Hadoop去掉格,换行符,制表符,回车符,换页符【好吧,其实用正则表达式一下子就搞定了】
2015-09-07 20:40
471 查看
第一步:将文档中的空格,换行符(\n),制表符(\t),回车符(\n),换页符(\f)去掉
这时候可以采用两种方法
1.使用Hadoop将文本以默认的分隔符(空格,换行符,制表符,回车符,换页符)进行分割,并将分割后的字符串直接输出,这样子新的文档中将不包括这些分隔符。
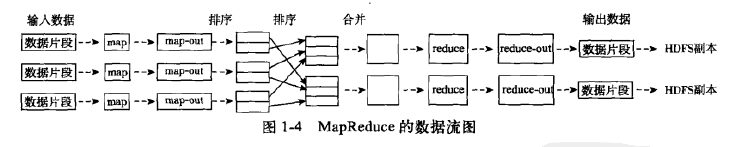
以上代码可以执行并得到所需结果,但有一个缺点是会将输入文件中的文字的顺序打乱即输出文件中的文字顺序和输入文件的不同。
这是由于在shuffle过程中对map的输出 重新进行了排序,如果是英文的话是按照a-z的字母表顺序。、

另外执行hadoop程序可借助shell编程,减少重复敲代码。而shell中的内容直接写命令即可。
这时候可以采用两种方法
1.使用Hadoop将文本以默认的分隔符(空格,换行符,制表符,回车符,换页符)进行分割,并将分割后的字符串直接输出,这样子新的文档中将不包括这些分隔符。
/**
这里在Map中去除空格、tab、回车等
*/
import java.io.*;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Standardization {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”,换页(‘\f’)
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);//将分隔分割成功的文本直接输出就排除了这些分隔符
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(1);
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
PrintWriter outputStream=null;//这个被创建的文件将在jar所在目录下生成,而不会在存在于dfs
try{
outputStream =new PrintWriter(new FileOutputStream("out.txt",true));
}
catch(FileNotFoundException e){
System.out.println("没有权限");
System.exit(0);
}
outputStream.print(key.toString());
outputStream.close();
context.write(key,result);//而这里的内容将被卸载dfs上
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(Standardization.class);
job.setMapperClass(TokenizerMapper.class);
//这里并没有配置shuffle
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}以上代码可以执行并得到所需结果,但有一个缺点是会将输入文件中的文字的顺序打乱即输出文件中的文字顺序和输入文件的不同。
这是由于在shuffle过程中对map的输出 重新进行了排序,如果是英文的话是按照a-z的字母表顺序。、
另外执行hadoop程序可借助shell编程,减少重复敲代码。而shell中的内容直接写命令即可。

相关文章推荐
- Linux-4.1.6 内核编译安装(ubuntu)
- Linux下的I/O复用与epoll详解
- RHEL/CentOS安装EPEL的YUM源
- linux下tar.xz文件解压缩
- Linux&C ——信号以及信号处理
- Linux 纯字符界面的玩法
- pop 一个viewController时候会有键盘闪现出来又消失
- pop 一个viewController时候会有键盘闪现出来又消失
- Linux串口调试软件serials
- Mac 配置 Apache .php
- Popular Cows
- 熟悉linux-安装jdk
- Could not publish server configuration for Tomcat v6.0 Server at localhost
- centos6.7 32位系统安装后无法连接wifi,原因是没有安装相应的无线网卡驱动
- tomcat7自身调优和JVM调优
- linux下使用tar命令
- linux基础名词
- Linux下小工具使用总结
- linux周期性任务计划 at及cron的简单总结
- ecshop首页调用指定商品分类下的商品品牌列表