深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet之LR
2015-09-14 09:16
627 查看
原地址可以查看更多信息
本文主要参考于:Classifying MNIST digits using Logistic Regression
python源代码(GitHub下载 CSDN免费下载)
0阶张量叫标量(scarlar);1阶张量叫向量(vector);2阶张量叫矩阵(matrix)
本文主要内容:如何用python中的theano包实现最基础的分类器–LR(Logistic Regression)。
一、模型
由概率论知识总结出模型,二分类用公式(1),多分类用公式(2);为了求解公式(2)中的最优参数(W和b),推导出目标函数公式(3)
逻辑回归是一种线性分类器。它的参数包括权重矩阵W和偏置b。通过将输入向量映射到一组超平面进行多分类(一个超平面可以分两类,多个超平面可以进行多分类)。输入向量到超平面的距离作为输入样本属于对应类别的概率。
输入向量x属于第Y=i类的概率模型表示如下:
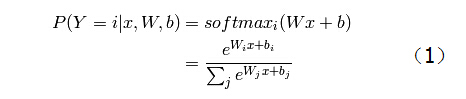
其中,W和b是参数,P(Y=i|x)是条件概率,意思是在变量x的条件下,Y=i的概率。举例:P(Y=0|x)表示输入的样本x被识别为数字0的概率。这个并不难理解,只要学过概率论的话,不是问题。
softmaxi(Wx+b)可以理解为x属于i的概率,具体含义看下边内容。这个表达式更清楚地说明了x的运算过程,即:x与W点乘,再与b 矩阵/向量 相加,然后把结果传入softmax分类器,得到分类结果为i。那么,softmax是如何工作的呢(具体含义是什么呢)?就是公式(1)中最终的结果表达式。下面分析这个表达式。
eWix+bi可以理解为表示样本x属于第i类的概率。那么∑Nj=0eWjx+bj显然是表示x属于每一类的概率之和。为什么两者要做除法呢?答案是:归一化。这样,最终P(Y=i)的累加和就是1。
首先看看eWix+bi是怎么来的。因为逻辑回归的假设函数是sigmoid函数,即h(x)=11+e−(Wx+b),而softmax是多分类,所以其假设函数就是
h(x)=⎡⎣⎢⎢⎢⎢⎢p(Y=0|x)p(Y=1|x)⋮p(Y=N|x)⎤⎦⎥⎥⎥⎥⎥=1∑Nj=0eWjx+bj⎡⎣⎢⎢⎢⎢⎢eW0x+b0eW1x+b1⋮eWNx+bN⎤⎦⎥⎥⎥⎥⎥(2)
从公式(2)很容易看出是如何归一化的了。找到这个列向量中最大值的下标k,就代表样本x属于第k类的概率最大。因此,模型的最终预测公式为:ypred=argmaxP(Y=i|x)(3)
argmax函数的作用是返回矩阵中每一行或每一列最大数的下标。在这里,矩阵Pm∗n的元素构成是每一行代表一个样本(即共有m个样本),每一列代表当前样本属于该列下标(0-n)类别的概率。举例:第0行第0列元素是第0行中最大数下标。则表示:第0行所代表的样本被分类为0的概率是最大的。那么以此类推,最终的结果就表示每一个样本所分 类别 的最大概率。
至此,概率模型已经分析完毕。下边就是如何用python实现计算输入样本的概率值了。代码如下(代码中会涉及到Theano的使用,因此如果有解释不到的函数,请参考我的Theano官方教程翻译及学习笔记系列博文,以上博文因正在编写,临时可参考Theano实现卷积运算代码详解):
由于水平有限,思路可能会有一些乱,但是对照公式(1-3)慢慢整理一下还是可以理解的。现在所写的代码只是实现了公式的计算,相当于定义了一个函数,输入样本矩阵x,输出预测矩阵y。但是,如果能预测的准呢?下面且看第二部分。
二、定义代价函数
要最优化公式(3)的参数,那么根据经验编写出代价函数,即公式(4)
由机器学习的知识知道,要想使得模型预测结果最佳,即W和b取得最佳参数,那么就要根据假设函数定义一个代价函数,当代价函数最小化时,预测结果最优。(为什么要根据假设函数?因为模型公式就是基于假设函数编写的)
在多分类的逻辑回归中,经常用负对数似然函数作为代价函数,记为A。最小化函数A就等价于最大化A中的似然函数。似然函数L和代价函数ℓ定义如下:
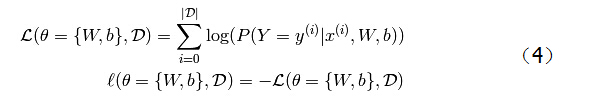
D是数据集(输入样本集);|D|表示样本总数;θ是模型参数(由W和b构成);
公式L表示,先对每一个输入样本进行公式(1)操作,然后对结果取log对数,最后将所有样本的概率对数求和。
公式ℓ表示取L的负数。
那么,怎么最小化那一堆的非线性函数呢?梯度下降法。梯度下降法是到目前为止最简单的用来最小化任意非线性函数的方法。因此,这里也同样采取该方法,不过是经过改进的,即批量随机梯度下降法(MSGD-stochastic gradient method with mini-batches)听起来很炫,其实很简单。梯度下降是更新整体样本;随机梯度下降是更新一个样本;而批量随机梯度则是介于两者之间,更新一部分样本。具体解释看这里。
现在基本介绍完了代价函数了,下面来看一下代价函数的代码,注意是传入一块(minibatch)样本数据,而不是一个或整个样本。
对照公式(4)看一下,
P(Y=yi|xi)就是传入的self.p_y_given_x;
log(P)就是T.log(p);
∑求和就是代码中的 LP[T.arange(y.shape[0]),y];
ℓ=−L就是return中的取反。
还有一点就是公式中没有求均值,而代码中加入了T.mean的均值运算。这是因为公式(4)还欠缺一部分就是除以|D|,因此其完整的公式为:
K=1|D|L(θ={W,b},D)=1|D|∑i=0|D|log(P(Y=y(i)|x(i),W,b))ℓ(θ={W,b},D)=−K
为什么要用均值,若不是和值呢?这里是因为用的批量随机梯度下降法来最小化代价函数,不同的样本输入块可能对学习速率产生不同的影响。因此用均值是为了降低学习速率对输入样本块的依赖性。
三、创建LR的python类
1. 创建类。
2.实例化LR类的方式:
四、训练模型
我们先回顾一下如何进行模型训练。
【1】根据概率论的知识总结出一个概率模型,二分类用公式(1);多分类用公式(2);
【2】求解出模型中的参数(即公式(2)中的W和b),因为参数没有确定值,所以我们的目标是使概率模型产出的概率(即公式(3)的结果)距离正确结果越接近越好。
【3】根据经验以及步骤2中的目标编写出代价函数,即公式(4);通过最小化公式(4)获得最优参数W和b。
【4】采用批量随机梯度下降法最小化公式(4)。本节主要讲述如何用梯度下降法最小化代价函数。先说一下思路,就是先根据上边计算出的cost(代价函数)对W和b分别求偏导,然后根据梯度更新W和b的值。计算误差;再根据新的W和b求偏导,如此迭代下去,直到误差符合要求或者迭代达到一定次数结束循环,此时的W和b即可以认为是目前最优的。
若要在大多数的编程语言中实现梯度下降算法,需要手动的推导出梯度表达式∂ℓ∂W和∂ℓ∂b(ℓ就是公式(4)),这是一个非常麻烦的推导,而且最终结果也很复杂,特别是考虑到数值稳定性的问题的时候。
然而,在Theano这个工具中,这个变得异常简单。因为它已经把求梯度这种运算给封装好了,不需要手动推导公式,只需要按照格式传入数据即可。下面来看一下代码。
计算完了梯度,就要根据梯度进行权值偏置值的更新。操作如下:
现在我们就可以编写模型训练函数了。代码就两句话,但是解释一大堆,希望能帮助初学者了解function的工作原理。
每一次调用train_model(index),都会计算并返回输入样本块的cost,然后执行一次MSGD,并更新W和b。整个学习算法的一次迭代这样循环调用train_model (总样本数/样本块数)次。假设总样本60000个,一个样本块600个,那么一次迭代就需要调用100次train_model。而模型的训练又需要进行多次迭代,直到达到迭代次数或者误差率达到要求。
五、测试模型
模型测试需要用到LR中的errors函数。下面来看一下测试模型函数test_model和验证模型函数validate_model。有了上面训练模型的基础,相信这个测试模型会很容易理解。
一块一块的讲了这么多代码,或许都看晕了,下面就看一下整合之后的代码会更清晰。
六、整合代码
python源代码带注释下载
只有一个lr.py,直接用python命令执行即可。
七、参考目录
Classifying MNIST digits using Logistic Regression
DeepLearning tutorial(1)Softmax回归原理简介+代码详解
深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算
本文主要参考于:Classifying MNIST digits using Logistic Regression
python源代码(GitHub下载 CSDN免费下载)
0阶张量叫标量(scarlar);1阶张量叫向量(vector);2阶张量叫矩阵(matrix)
本文主要内容:如何用python中的theano包实现最基础的分类器–LR(Logistic Regression)。
一、模型
由概率论知识总结出模型,二分类用公式(1),多分类用公式(2);为了求解公式(2)中的最优参数(W和b),推导出目标函数公式(3)
逻辑回归是一种线性分类器。它的参数包括权重矩阵W和偏置b。通过将输入向量映射到一组超平面进行多分类(一个超平面可以分两类,多个超平面可以进行多分类)。输入向量到超平面的距离作为输入样本属于对应类别的概率。
输入向量x属于第Y=i类的概率模型表示如下:
其中,W和b是参数,P(Y=i|x)是条件概率,意思是在变量x的条件下,Y=i的概率。举例:P(Y=0|x)表示输入的样本x被识别为数字0的概率。这个并不难理解,只要学过概率论的话,不是问题。
softmaxi(Wx+b)可以理解为x属于i的概率,具体含义看下边内容。这个表达式更清楚地说明了x的运算过程,即:x与W点乘,再与b 矩阵/向量 相加,然后把结果传入softmax分类器,得到分类结果为i。那么,softmax是如何工作的呢(具体含义是什么呢)?就是公式(1)中最终的结果表达式。下面分析这个表达式。
eWix+bi可以理解为表示样本x属于第i类的概率。那么∑Nj=0eWjx+bj显然是表示x属于每一类的概率之和。为什么两者要做除法呢?答案是:归一化。这样,最终P(Y=i)的累加和就是1。
首先看看eWix+bi是怎么来的。因为逻辑回归的假设函数是sigmoid函数,即h(x)=11+e−(Wx+b),而softmax是多分类,所以其假设函数就是
h(x)=⎡⎣⎢⎢⎢⎢⎢p(Y=0|x)p(Y=1|x)⋮p(Y=N|x)⎤⎦⎥⎥⎥⎥⎥=1∑Nj=0eWjx+bj⎡⎣⎢⎢⎢⎢⎢eW0x+b0eW1x+b1⋮eWNx+bN⎤⎦⎥⎥⎥⎥⎥(2)
从公式(2)很容易看出是如何归一化的了。找到这个列向量中最大值的下标k,就代表样本x属于第k类的概率最大。因此,模型的最终预测公式为:ypred=argmaxP(Y=i|x)(3)
argmax函数的作用是返回矩阵中每一行或每一列最大数的下标。在这里,矩阵Pm∗n的元素构成是每一行代表一个样本(即共有m个样本),每一列代表当前样本属于该列下标(0-n)类别的概率。举例:第0行第0列元素是第0行中最大数下标。则表示:第0行所代表的样本被分类为0的概率是最大的。那么以此类推,最终的结果就表示每一个样本所分 类别 的最大概率。
至此,概率模型已经分析完毕。下边就是如何用python实现计算输入样本的概率值了。代码如下(代码中会涉及到Theano的使用,因此如果有解释不到的函数,请参考我的Theano官方教程翻译及学习笔记系列博文,以上博文因正在编写,临时可参考Theano实现卷积运算代码详解):
# 初始化权值W,shared是用来为了GPU运算的。 self.W = theano.shared( value=numpy.zeros( (n_in, n_out), dtype=theano.config.floatX), name='W', borrow=True ) # 初始化偏置b self.b = theano.shared( value=numpy.zeros( (n_out,), dtype=theano.config.floatX), name='b', borrow=True ) # 下面就是概率公式(1)的代码实现,其中dot是点乘运算;input是输入向量x; self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b) # 对输入样本的预测,是公式(3)的代码实现,axis表示函数argmax要按照行返回最大数 self.y_pred = T.argmax(self.p_y_given_x, axis=1)
由于水平有限,思路可能会有一些乱,但是对照公式(1-3)慢慢整理一下还是可以理解的。现在所写的代码只是实现了公式的计算,相当于定义了一个函数,输入样本矩阵x,输出预测矩阵y。但是,如果能预测的准呢?下面且看第二部分。
二、定义代价函数
要最优化公式(3)的参数,那么根据经验编写出代价函数,即公式(4)
由机器学习的知识知道,要想使得模型预测结果最佳,即W和b取得最佳参数,那么就要根据假设函数定义一个代价函数,当代价函数最小化时,预测结果最优。(为什么要根据假设函数?因为模型公式就是基于假设函数编写的)
在多分类的逻辑回归中,经常用负对数似然函数作为代价函数,记为A。最小化函数A就等价于最大化A中的似然函数。似然函数L和代价函数ℓ定义如下:
D是数据集(输入样本集);|D|表示样本总数;θ是模型参数(由W和b构成);
公式L表示,先对每一个输入样本进行公式(1)操作,然后对结果取log对数,最后将所有样本的概率对数求和。
公式ℓ表示取L的负数。
那么,怎么最小化那一堆的非线性函数呢?梯度下降法。梯度下降法是到目前为止最简单的用来最小化任意非线性函数的方法。因此,这里也同样采取该方法,不过是经过改进的,即批量随机梯度下降法(MSGD-stochastic gradient method with mini-batches)听起来很炫,其实很简单。梯度下降是更新整体样本;随机梯度下降是更新一个样本;而批量随机梯度则是介于两者之间,更新一部分样本。具体解释看这里。
现在基本介绍完了代价函数了,下面来看一下代价函数的代码,注意是传入一块(minibatch)样本数据,而不是一个或整个样本。
# y.shape返回y的行数和列数,则y.shape[0]返回y的行数,即样本的总个数,因为一行是一个样本。 # T.arange(n),则是产生一组包含[0,1,...,n-1]的向量。 # T.log(x),则是对x求对数。记为LP # LP[T.arange(y.shape[0]),y]是一组向量,其元素是[ LP[0,y[0]], LP[1,y[1]], # LP[2,y[2]], ...,LP[n-1,y[n-1]] ] # T.mean(x),则是求向量x中元素的均值。 return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])
对照公式(4)看一下,
P(Y=yi|xi)就是传入的self.p_y_given_x;
log(P)就是T.log(p);
∑求和就是代码中的 LP[T.arange(y.shape[0]),y];
ℓ=−L就是return中的取反。
还有一点就是公式中没有求均值,而代码中加入了T.mean的均值运算。这是因为公式(4)还欠缺一部分就是除以|D|,因此其完整的公式为:
K=1|D|L(θ={W,b},D)=1|D|∑i=0|D|log(P(Y=y(i)|x(i),W,b))ℓ(θ={W,b},D)=−K
为什么要用均值,若不是和值呢?这里是因为用的批量随机梯度下降法来最小化代价函数,不同的样本输入块可能对学习速率产生不同的影响。因此用均值是为了降低学习速率对输入样本块的依赖性。
三、创建LR的python类
1. 创建类。
class LR(object): """ 逻辑归回的实现是基于博文中给出的公式,需要预先设定好参数W和b。最小化方法用的批量随机梯度下降法MSGD。 因此传入数据是一块一块的。 """ def __init__(self, input, n_in, n_out): """ 初始化函数!此类实例化时调用该函数 按照Python定义类的格式给出如下定义,需要传入的参数分别为: input的类型为 TensorType,类似于形参,起象征性的作用,并不包含真实的数据; input传入值为 minibatch样本数据,该数据是一个m*n的矩阵。m表示此minibatch块共有m个样本;n表示每一个样本的实际数据。 在mnist实验中,n=784=28*28,因为每一张图片是28*28像素的。 n_in 的类型为 int; n_in 传入值为 每个输入样本的单元数(应该是图片的高*宽(28*28=784),但是在我们的实验数据中, 已经把图片数据矩阵存储为了行向量(784*1),因此这个地方传入的就是数据域中的data列的长度, 即n_in=784,具体的样本数据是传入input里面) n_out的类型为 int n_out传入值为 输出结果的类别数,就是数据域中的标签的范围。此处就是0-9共10个数字。所以n_out=10。就是10分类。 """ # 初始化权值矩阵 # numpy.zeros((m,n),dtype='float32') 是产生一组 m行n列的全0矩阵,每个矩阵元素存储为float32类型。 # shared()函数是将生成的矩阵封装为shared类型,该类型可以用于GPU加速运算,没有其他用途。 self.W = theano.shared( value = numpy.zeros( (n_in, n_out), dtype = 'float32' ), name = 'W', borrow = True ) # 初始化偏置值 # b是一个向量,长度为n_out,就是每一种分类都有一个偏置值 self.b = theano.shared( value = numpy.zeros( (n_out,), dtype = 'float32' ), name = 'b', borrow = True ) # 计算公式(1),具体解释见博文 http://blog.csdn.net/niuwei22007/article/details/47705081 self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b) # 计算公式(3) self.y_pred = T.argmax(self.p_y_given_x, aixs = 1) # 组织模型用到的参数,即把W和b组装成list,便于在类外引用。 self.param = [self.W, self.b] # 记录模型的具体输入数据,便于在类外引用 self.input = input def negative_log_likelihood(self, y): """ 负对数似然函数,即代价函数。 需要传入的参数为: y 的类型为 TensorType,类似于形参,起象征性的作用,并不包含真实的数据; y 传入值为 input对应的标签向量,如果input的样本数为m,则input的行数就是m,那么y就是一个m行的列向量。 """ # 计算完整的公式(4),具体解释见博文 http://blog.csdn.net/niuwei22007/article/details/47705081 return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y]) def errors(self, y): """ 误差计算函数。传入的参数参考negative_log_likelihood. 其作用就是统计预测正确的样本数占本批次总样本数的比例。 """ # 检查 传入正确标签向量y和前面做出的预测向量y_pred是否是具有相同的维度。如果不相同怎么去判断某个样本预测的对还是不对? # y.ndim返回y的维数 # raise是抛出异常 if y.ndim != self.y_pred.ndim: raise TypeError("y doesn't have the same shape as self.y_pred") # 继续检查y是否是有效数据。依据就是本实验中正确标签数据的存储类型是int # 如果数据有效,则计算: # T.neq(y1, y2)是计算y1与y2对应元素是否相同,如果相同便是0,否则是1。 # 举例:如果y1=[1,2,3,4,5,6,7,8,9,0] y2=[1,1,3,3,5,6,7,8,9,0] # 则,err = T.neq(y1,y2) = [0,1,0,1,0,0,0,0,0,0],其中有3个1,即3个元素不同 # T.mean()的作用就是求均值。那么T.mean(err) = (0+1+0+1+0+0+0+0+0+0)/10 = 0.3,即误差率为30% if y.dtype.startswith('int'): return T.mean(T.neq(self.y_pred, y)) else: raise NotImplementedError()
2.实例化LR类的方式:
# 因为LR中的input是TensorType类型,因此引用时,也需要定义一个TensorType类型
# x表示样本的具体数据
x = T.matrix('x')
# 同样y也应该是一个TensorType类型,是一个向量,而且数据类型还是int,因此定义一个T.ivector。
# 其中i表示int,vector表示向量。详细可以参考Theano教程。
# y表示样本的标签。
y = T.ivector('y')
# x就是input样本,是一个矩阵,因此定义一个T.matrix
# n_in,n_out的取值在此不再赘述,可以翻看上边的博文。
# 在实例化时,会自动调用LR中的__init__函数
classifier = LR(input=x, n_in=28*28, n_out=10)
# 代价函数,依据公式(3)计算生成。这是一个符号变量,cost并不是一个具体的数值。当传入具体的数据后,
# 其才会有具体的数据产生。
cost = classifier.negative_log_likelihood(y)四、训练模型
我们先回顾一下如何进行模型训练。
【1】根据概率论的知识总结出一个概率模型,二分类用公式(1);多分类用公式(2);
【2】求解出模型中的参数(即公式(2)中的W和b),因为参数没有确定值,所以我们的目标是使概率模型产出的概率(即公式(3)的结果)距离正确结果越接近越好。
【3】根据经验以及步骤2中的目标编写出代价函数,即公式(4);通过最小化公式(4)获得最优参数W和b。
【4】采用批量随机梯度下降法最小化公式(4)。本节主要讲述如何用梯度下降法最小化代价函数。先说一下思路,就是先根据上边计算出的cost(代价函数)对W和b分别求偏导,然后根据梯度更新W和b的值。计算误差;再根据新的W和b求偏导,如此迭代下去,直到误差符合要求或者迭代达到一定次数结束循环,此时的W和b即可以认为是目前最优的。
若要在大多数的编程语言中实现梯度下降算法,需要手动的推导出梯度表达式∂ℓ∂W和∂ℓ∂b(ℓ就是公式(4)),这是一个非常麻烦的推导,而且最终结果也很复杂,特别是考虑到数值稳定性的问题的时候。
然而,在Theano这个工具中,这个变得异常简单。因为它已经把求梯度这种运算给封装好了,不需要手动推导公式,只需要按照格式传入数据即可。下面来看一下代码。
# 对W求导,只需要调用函数T.grad,把用代码计算出的公式(4)的结果作为cost传入(就是前边已经计算出来的cost), # 指定求(偏)导对象为classifier.W(classifier就是前边自己定义的LR类) g_W = T.grad(cost=cost, wrt=classifier.W) # 对b求偏导,原理一样。 g_b = T.grad(cost=cost, wrt=classifier.b)
计算完了梯度,就要根据梯度进行权值偏置值的更新。操作如下:
# updates相当于一个更新器,说明了哪个参数需要更新,以及更新公式 # 下面代码指明更新需要参数W,更新公式是(原值-学习速率*梯度值) updates = [(classifier.W, classifier.W - learning_rate * g_W), # 参数b的更新类似于W (classifier.b, classifier.b - learning_rate * g_b)]
现在我们就可以编写模型训练函数了。代码就两句话,但是解释一大堆,希望能帮助初学者了解function的工作原理。
# 上边所提到的TensorType都是符号变量,符号变量只有传入具体数值时才会生成新的数据。
# theano.function也是一个特色函数。在本实验中,它会生成一个叫train_model的函数。
# 该函数的参数传递入口是inputs,就是将需要传递的参数index赋值给inputs
# 该函数的返回值是通过outputs指定的,也就是返回经过计算后的cost变量。
# 更新器updates是用刚刚定义的update
# givens是一个很实用的功能。它的作用是:在计算cost时会用到符号变量x和y(x并没有显示的表达出来,
# 函数negative_log_likehood用到了p_y_given_x,而计算p_y_given_x时用到了input,input就是x)。
# 符号变量经过计算之后始终会有一个自身值,而此处计算cost不用x和y的自身值,那就可以通过givens里边的表达式
# 重新指定计算cost表达式中的x和y所用的值,而且不会改变x和y原来的值。
##举个简单的例子:
# state = shared(0)
# inc = T.iscalar('inc')
# accumulator = function([inc], state, updates=[(state, state+inc)])
# state.get_value() #结果是array(0),因为初始值就是0
# accumulator(1) #会输出结果array(0),即原来的state是0,但是继续往下看
# state.get_value() #结果是array(1),根据updates得知,state=state+inc=0+1=1
# accumulator(300) #会输出结果array(1),即原来的state是1,但是继续往下看
# state.get_value() #结果是array(301),根据updates得知,state=state+inc=1+300=301
##此时state=301,继续做实验
# fn_of_state = state * 2 + inc
##foo用来代替更新表达式中的state,即不用state原来的值,而用新的foo值,但是fn_of_state表达式不变
# foo = T.scalar(dtype=state.dtype)
##skip_shared函数是输入inc和foo,输出fn_of_state,通过givens修改foo代替fn_of_state表达式中的state
# skip_shared = function([inc, foo], fn_of_state, givens=[(state, foo)])
# skip_shared(1, 3) #会输出结果array(7),即fn_of_state=foo * 2 + inc = 3*2+1 = 7
##再来看看state的原值是多少呢?
# state.get_value() #会输出结果array(301),而不是foo的值3
##因为每一次都需要用新的x和y去计算cost值,而不是用原来的上一次的x和y去计算,因此需要用到givens
##希望通过这个小例子能说清楚givens的作用。
train_model = theano.function(
inputs = [index],
outputs = cost,
updates = update,
givens = {
# x:仅仅是表示第一个数据用来代替x,而不去重新声明一个和x结构类型相同的符号变量了;y同理
# trian_set_x是训练数据集中的x分量,就是样本的数据部分,trian_set_x[a:b]代表取数组中下标从a开始,到下标b之前的数据。
# train_set_y是训练数据集中的y分量,就是样本的标签部分。
x: trian_set_x[index * batch_size:(index + 1) * batch_size],
y: trian_set_y[index * batch_size:(index + 1) * batch_size]
}
)每一次调用train_model(index),都会计算并返回输入样本块的cost,然后执行一次MSGD,并更新W和b。整个学习算法的一次迭代这样循环调用train_model (总样本数/样本块数)次。假设总样本60000个,一个样本块600个,那么一次迭代就需要调用100次train_model。而模型的训练又需要进行多次迭代,直到达到迭代次数或者误差率达到要求。
五、测试模型
模型测试需要用到LR中的errors函数。下面来看一下测试模型函数test_model和验证模型函数validate_model。有了上面训练模型的基础,相信这个测试模型会很容易理解。
# 测试模型基本不需要说太多了,首先测试不需要更新数据,因此没有updates,但是测试需要用到givens来代替cost计算公式中x和y的数值。
# 测试模型采用的数据集是测试数据集test_set_x和test_set_y
test_model = thenao.function(
inputs = [index],
outputs = classifier.errors(y),
givens = {
x: test_set_x[index * batch_size: (index + 1) * batch_size],
y: test_set_y[index * batch_size: (index + 1) * batch_size]
}
)
# 验证模型和测试模型的不同之处在于计算所用的数据不一样,验证模型用的是验证数据集。
validate_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: valid_set_x[index * batch_size: (index + 1) * batch_size],
y: valid_set_y[index * batch_size: (index + 1) * batch_size]
}
)一块一块的讲了这么多代码,或许都看晕了,下面就看一下整合之后的代码会更清晰。
六、整合代码
python源代码带注释下载
只有一个lr.py,直接用python命令执行即可。
七、参考目录
Classifying MNIST digits using Logistic Regression
DeepLearning tutorial(1)Softmax回归原理简介+代码详解
深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算

相关文章推荐
- bp神经网络及matlab实现
- 基于神经网络的预测模型
- 神经网络初步学习手记
- 图像识别和图像搜索
- 卷积神经网络
- 深度学习札记
- RBF的一点个人理解
- 利用自收敛深度人工神经网络构建(DNN)构建多语种大词汇量连续语音识别系统
- UFLDL Exercise: Convolutional Neural Network
- 基于遗传算法(GA)的神经网络训练算法
- 神经网络 caffe 的 vs2013 版本代码
- 图像智能打标签‘神器’-AlchemyVision API
- Matlab 神经网络工具箱
- ubuntu theano 安装成功,windows theano安装失败
- 卷积神经网络知识要点
- 1.linear Regression
- 1.linear Regression
- 51CTO学院优质新课抢先体验-5折好课帮你技能提升、升职加薪
- TensorFlow简介
- 支持向量机和逻辑回归的异同