp2:
针对distcp1, 做了一些优化:
去掉了一些不必要的目录检查工作, 从而缩短了目录检查时间;
动态分配map task的工作量, 在运行过程中调整自己的任务量, 能优化部分distcp1的情况;
可对拷贝进行限速
支持HSFTP
fastcopy:
最主要是对federation机制的支持, 如果使用fastcp在同一个集群中不同的federation进行拷贝的时候, 则不需要再走一遍网络和删除, 只修改源数据即可, 但是distcp不行。
facebook的hadoop版本已经将fastcopy的这个特性集成到了distcp当中。
参考:
distcp介绍. http://dongxicheng.org/hadoop-hdfs/hadoop-hdfs-distcp-fastcopy/
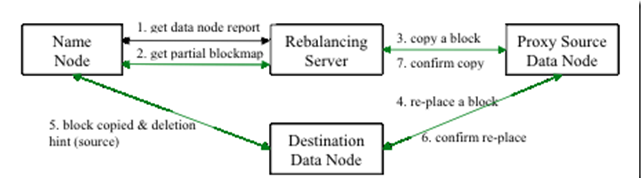
HDFS Balancer
是一个脚本, 该脚本做的事情很简单:从NameNode获取DataNode数据分布信息
计算数据移动方案
执行移动方案
直到满足平衡要求
平衡要求是该脚本的一个输入(0~100), 代表不同机器的磁盘利用率差值。
注意:
Balancer程序现在设计是不会将一个rack的数据移动到另外一个rack
也就是说跨rack的均衡是不能满足的, 除非有修改后的Balancer程序
一般不要将Balancer放到NameNode上运行
数据流图:
参考:
balancer介绍. http://www.aboutyun.com/thread-7354-1-1.html
HDFS 快照
快照是给当前hdfs内容建立一个只读备份, 可以针对整个hdfs或者某个目录创建, 一般用于备份, 故障恢复, 避免人工故障等。HDFS的快照有如下特点:
快照是瞬间创造的, 如果抛开inode的查询时间, 只需要O(1)
快照创建以后需要额外的内存来存储变化, 内存需要是O(M)
快照只是记录了block_list和文件大小信息, 不做任何的实际数据拷贝
快照不会影响到现在数据的增删改查, 查询快照的时候, 会根据当前结果以及记录的日志做减法来获取快照数据
HDFS NFSv3
就是在本地通过挂载NFS访问HDFS的文件参考: http://blog.csdn.net/dmcpxy/article/details/18257065
HDFS dfsadmin
参考: http://blog.csdn.net/xiaojin21cen/article/details/42610697hdfs 权限控制
认证:支持两种方式, simple和kerberos, 通过
hadoop.security.authentication这个类配置。默认是simple模式, simple模式下, 用户名为
whoami, 组名为
bash -c group
kerberos没有研究。
授权:
针对每个目录, 有读写一级可执行的权限设置, 权限有分为用户级别, 组级别, 以及其他。
同时也可以通过设置ACL来针对一个目录的某些用户设置特殊权限。
参考: http://demo.netfoucs.com/skywalker_only/article/details/40709447
代码阅读笔记
读取文件信息
客户端代码
DFSClient.getFileInfo到ClientProtocol类里查看getFileInfo
是接口, 用ctl+T查看其子类列表, 找到ClientNamenodeProtocolTranslatorPB类
再看ClientNamenodeProtocolTranslatorPB.getFileInfo函数
看到其调用了rpcProxy.getFileInfo类, 找rpcProxy的来源, 发现是构造函数传进来的, 所以用ctl+alt+H来找到其反向调用关系
NameNodeProxies.createNNProxyWithClientProtocol函数
发现在该函数中调用了RPC.getProtocolProxy函数来获取该proxy, 在获得该proxy的时候传入了系列NN服务相关配置, 以及SocketFactory
到RPC.getProtocolProxy函数
发现其是调用了getProtocolEngine(XX).getProxy(XX)的函数, 那么先看setProtocolEngine函数
到RPC.setProtocolEngine函数中看
发现其都设置的是RpcEngine的子类, 那么去看该RpcEngine的接口, 发现其实一个interface, 老办法, 用ctl+T看其子类, 找到ProtobufRpcEngine子类
找ProtobufRpcEngine.getProxy函数
发现其主要是使用了自己的一个Invoker的类, 该Invoker是一个动态代理类, 主要关注其invoke函数即可
看ProtobufRpcEngine.Invoker.invoke函数
该函数就是各种网络操作了, 可以看到他是将函数名拼成了一个字节流, 然后发给了NN, 然后hang住等待NN的返回结果
服务端代码
ClientProtocol类是用来通信的类, 客户端和服务端都会用到, 直接看其子类即可看到其子类有一个NameNodeRpcServer, 看起来肯定就是NN服务端这头的代码了
NameNodeRpcServer.getFileInfo
发现其实调用了namesystem.getFileInfo函数
namesystem.getFileInfo函数
一层一层往下面调用, 就可以找到其最终的逻辑了
NN启动代码
直接进入NameNode.main查看参数获取和查看我们略过, 我们着重关注后面的逻辑
createNameNode
调用了构造函数: NameNode(conf), conf已经根据argv参数初始化好了
该函数又调用了NameNode.initialize函数
initialize(conf)
启动了http接口, 先启动http接口应该是说可以通过http接口来查看启动状态
调用loadNamesystem函数
该函数又调用了FSNamesystem.loadNamesystem函数
FSNamesystem就是非常重要的类了, 基本上所有的NN的核心数据结构都放在这个类里面了
主要关注该类的loadFSImage函数
namenode.join()
参考文章
hdfs流程简介. http://www.cnblogs.com/forfuture1978/archive/2010/03/14/1685351.htmlhdfs vs kfs. http://blog.csdn.net/Cloudeep/article/details/4467238
hdfs的缺陷. http://www.cnblogs.com/wycg1984/archive/2010/03/20/1690281.html
hdfs配置. http://cqfish.blog.51cto.com/622299/207766
hdfs看分布式文件系统设计需求. http://dennis-zane.javaeye.com/blog/228537
利用Java API访问hdfs文件. http://blog.csdn.net/zhangzhaokun/article/details/5597433
hdfs重大性能杀手——shell. http://blog.csdn.net/fly542/article/details/6819945
DataNode的stale状态. http://www.tuicool.com/articles/RneQve
hdfs源码阅读. http://www.linuxidc.com/Linux/2012-03/55966.htm

相关文章推荐
- Flume前述(三)--多 agent 汇聚写入 HDFS
- Hadoop-2.4.1安装配置
- HDFS(数学题)
- Hadoop分布式文件系统HDFS
- linux hadoop 搭建
- HDFS hflush hsync和close的区别
- 至HDFS附加内容
- hadoop2.7集群迁移namenode
- tachyon与hdfs,以及spark整合
- tachyon与hdfs,以及spark整合
- hadoop2.7集群,新增datanode节点后报错的解决思路
- HDFS文件写入与读取
- 对HDFS进行操作——笔记
- hadoop三种安装模式
- hadoop新增节点
- flume-hdfs 按照时间关闭并新开文件
- hdfs体系
- 在基于docker的Hadoop集群上搭建Spark
- Dream------Hadoop--网络拓扑与Hadoop--摘抄
- Dream------Hadoop--Hadoop HA QJM (Quorum Journal Manager)