MySQL技术之旅-慢查询作用、解析工具
2015-09-10 14:14
573 查看
MySQL作为一种关系型数据库,提供对标准SQL的支持,在日常运维工作当中,DBA一定会和SQL打交道,一般情况下就是开发找到你询问某些SQL的写法,有时会伴随“我这SQL咋这么慢啊!”“我这效率咋这么差啊!”这样那样的哀嚎或者线上数据库服务器负载突然飙升,首先怀疑的也是有新的SQL上线了,没有告诉DBA,这时就是体现你价值的时候了。
MySQL提供慢查询日志用来记录数据库执行的慢查询语句(这点感觉要比Oracle方便一些,当然没有Oracle的AWR报告那么详细),MySQL的慢查询日志中会记录执行SQL的 Thread_id,执行时间等信息,同时,MySQL官方安装了慢查询分析工具mysqldumpslow用于分析慢查询日志,还有许多第三方提供的日志分析工具,mysqlsla,pt-query-digest等。
下面对MySQL的慢查询进行介绍:
1.与MySQL慢查询主要的数据库参数:
slow_query_log:
布尔类型,on未开启数据库慢查询,off为关闭。可动态修改参数。
slow_query_log_file:
指明慢查询记录到那个文件中,绝对路径到文件名称,可动态修改参数。
long_query_time:
设置慢查询阈值,从mysql 5.1开始,long_query_time开始以微秒记录SQL语句运行时间,之前仅用秒为单位记录。这样可以更精确地记录SQL的运行时间,供DBA分析。可动态修改其值的大小。
log-queries-not-using-indexes:
如果运行的SQL语句没有使用索引,则mysql数据库同样会将这条SQL语句记录到慢查询日志文件中。
log-slow-admin-statements:
将慢管理语句例如OPTIMIZE TABLE、ANALYZE TABLE和ALTER TABLE记入慢查询日志。
2.MySQL慢查询分析工具的使用
mysqldumpslow
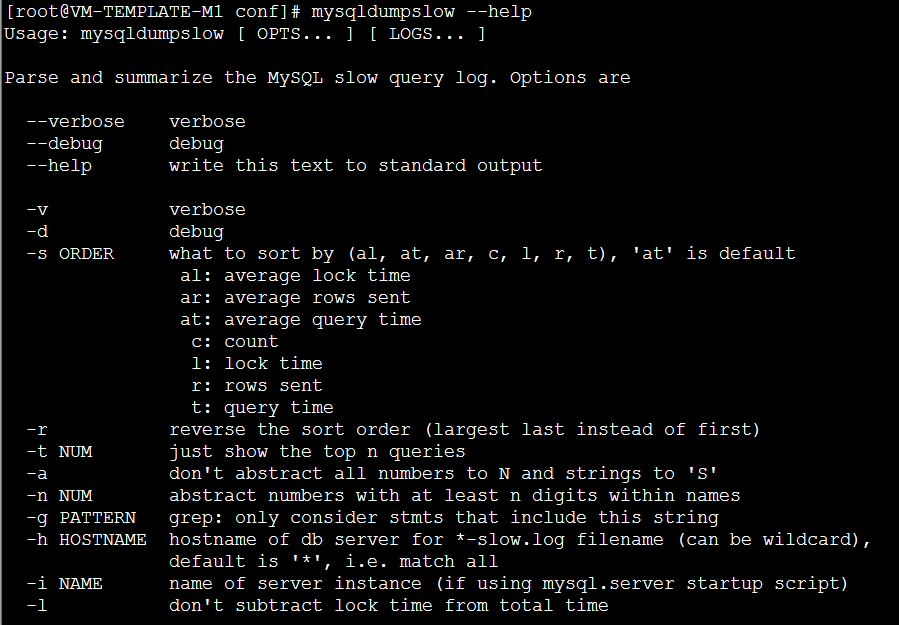
其中我们常用的参数有
-s:表示对解析后的慢查询按照何种方式排序,c、t、l、r分别按照记录的查询次数,时间,查询时间,返回的记录数来排序,ac、at、al、ar代表对应的倒序。
-t NUM:是top n的意思,表示只显示出按某种规则排序后的前几条语句。
-a:表示不讲数字和字符串的值进行抽象
-n NUM:抽象数字至少n位以内
-g PATTERN:使用后面的正则表达式来匹配,其中大小写是不敏感的。
举例:mysqldumpslow -t 10 -s t -g “left join” slow_queries.log
解析出按照查询所花费的时间排序前十个语句中含有左连接关键字的语句
mysqlsla
mysqlsla是hackmysql.co推出的一款MySQL日志分析工具,其功能十分强大,该工具可以对MySQL的slow log,general log,binary log等日志进行分析,得出报表用于阅读和问题诊断。
其参数有
-lt:与分析的日志类型slow, general, binary, msl, udl。
-sf”+-[type]”:表示要分析的操作有哪些SELECT, CREATE, DROP, UPDATE, INSERT,例如”+SELECT,INSERT”,不出现的默认是-,即不包括。
-db:要处理那个库的日志
-top:表示按规则排序的前多少条记录
-sort:按某种规则排序
t_sum:按总时间排序
c_sum:按总次数排序
c_sum_p: sql语句执行次数占总执行次数的百分比。
输出结果:
Count, sql的执行次数及占总的slow log数量的百分比.
Time, 执行时间, 包括总时间, 平均时间, 最小, 最大时间, 时间占到总慢sql时间的百分比. 95% of Time, 去除最快和最慢的sql, 覆盖率占95%的sql的执行时间.
Lock Time, 等待锁的时间. 95% of Lock , 95%的慢sql等待锁时间.
Rows sent, 结果行统计数量, 包括平均, 最小, 最大数量.
Rows examined, 扫描的行数量.
Database, 属于哪个数据库
Users, 哪个用户,IP, 占到所有用户执行的sql百分比
Query abstract, 抽象后的sql语句
Query sample, sql语句
pt-query-digest
pt-query-digest来自伟大的percona-toolkit工具集的一部分,由perl编写,这个工具集提供了很多有用的工具,以后会一一拿出来介绍哦。pt-query-digest它可以剖析各种MySQL的日志,进而为问题分析和诊断提供依据,可分析的日志类型有slow log,general log,binary log,tcpdump等。后续的可视化平台工具也是基于pt-query-digest完成解析慢查询日志后信息入库的。
pt-query-digest –help
pt-query-digest analyzes MySQL queries from slow, general, and binary log files.
It can also analyze queries from C and MySQL protocol data
from tcpdump. By default, queries are grouped by fingerprint and reported in
descending order of query time (i.e. the slowest queries first). If no C
are given, the tool reads C. The optional C is used for certain
options like L<”–since”> and L<”–until”>. For more details, please use the
–help option, or try ‘perldoc /usr/local/bin/pt-query-digest’ for complete
documentation.
Usage: pt-query-digest [OPTIONS] [FILES] [DSN]
Options:
–ask-pass Prompt for a password when connecting to MySQL
–attribute-aliases=a List of attribute|alias,etc (default db|Schema)
–attribute-value-limit=i A sanity limit for attribute values (default
4294967296)
–charset=s -A Default character set
–config=A Read this comma-separated list of config files;
if specified, this must be the first option on
the command line
–[no]continue-on-error Continue parsing even if there is an error (
default yes)
–[no]create-history-table Create the –history table if it does not exist (
default yes)
–[no]create-review-table Create the –review table if it does not exist (
default yes)
–daemonize Fork to the background and detach from the shell
–database=s -D Connect to this database
–defaults-file=s -F Only read mysql options from the given file
–embedded-attributes=a Two Perl regex patterns to capture pseudo-
attributes embedded in queries
–expected-range=a Explain items when there are more or fewer than
expected (default 5,10)
–explain=d Run EXPLAIN for the sample query with this DSN
and print results
–filter=s Discard events for which this Perl code doesn’t
return true
–group-by=A Which attribute of the events to group by (
default fingerprint)
–help Show help and exit
–history=d Save metrics for each query class in the given
table. pt-query-digest saves query metrics (query
time, lock time, etc.) to this table so you can
see how query classes change over time
–host=s -h Connect to host
–ignore-attributes=a Do not aggregate these attributes (default arg,
cmd, insert_id, ip, port, Thread_id, timestamp,
exptime, flags, key, res, val, server_id, offset,
end_log_pos, Xid)
–inherit-attributes=a If missing, inherit these attributes from the
last event that had them (default db,ts)
–interval=f How frequently to poll the processlist, in
seconds (default .1)
–iterations=i How many times to iterate through the collect
4000
-and-
report cycle (default 1)
–limit=A Limit output to the given percentage or count (
default 95%:20)
–log=s Print all output to this file when daemonized
–order-by=A Sort events by this attribute and aggregate
function (default Query_time:sum)
–outliers=a Report outliers by attribute:percentile:count (
default Query_time:1:10)
–output=s How to format and print the query analysis
results (default report)
–password=s -p Password to use when connecting
–pid=s Create the given PID file
–port=i -P Port number to use for connection
–processlist=d Poll this DSN’s processlist for queries, with –
interval sleep between
–progress=a Print progress reports to STDERR (default time,30)
–read-timeout=m Wait this long for an event from the input; 0 to
wait forever (default 0). Optional suffix s=
seconds, m=minutes, h=hours, d=days; if no
suffix, s is used.
–[no]report Print query analysis reports for each –group-by
attribute (default yes)
–report-all Report all queries, even ones that have been
reviewed
–report-format=A Print these sections of the query analysis
report (default rusage,date,hostname,files,header,
profile,query_report,prepared)
–report-histogram=s Chart the distribution of this attribute’s
values (default Query_time)
–resume=s If specified, the tool writes the last file
offset, if there is one, to the given filename
–review=d Save query classes for later review, and don’t
report already reviewed classes
–run-time=m How long to run for each –iterations. Optional
suffix s=seconds, m=minutes, h=hours, d=days; if
no suffix, s is used.
–run-time-mode=s Set what the value of –run-time operates on (
default clock)
–sample=i Filter out all but the first N occurrences of
each query
–set-vars=A Set the MySQL variables in this comma-separated
list of variable=value pairs
–show-all=H Show all values for these attributes
–since=s Parse only queries newer than this value (parse
queries since this date)
–socket=s -S Socket file to use for connection
–timeline Show a timeline of events
–type=A The type of input to parse (default slowlog)
–until=s Parse only queries older than this value (parse
queries until this date)
–user=s -u User for login if not current user
–variations=A Report the number of variations in these
attributes’ values
–version Show version and exit
–[no]version-check Check for the latest version of Percona Toolkit,
MySQL, and other programs (default yes)
–watch-server=s This option tells pt-query-digest which server IP
address and port (like “10.0.0.1:3306”) to watch
when parsing tcpdump (for –type tcpdump); all
other servers are ignored
Option types: s=string, i=integer, f=float, h/H/a/A=comma-separated list, d=DSN, z=size, m=time
Rules:
This tool accepts additional command-line arguments. Refer to the SYNOPSIS and usage information for details.
DSN syntax is key=value[,key=value…] Allowable DSN keys:
KEY COPY MEANING
=== ==== =============================================
A yes Default character set
D yes Default database to use when connecting to MySQL
F yes Only read default options from the given file
P yes Port number to use for connection
S yes Socket file to use for connection
h yes Connect to host
p yes Password to use when connecting
t no The –review or –history table
u yes User for login if not current user
If the DSN is a bareword, the word is treated as the ‘h’ key.
Options and values after processing arguments:
–ask-pass FALSE
–attribute-aliases db|Schema
–attribute-value-limit 4294967296
–charset (No value)
–config /etc/percona-toolkit/percona-toolkit.conf,/etc/percona-toolkit/pt-query-digest.conf,/root/.percona-toolkit.conf,/root/.pt-query-digest.conf
–continue-on-error TRUE
–create-history-table TRUE
–create-review-table TRUE
–daemonize FALSE
–database (No value)
–defaults-file (No value)
–embedded-attributes (No value)
–expected-range 5,10
–explain (No value)
–filter (No value)
–group-by fingerprint
–help TRUE
–history (No value)
–host (No value)
–ignore-attributes arg,cmd,insert_id,ip,port,Thread_id,timestamp,exptime,flags,key,res,val,server_id,offset,end_log_pos,Xid
–inherit-attributes db,ts
–interval .1
–iterations 1
–limit 95%:20
–log (No value)
–order-by Query_time:sum
–outliers Query_time:1:10
–output report
–password (No value)
–pid (No value)
–port (No value)
–processlist (No value)
–progress time,30
–read-timeout 0
–report TRUE
–report-all FALSE
–report-format rusage,date,hostname,files,header,profile,query_report,prepared
–report-histogram Query_time
–resume (No value)
–review (No value)
–run-time (No value)
–run-time-mode clock
–sample (No value)
–set-vars
–show-all
–since (No value)
–socket (No value)
–timeline FALSE
–type slowlog
–until (No value)
–user (No value)
–variations
–version FALSE
–version-check TRUE
–watch-server (No value)
分析慢查询日志用到的主要参数:
–create-review-table 当使用–review参数把分析结果输出到表中时,如果没有表就自动创建。
–create-history-table 当使用–history参数把分析结果输出到表中时,如果没有表就自动创建。
–filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
–limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
–host mysql服务器地址
–user mysql用户名
–password mysql用户密码
–history 将分析结果保存到表中,分析结果比较详细,下次再使用–history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
–review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用–review时,如果存在相同的语句分析,就不会记录到数据表中。
–output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
–since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
–until 截止时间,配合—since可以分析一段时间内的慢查询。
标准输出报告的格式:
输出的报告总共分三个部分
总体汇总结果
verall: 总共有多少条查询,上例为总共266个查询。
Time range: 查询执行的时间范围。
unique: 唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询,该例为55。
total: 总计 min:最小 max: 最大 avg:平均
95%: 把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值。
median: 中位数,把所有值从小到大排列,位置位于中间那个数。
分组统计结果
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
查询详细报告
Databases: 库名
Users: 各个用户执行的次数(占比)
Query_time distribution : 查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables: 查询中涉及到的表
Explain: 示例
MySQL提供慢查询日志用来记录数据库执行的慢查询语句(这点感觉要比Oracle方便一些,当然没有Oracle的AWR报告那么详细),MySQL的慢查询日志中会记录执行SQL的 Thread_id,执行时间等信息,同时,MySQL官方安装了慢查询分析工具mysqldumpslow用于分析慢查询日志,还有许多第三方提供的日志分析工具,mysqlsla,pt-query-digest等。
下面对MySQL的慢查询进行介绍:
1.与MySQL慢查询主要的数据库参数:
slow_query_log:
布尔类型,on未开启数据库慢查询,off为关闭。可动态修改参数。
slow_query_log_file:
指明慢查询记录到那个文件中,绝对路径到文件名称,可动态修改参数。
long_query_time:
设置慢查询阈值,从mysql 5.1开始,long_query_time开始以微秒记录SQL语句运行时间,之前仅用秒为单位记录。这样可以更精确地记录SQL的运行时间,供DBA分析。可动态修改其值的大小。
log-queries-not-using-indexes:
如果运行的SQL语句没有使用索引,则mysql数据库同样会将这条SQL语句记录到慢查询日志文件中。
log-slow-admin-statements:
将慢管理语句例如OPTIMIZE TABLE、ANALYZE TABLE和ALTER TABLE记入慢查询日志。
2.MySQL慢查询分析工具的使用
mysqldumpslow
其中我们常用的参数有
-s:表示对解析后的慢查询按照何种方式排序,c、t、l、r分别按照记录的查询次数,时间,查询时间,返回的记录数来排序,ac、at、al、ar代表对应的倒序。
-t NUM:是top n的意思,表示只显示出按某种规则排序后的前几条语句。
-a:表示不讲数字和字符串的值进行抽象
-n NUM:抽象数字至少n位以内
-g PATTERN:使用后面的正则表达式来匹配,其中大小写是不敏感的。
举例:mysqldumpslow -t 10 -s t -g “left join” slow_queries.log
解析出按照查询所花费的时间排序前十个语句中含有左连接关键字的语句
mysqlsla
mysqlsla是hackmysql.co推出的一款MySQL日志分析工具,其功能十分强大,该工具可以对MySQL的slow log,general log,binary log等日志进行分析,得出报表用于阅读和问题诊断。
其参数有
-lt:与分析的日志类型slow, general, binary, msl, udl。
-sf”+-[type]”:表示要分析的操作有哪些SELECT, CREATE, DROP, UPDATE, INSERT,例如”+SELECT,INSERT”,不出现的默认是-,即不包括。
-db:要处理那个库的日志
-top:表示按规则排序的前多少条记录
-sort:按某种规则排序
t_sum:按总时间排序
c_sum:按总次数排序
c_sum_p: sql语句执行次数占总执行次数的百分比。
输出结果:
Count, sql的执行次数及占总的slow log数量的百分比.
Time, 执行时间, 包括总时间, 平均时间, 最小, 最大时间, 时间占到总慢sql时间的百分比. 95% of Time, 去除最快和最慢的sql, 覆盖率占95%的sql的执行时间.
Lock Time, 等待锁的时间. 95% of Lock , 95%的慢sql等待锁时间.
Rows sent, 结果行统计数量, 包括平均, 最小, 最大数量.
Rows examined, 扫描的行数量.
Database, 属于哪个数据库
Users, 哪个用户,IP, 占到所有用户执行的sql百分比
Query abstract, 抽象后的sql语句
Query sample, sql语句
pt-query-digest
pt-query-digest来自伟大的percona-toolkit工具集的一部分,由perl编写,这个工具集提供了很多有用的工具,以后会一一拿出来介绍哦。pt-query-digest它可以剖析各种MySQL的日志,进而为问题分析和诊断提供依据,可分析的日志类型有slow log,general log,binary log,tcpdump等。后续的可视化平台工具也是基于pt-query-digest完成解析慢查询日志后信息入库的。
pt-query-digest –help
pt-query-digest analyzes MySQL queries from slow, general, and binary log files.
It can also analyze queries from C and MySQL protocol data
from tcpdump. By default, queries are grouped by fingerprint and reported in
descending order of query time (i.e. the slowest queries first). If no C
are given, the tool reads C. The optional C is used for certain
options like L<”–since”> and L<”–until”>. For more details, please use the
–help option, or try ‘perldoc /usr/local/bin/pt-query-digest’ for complete
documentation.
Usage: pt-query-digest [OPTIONS] [FILES] [DSN]
Options:
–ask-pass Prompt for a password when connecting to MySQL
–attribute-aliases=a List of attribute|alias,etc (default db|Schema)
–attribute-value-limit=i A sanity limit for attribute values (default
4294967296)
–charset=s -A Default character set
–config=A Read this comma-separated list of config files;
if specified, this must be the first option on
the command line
–[no]continue-on-error Continue parsing even if there is an error (
default yes)
–[no]create-history-table Create the –history table if it does not exist (
default yes)
–[no]create-review-table Create the –review table if it does not exist (
default yes)
–daemonize Fork to the background and detach from the shell
–database=s -D Connect to this database
–defaults-file=s -F Only read mysql options from the given file
–embedded-attributes=a Two Perl regex patterns to capture pseudo-
attributes embedded in queries
–expected-range=a Explain items when there are more or fewer than
expected (default 5,10)
–explain=d Run EXPLAIN for the sample query with this DSN
and print results
–filter=s Discard events for which this Perl code doesn’t
return true
–group-by=A Which attribute of the events to group by (
default fingerprint)
–help Show help and exit
–history=d Save metrics for each query class in the given
table. pt-query-digest saves query metrics (query
time, lock time, etc.) to this table so you can
see how query classes change over time
–host=s -h Connect to host
–ignore-attributes=a Do not aggregate these attributes (default arg,
cmd, insert_id, ip, port, Thread_id, timestamp,
exptime, flags, key, res, val, server_id, offset,
end_log_pos, Xid)
–inherit-attributes=a If missing, inherit these attributes from the
last event that had them (default db,ts)
–interval=f How frequently to poll the processlist, in
seconds (default .1)
–iterations=i How many times to iterate through the collect
4000
-and-
report cycle (default 1)
–limit=A Limit output to the given percentage or count (
default 95%:20)
–log=s Print all output to this file when daemonized
–order-by=A Sort events by this attribute and aggregate
function (default Query_time:sum)
–outliers=a Report outliers by attribute:percentile:count (
default Query_time:1:10)
–output=s How to format and print the query analysis
results (default report)
–password=s -p Password to use when connecting
–pid=s Create the given PID file
–port=i -P Port number to use for connection
–processlist=d Poll this DSN’s processlist for queries, with –
interval sleep between
–progress=a Print progress reports to STDERR (default time,30)
–read-timeout=m Wait this long for an event from the input; 0 to
wait forever (default 0). Optional suffix s=
seconds, m=minutes, h=hours, d=days; if no
suffix, s is used.
–[no]report Print query analysis reports for each –group-by
attribute (default yes)
–report-all Report all queries, even ones that have been
reviewed
–report-format=A Print these sections of the query analysis
report (default rusage,date,hostname,files,header,
profile,query_report,prepared)
–report-histogram=s Chart the distribution of this attribute’s
values (default Query_time)
–resume=s If specified, the tool writes the last file
offset, if there is one, to the given filename
–review=d Save query classes for later review, and don’t
report already reviewed classes
–run-time=m How long to run for each –iterations. Optional
suffix s=seconds, m=minutes, h=hours, d=days; if
no suffix, s is used.
–run-time-mode=s Set what the value of –run-time operates on (
default clock)
–sample=i Filter out all but the first N occurrences of
each query
–set-vars=A Set the MySQL variables in this comma-separated
list of variable=value pairs
–show-all=H Show all values for these attributes
–since=s Parse only queries newer than this value (parse
queries since this date)
–socket=s -S Socket file to use for connection
–timeline Show a timeline of events
–type=A The type of input to parse (default slowlog)
–until=s Parse only queries older than this value (parse
queries until this date)
–user=s -u User for login if not current user
–variations=A Report the number of variations in these
attributes’ values
–version Show version and exit
–[no]version-check Check for the latest version of Percona Toolkit,
MySQL, and other programs (default yes)
–watch-server=s This option tells pt-query-digest which server IP
address and port (like “10.0.0.1:3306”) to watch
when parsing tcpdump (for –type tcpdump); all
other servers are ignored
Option types: s=string, i=integer, f=float, h/H/a/A=comma-separated list, d=DSN, z=size, m=time
Rules:
This tool accepts additional command-line arguments. Refer to the SYNOPSIS and usage information for details.
DSN syntax is key=value[,key=value…] Allowable DSN keys:
KEY COPY MEANING
=== ==== =============================================
A yes Default character set
D yes Default database to use when connecting to MySQL
F yes Only read default options from the given file
P yes Port number to use for connection
S yes Socket file to use for connection
h yes Connect to host
p yes Password to use when connecting
t no The –review or –history table
u yes User for login if not current user
If the DSN is a bareword, the word is treated as the ‘h’ key.
Options and values after processing arguments:
–ask-pass FALSE
–attribute-aliases db|Schema
–attribute-value-limit 4294967296
–charset (No value)
–config /etc/percona-toolkit/percona-toolkit.conf,/etc/percona-toolkit/pt-query-digest.conf,/root/.percona-toolkit.conf,/root/.pt-query-digest.conf
–continue-on-error TRUE
–create-history-table TRUE
–create-review-table TRUE
–daemonize FALSE
–database (No value)
–defaults-file (No value)
–embedded-attributes (No value)
–expected-range 5,10
–explain (No value)
–filter (No value)
–group-by fingerprint
–help TRUE
–history (No value)
–host (No value)
–ignore-attributes arg,cmd,insert_id,ip,port,Thread_id,timestamp,exptime,flags,key,res,val,server_id,offset,end_log_pos,Xid
–inherit-attributes db,ts
–interval .1
–iterations 1
–limit 95%:20
–log (No value)
–order-by Query_time:sum
–outliers Query_time:1:10
–output report
–password (No value)
–pid (No value)
–port (No value)
–processlist (No value)
–progress time,30
–read-timeout 0
–report TRUE
–report-all FALSE
–report-format rusage,date,hostname,files,header,profile,query_report,prepared
–report-histogram Query_time
–resume (No value)
–review (No value)
–run-time (No value)
–run-time-mode clock
–sample (No value)
–set-vars
–show-all
–since (No value)
–socket (No value)
–timeline FALSE
–type slowlog
–until (No value)
–user (No value)
–variations
–version FALSE
–version-check TRUE
–watch-server (No value)
分析慢查询日志用到的主要参数:
–create-review-table 当使用–review参数把分析结果输出到表中时,如果没有表就自动创建。
–create-history-table 当使用–history参数把分析结果输出到表中时,如果没有表就自动创建。
–filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
–limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
–host mysql服务器地址
–user mysql用户名
–password mysql用户密码
–history 将分析结果保存到表中,分析结果比较详细,下次再使用–history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
–review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用–review时,如果存在相同的语句分析,就不会记录到数据表中。
–output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
–since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
–until 截止时间,配合—since可以分析一段时间内的慢查询。
标准输出报告的格式:
输出的报告总共分三个部分
总体汇总结果
verall: 总共有多少条查询,上例为总共266个查询。
Time range: 查询执行的时间范围。
unique: 唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询,该例为55。
total: 总计 min:最小 max: 最大 avg:平均
95%: 把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值。
median: 中位数,把所有值从小到大排列,位置位于中间那个数。
分组统计结果
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
查询详细报告
Databases: 库名
Users: 各个用户执行的次数(占比)
Query_time distribution : 查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables: 查询中涉及到的表
Explain: 示例

相关文章推荐
- 找不到mysql.sock的出现原因及解决方案和mysql 默认mysql.sock位置默认问题探讨
- mysql 设置 utf-8
- Mysql 忘记密码
- Mysql操作常用命令
- MySQL 最基本的SQL语法/语句
- Mysql导出excel表格的命令
- mysql里筛选生日
- mysql中IFNULL()和COALESCE()函数替代null
- mysql中文乱码问题
- Mysql binlog二进制日志
- mysql创建用户、删除用户、创建root用户和修改用户密码,grant分配权限,查询测试,以及库中授权表解析
- mysql中选择当前日期的记录
- mysql里的like问题
- 【未完】mysql创建和删除表
- mysql的一点语法
- mysql ERROR 1045 (28000): 错误解决办法
- mysql添加、修改字段
- mysql int(x) 显示宽度
- MySQL查询语句大全集锦
- mysql数据库MyISAM与InnoDB比较与选择