bit-map 详解
2015-09-02 16:57
260 查看
《海量数据处理算法》
原文链接: /article/7644687.html
1. Bit Map算法简介
来自于《编程珠玑》。所谓的Bit-map就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
2、 Bit Map的基本思想
我们先来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图: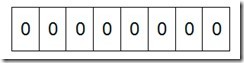
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
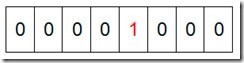
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
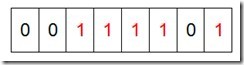
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
3、 Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
3、 位移转换
申请一个int一维数组,那么可以当作为列为32位的二维数组,| 32位 |
int a[0] |0000000000000000000000000000000000000|
int a[1] |0000000000000000000000000000000000000|
………………
int a
|0000000000000000000000000000000000000|
例如十进制0,对应在a[0]所占的bit为中的第一位: 0000000000000000000000000000000[b]1
0-31:对应在a[0]中
i =0 00000000000000000000000000000000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =1 00000000000000000000000000000001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =2 00000000000000000000000000000010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =30 00000000000000000000000000011110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =31 00000000000000000000000000011111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
32-63:对应在a[1]中
i =32 00000000000000000000000000100000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =33 00000000000000000000000000100001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =34 00000000000000000000000000100010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =61 00000000000000000000000000111101
temp=29 00000000000000000000000000011101
answer=536870912 00100000000000000000000000000000
i =62 00000000000000000000000000111110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =63 00000000000000000000000000111111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
浅析上面的对应表,分三步:
1.求十进制0-N对应在数组a中的下标:
十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
2.求0-N对应0-31中的数:
十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
3.利用移位0-31使得对应32bit位为1.
找到对应0-31的数为M, 左移M位:即2^M. 然后置1.
由此我们计算10000000个bit占用的空间:
1byte = 8bit
1kb
= 1024byte
1mb
= 1024kb
占用的空间为:10000000/8/1024/1024mb。
大概为1mb多一些。
3、 扩展
Bloom filter可以看做是对bit-map的扩展
4、 Bit-Map的应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。2)去重数据而达到压缩数据
5、 Bit-Map的具体实现
c语言实现:#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];//申请内存的大小
//set 设置所在的bit位为1
void set(int i) {
a[i>>SHIFT] |= (1<<(i & MASK));
}
//clr 初始化所有的bit位为0
void clr(int i) {
a[i>>SHIFT] &= ~(1<<(i & MASK));
}
//test 测试所在的bit为是否为1
int test(int i){
return a[i>>SHIFT] & (1<<(i & MASK));
}
int main()
{ int i;
for (i = 0; i < N; i++)
clr(i);
while (scanf("%d", &i) != EOF)
set(i);
for (i = 0; i < N; i++)
if (test(i))
printf("%d\n", i);
return 0;
}
注明: 左移n位就是乘以2的n次方,右移n位就是除以2的n次方
解析本例中的void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
1) i>>SHIFT:
其中SHIFT=5,即i右移5为,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。比如i=20,通过i>>SHIFT=20>>5=0 可求得i=20的下标为0;
2) i & MASK:
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。
比如i=23,二进制为:0001 0111,那么
0001 0111
& 0001 1111 = 0001 0111 十进制为:23
比如i=83,二进制为:0000 0000 0101 0011,那么
0000 0000 0101 0011
& 0000 0000 0001 0000 = 0000 0000 0001 0011 十进制为:19
i & MASK相当于i%32。
3) 1<<(i & MASK)
相当于把1左移 (i & MASK)位。
比如(i & MASK)=20,那么i<<20就相当于:
0000 0000 0000 0000 0000 0000 0000 0001 << 20
=0000 0000 0001 0000 0000 0000 0000 0000
注意上面 “|=”.
在博文:位运算符及其应用 提到过这样位运算应用:
将int型变量a的第k位清0,即a=a&~(1<<k)
将int型变量a的第k位置1, 即a=a|(1<<k)
这里的将 a[i/32] |= (1<<M)); 第M位置1 .
4) void set(int i) { a[i>>SHIFT] |=
(1<<(i & MASK)); }等价于:
void set(int i)
{
a[i/32] |= (1<<(i%32));
}
即实现上面提到的三步:
1.求十进制0-N对应在数组a中的下标: n/32
2.求0-N对应0-31中的数: N%32=M
3.利用移位0-31使得对应32bit位为1: 1<<M,并置1;
php实现是一样的:
<?php
error_reporting(E_ERROR);
define("MASK", 0x1f);//31
define("BITSPERWORD",32);
define("SHIFT",5);
define("MASK",0x1F);
define("N",1000);
$a = array();
//set 设置所在的bit位为1
function set($i) {
global $a;
$a[$i>>SHIFT] |= (1<<($i & MASK));
}
//clr 初始化所有的bit位为0
function clr($i) {
$a[$i>>SHIFT] &= ~(1<<($i & MASK));
}
//test 测试所在的bit为是否为1
function test($i){
global $a;
return $a[$i>>SHIFT] & (1<<($i & MASK));
}
$aa = array(1,2,3,31, 33,56,199,30,50);
while ($v =current($aa)) {
set($v);
if(!next($aa)) {
break;
}
}
foreach ($a as $key=>$v){
echo $key,'=', decbin($v),"\r\n";
}
然后我们打印结果:
0=11000000000000000000000000001110
1=1000001000000000000000010
6=10000000
32位表示,实际结果一目了然了,看看1,2,3,30,31, 33,50,56,199数据所在的具体位置:
31 30 3 2 1

0= 1 1 00 0000 0000 0000 0000 0000 0000 1 1 1 0
56 50
33
1= 0000 0001 0000 0100 0000 0000 0000 0010
199
6= 0000 0000 0000 0000 0000 0000 1000 0000
【问题实例】
已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
实现:
// TestWin32.cpp : Defines the entry point for the console application.
#include "stdafx.h"
#include<memory.h>
//用char数组存储2-Bitmap,不用考虑大小端内存的问题
unsigned char flags[1000]; //数组大小自定义
unsigned get_val(int idx) {
// | 8 bit |
// |00 00 00 00| //映射3 2 1 0
// |00 00 00 00| //表示7 6 5 4
// ……
// |00 00 00 00|
int i = idx/4; //一个char 表示4个数,
int j = idx%4;
unsigned ret = (flags[i]&(0x3<<(2*j)))>>(2*j);
//0x3是0011 j的范围为0-3,因此0x3<<(2*j)范围为00000011到11000000 如idx=7 i=1 ,j=3 那么flags[1]&11000000, 得到的是|00 00 00 00|
//表示7 6 5 4
return ret;
}
unsigned set_val(int idx, unsigned int val) {
int i = idx/4;
int j = idx%4;
unsigned tmp = (flags[i]&~((0x3<<(2*j))&0xff)) | (((val%4)<<(2*j))&0xff);
flags[i] = tmp;
return 0;
}
unsigned add_one(int idx)
{
if (get_val(idx)>=2) { //这一位置上已经出现过了??
return 1;
} else {
set_val(idx, get_val(idx)+1);
return 0;
}
}
//只测试非负数的情况;
//假如考虑负数的话,需增加一个2-Bitmap数组.
int a[]={1, 3, 5, 7, 9, 1, 3, 5, 7, 1, 3, 5,1, 3, 1,10,2,4,6,8,0};
int main() {
int i;
memset(flags, 0, sizeof(flags));
printf("原数组为:");
for(i=0;i < sizeof(a)/sizeof(int); ++i) {
printf("%d ", a[i]);
add_one(a[i]);
}
printf("\r\n");
printf("只出现过一次的数:");
for(i=0;i < 100; ++i) {
if(get_val(i) == 1)
printf("%d ", i);
}
printf("\r\n");
return 0;
}
海量数据处理算法原文链接: /article/7644687.html[/b]
1. Bit Map算法简介
来自于《编程珠玑》。所谓的Bit-map就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
2、 Bit Map的基本思想
我们先来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图:然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
3、 Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
3、 位移转换
申请一个int一维数组,那么可以当作为列为32位的二维数组,| 32位 |
int a[0] |0000000000000000000000000000000000000|
int a[1] |0000000000000000000000000000000000000|
………………
int a
|0000000000000000000000000000000000000|
例如十进制0,对应在a[0]所占的bit为中的第一位: 00000000000000000000000000000001
0-31:对应在a[0]中
i =0 00000000000000000000000000000000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =1 00000000000000000000000000000001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =2 00000000000000000000000000000010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =30 00000000000000000000000000011110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =31 00000000000000000000000000011111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
32-63:对应在a[1]中
i =32 00000000000000000000000000100000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =33 00000000000000000000000000100001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =34 00000000000000000000000000100010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =61 00000000000000000000000000111101
temp=29 00000000000000000000000000011101
answer=536870912 00100000000000000000000000000000
i =62 00000000000000000000000000111110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =63 00000000000000000000000000111111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
浅析上面的对应表,分三步:
1.求十进制0-N对应在数组a中的下标:
十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
2.求0-N对应0-31中的数:
十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
3.利用移位0-31使得对应32bit位为1.
找到对应0-31的数为M, 左移M位:即2^M. 然后置1.
由此我们计算10000000个bit占用的空间:
1byte = 8bit
1kb
= 1024byte
1mb
= 1024kb
占用的空间为:10000000/8/1024/1024mb。
大概为1mb多一些。
3、 扩展
Bloom filter可以看做是对bit-map的扩展
4、 Bit-Map的应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。2)去重数据而达到压缩数据
5、 Bit-Map的具体实现
c语言实现:#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];//申请内存的大小
//set 设置所在的bit位为1
void set(int i) {
a[i>>SHIFT] |= (1<<(i & MASK));
}
//clr 初始化所有的bit位为0
void clr(int i) {
a[i>>SHIFT] &= ~(1<<(i & MASK));
}
//test 测试所在的bit为是否为1
int test(int i){
return a[i>>SHIFT] & (1<<(i & MASK));
}
int main()
{ int i;
for (i = 0; i < N; i++)
clr(i);
while (scanf("%d", &i) != EOF)
set(i);
for (i = 0; i < N; i++)
if (test(i))
printf("%d\n", i);
return 0;
}
注明: 左移n位就是乘以2的n次方,右移n位就是除以2的n次方
解析本例中的void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
1) i>>SHIFT:
其中SHIFT=5,即i右移5为,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。比如i=20,通过i>>SHIFT=20>>5=0 可求得i=20的下标为0;
2) i & MASK:
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。
比如i=23,二进制为:0001 0111,那么
0001 0111
& 0001 1111 = 0001 0111 十进制为:23
比如i=83,二进制为:0000 0000 0101 0011,那么
0000 0000 0101 0011
& 0000 0000 0001 0000 = 0000 0000 0001 0011 十进制为:19
i & MASK相当于i%32。
3) 1<<(i & MASK)
相当于把1左移 (i & MASK)位。
比如(i & MASK)=20,那么i<<20就相当于:
0000 0000 0000 0000 0000 0000 0000 0001 << 20
=0000 0000 0001 0000 0000 0000 0000 0000
注意上面 “|=”.
在博文:位运算符及其应用 提到过这样位运算应用:
将int型变量a的第k位清0,即a=a&~(1<<k)
将int型变量a的第k位置1, 即a=a|(1<<k)
这里的将 a[i/32] |= (1<<M)); 第M位置1 .
4) void set(int i) { a[i>>SHIFT] |=
(1<<(i & MASK)); }等价于:
void set(int i)
{
a[i/32] |= (1<<(i%32));
}
即实现上面提到的三步:
1.求十进制0-N对应在数组a中的下标: n/32
2.求0-N对应0-31中的数: N%32=M
3.利用移位0-31使得对应32bit位为1: 1<<M,并置1;
php实现是一样的:
<?php
error_reporting(E_ERROR);
define("MASK", 0x1f);//31
define("BITSPERWORD",32);
define("SHIFT",5);
define("MASK",0x1F);
define("N",1000);
$a = array();
//set 设置所在的bit位为1
function set($i) {
global $a;
$a[$i>>SHIFT] |= (1<<($i & MASK));
}
//clr 初始化所有的bit位为0
function clr($i) {
$a[$i>>SHIFT] &= ~(1<<($i & MASK));
}
//test 测试所在的bit为是否为1
function test($i){
global $a;
return $a[$i>>SHIFT] & (1<<($i & MASK));
}
$aa = array(1,2,3,31, 33,56,199,30,50);
while ($v =current($aa)) {
set($v);
if(!next($aa)) {
break;
}
}
foreach ($a as $key=>$v){
echo $key,'=', decbin($v),"\r\n";
}
然后我们打印结果:
0=11000000000000000000000000001110
1=1000001000000000000000010
6=10000000
32位表示,实际结果一目了然了,看看1,2,3,30,31, 33,50,56,199数据所在的具体位置:
31 30 3 2 1
0= 1 1 00 0000 0000 0000 0000 0000 0000 1 1 1 0
56 50
33
1= 0000 0001 0000 0100 0000 0000 0000 0010
199
6= 0000 0000 0000 0000 0000 0000 1000 0000
【问题实例】
已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
实现:
// TestWin32.cpp : Defines the entry point for the console application.
#include "stdafx.h"
#include<memory.h>
//用char数组存储2-Bitmap,不用考虑大小端内存的问题
unsigned char flags[1000]; //数组大小自定义
unsigned get_val(int idx) {
// | 8 bit |
// |00 00 00 00| //映射3 2 1 0
// |00 00 00 00| //表示7 6 5 4
// ……
// |00 00 00 00|
int i = idx/4; //一个char 表示4个数,
int j = idx%4;
unsigned ret = (flags[i]&(0x3<<(2*j)))>>(2*j);
//0x3是0011 j的范围为0-3,因此0x3<<(2*j)范围为00000011到11000000 如idx=7 i=1 ,j=3 那么flags[1]&11000000, 得到的是|00 00 00 00|
//表示7 6 5 4
return ret;
}
unsigned set_val(int idx, unsigned int val) {
int i = idx/4;
int j = idx%4;
unsigned tmp = (flags[i]&~((0x3<<(2*j))&0xff)) | (((val%4)<<(2*j))&0xff);
flags[i] = tmp;
return 0;
}
unsigned add_one(int idx)
{
if (get_val(idx)>=2) { //这一位置上已经出现过了??
return 1;
} else {
set_val(idx, get_val(idx)+1);
return 0;
}
}
//只测试非负数的情况;
//假如考虑负数的话,需增加一个2-Bitmap数组.
int a[]={1, 3, 5, 7, 9, 1, 3, 5, 7, 1, 3, 5,1, 3, 1,10,2,4,6,8,0};
int main() {
int i;
memset(flags, 0, sizeof(flags));
printf("原数组为:");
for(i=0;i < sizeof(a)/sizeof(int); ++i) {
printf("%d ", a[i]);
add_one(a[i]);
}
printf("\r\n");
printf("只出现过一次的数:");
for(i=0;i < 100; ++i) {
if(get_val(i) == 1)
printf("%d ", i);
}
printf("\r\n");
return 0;
}
海量数据处理算法
原文链接: /article/7644687.html
1. Bit Map算法简介
来自于《编程珠玑》。所谓的Bit-map就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
2、 Bit Map的基本思想
我们先来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图:然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
3、 Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
3、 位移转换
申请一个int一维数组,那么可以当作为列为32位的二维数组,| 32位 |
int a[0] |0000000000000000000000000000000000000|
int a[1] |0000000000000000000000000000000000000|
………………
int a
|0000000000000000000000000000000000000|
例如十进制0,对应在a[0]所占的bit为中的第一位: 00000000000000000000000000000001
0-31:对应在a[0]中
i =0 00000000000000000000000000000000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =1 00000000000000000000000000000001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =2 00000000000000000000000000000010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =30 00000000000000000000000000011110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =31 00000000000000000000000000011111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
32-63:对应在a[1]中
i =32 00000000000000000000000000100000
temp=0 00000000000000000000000000000000
answer=1 00000000000000000000000000000001
i =33 00000000000000000000000000100001
temp=1 00000000000000000000000000000001
answer=2 00000000000000000000000000000010
i =34 00000000000000000000000000100010
temp=2 00000000000000000000000000000010
answer=4 00000000000000000000000000000100
i =61 00000000000000000000000000111101
temp=29 00000000000000000000000000011101
answer=536870912 00100000000000000000000000000000
i =62 00000000000000000000000000111110
temp=30 00000000000000000000000000011110
answer=1073741824 01000000000000000000000000000000
i =63 00000000000000000000000000111111
temp=31 00000000000000000000000000011111
answer=-2147483648 10000000000000000000000000000000
浅析上面的对应表,分三步:
1.求十进制0-N对应在数组a中的下标:
十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
2.求0-N对应0-31中的数:
十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
3.利用移位0-31使得对应32bit位为1.
找到对应0-31的数为M, 左移M位:即2^M. 然后置1.
由此我们计算10000000个bit占用的空间:
1byte = 8bit
1kb
= 1024byte
1mb
= 1024kb
占用的空间为:10000000/8/1024/1024mb。
大概为1mb多一些。
3、 扩展
Bloom filter可以看做是对bit-map的扩展
4、 Bit-Map的应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。2)去重数据而达到压缩数据
5、 Bit-Map的具体实现
c语言实现:#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];//申请内存的大小
//set 设置所在的bit位为1
void set(int i) {
a[i>>SHIFT] |= (1<<(i & MASK));
}
//clr 初始化所有的bit位为0
void clr(int i) {
a[i>>SHIFT] &= ~(1<<(i & MASK));
}
//test 测试所在的bit为是否为1
int test(int i){
return a[i>>SHIFT] & (1<<(i & MASK));
}
int main()
{ int i;
for (i = 0; i < N; i++)
clr(i);
while (scanf("%d", &i) != EOF)
set(i);
for (i = 0; i < N; i++)
if (test(i))
printf("%d\n", i);
return 0;
}
注明: 左移n位就是乘以2的n次方,右移n位就是除以2的n次方
解析本例中的void set(int i) { a[i>>SHIFT] |= (1<<(i & MASK)); }
1) i>>SHIFT:
其中SHIFT=5,即i右移5为,2^5=32,相当于i/32,即求出十进制i对应在数组a中的下标。比如i=20,通过i>>SHIFT=20>>5=0 可求得i=20的下标为0;
2) i & MASK:
其中MASK=0X1F,十六进制转化为十进制为31,二进制为0001 1111,i&(0001 1111)相当于保留i的后5位。
比如i=23,二进制为:0001 0111,那么
0001 0111
& 0001 1111 = 0001 0111 十进制为:23
比如i=83,二进制为:0000 0000 0101 0011,那么
0000 0000 0101 0011
& 0000 0000 0001 0000 = 0000 0000 0001 0011 十进制为:19
i & MASK相当于i%32。
3) 1<<(i & MASK)
相当于把1左移 (i & MASK)位。
比如(i & MASK)=20,那么i<<20就相当于:
0000 0000 0000 0000 0000 0000 0000 0001 << 20
=0000 0000 0001 0000 0000 0000 0000 0000
注意上面 “|=”.
在博文:位运算符及其应用 提到过这样位运算应用:
将int型变量a的第k位清0,即a=a&~(1<<k)
将int型变量a的第k位置1, 即a=a|(1<<k)
这里的将 a[i/32] |= (1<<M)); 第M位置1 .
4) void set(int i) { a[i>>SHIFT] |=
(1<<(i & MASK)); }等价于:
void set(int i)
{
a[i/32] |= (1<<(i%32));
}
即实现上面提到的三步:
1.求十进制0-N对应在数组a中的下标: n/32
2.求0-N对应0-31中的数: N%32=M
3.利用移位0-31使得对应32bit位为1: 1<<M,并置1;
php实现是一样的:
<?php
error_reporting(E_ERROR);
define("MASK", 0x1f);//31
define("BITSPERWORD",32);
define("SHIFT",5);
define("MASK",0x1F);
define("N",1000);
$a = array();
//set 设置所在的bit位为1
function set($i) {
global $a;
$a[$i>>SHIFT] |= (1<<($i & MASK));
}
//clr 初始化所有的bit位为0
function clr($i) {
$a[$i>>SHIFT] &= ~(1<<($i & MASK));
}
//test 测试所在的bit为是否为1
function test($i){
global $a;
return $a[$i>>SHIFT] & (1<<($i & MASK));
}
$aa = array(1,2,3,31, 33,56,199,30,50);
while ($v =current($aa)) {
set($v);
if(!next($aa)) {
break;
}
}
foreach ($a as $key=>$v){
echo $key,'=', decbin($v),"\r\n";
}
然后我们打印结果:
0=11000000000000000000000000001110
1=1000001000000000000000010
6=10000000
32位表示,实际结果一目了然了,看看1,2,3,30,31, 33,50,56,199数据所在的具体位置:
31 30 3 2 1
0= 1 1 00 0000 0000 0000 0000 0000 0000 1 1 1 0
56 50
33
1= 0000 0001 0000 0100 0000 0000 0000 0010
199
6= 0000 0000 0000 0000 0000 0000 1000 0000
【问题实例】
已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
实现:
// TestWin32.cpp : Defines the entry point for the console application.
#include "stdafx.h"
#include<memory.h>
//用char数组存储2-Bitmap,不用考虑大小端内存的问题
unsigned char flags[1000]; //数组大小自定义
unsigned get_val(int idx) {
// | 8 bit |
// |00 00 00 00| //映射3 2 1 0
// |00 00 00 00| //表示7 6 5 4
// ……
// |00 00 00 00|
int i = idx/4; //一个char 表示4个数,
int j = idx%4;
unsigned ret = (flags[i]&(0x3<<(2*j)))>>(2*j);
//0x3是0011 j的范围为0-3,因此0x3<<(2*j)范围为00000011到11000000 如idx=7 i=1 ,j=3 那么flags[1]&11000000, 得到的是|00 00 00 00|
//表示7 6 5 4
return ret;
}
unsigned set_val(int idx, unsigned int val) {
int i = idx/4;
int j = idx%4;
unsigned tmp = (flags[i]&~((0x3<<(2*j))&0xff)) | (((val%4)<<(2*j))&0xff);
flags[i] = tmp;
return 0;
}
unsigned add_one(int idx)
{
if (get_val(idx)>=2) { //这一位置上已经出现过了??
return 1;
} else {
set_val(idx, get_val(idx)+1);
return 0;
}
}
//只测试非负数的情况;
//假如考虑负数的话,需增加一个2-Bitmap数组.
int a[]={1, 3, 5, 7, 9, 1, 3, 5, 7, 1, 3, 5,1, 3, 1,10,2,4,6,8,0};
int main() {
int i;
memset(flags, 0, sizeof(flags));
printf("原数组为:");
for(i=0;i < sizeof(a)/sizeof(int); ++i) {
printf("%d ", a[i]);
add_one(a[i]);
}
printf("\r\n");
printf("只出现过一次的数:");
for(i=0;i < 100; ++i) {
if(get_val(i) == 1)
printf("%d ", i);
}
printf("\r\n");
return 0;
}
《bit-map简介及其C/C++代码实现》
原文链接:/article/2222597.html
在本文中, 我们来介绍一下bit-map,你可别以为这是什么bitmap图像, 那本文要介绍的bit-map是什么呢? 且听我慢慢道来。
坐过火车没? 当你在火车上, 想拉屎的时候, 你得去上厕所啊。 屁颠屁颠爬到厕所处, 发现上面亮了一个灯, 表示里面有人, 你郁闷至极, 但无可奈何。 过了很久, 那个人出来了, 那个灯也就熄灭了, 你就可以上厕所了。
这个灯, 就是计算机中的一个bit, 有两种状态 , 1表示有人在厕所中, 0表示没有人在厕所中。 所以, 从这个意义上说, 一个bit可以标志某事物的一个状态, 当这个bit与某事物状态建立映射后, 我说们, 形成了一个bit到事物状态的map.
我们知道, 一个unsign char有8bit, 也就是说, 一个无符号字符可以标志某个厕所的8个坑位的状态, 下面我们看看程序:
[cpp] view
plaincopy


#include <iostream>
using namespace std;
int main(void)
{
unsigned char c;
// 8个坑位都没有人
c = 0;
// 8个坑位都有人
c = 255;
// 第1个(也可以认为是第0个)坑位有人
c = 128;
// 最后两个坑位有人
c = 3;
return 0;
}
看到没? 一个bit标志一个坑, 标志一个事物的状态, 那么一个unsigned char标志着8个事物的状态。 同理, 一个unsigned int标志着32个事物的状态, 其实一个int也可以标志着32个事物的状态。(当然,
这里所说的状态都是二值状态)
现在, 假设有N个事物状态, 那至少需要多少个int来表示呢? 很显然是 N/32 + 1. 假设有100个事物(N=100), 那至少需要4个int (总共128位). 说的有点多了, 直接看程序吧:
[cpp] view
plaincopy
#include <iostream>
using namespace std;
#define BIT_INT 32 // 1个int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 100
int a[1 + N / BIT_INT]; // 需要1 + N / BIT_INT 个整数来标志N个事物
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(int));
}
// 设置第i位为1, 表示有人在厕所里面
void setOne(int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1, 表示没有人在厕所里面
void setZero(int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值, 看看有没有人在厕所里面
int getState(int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
int main(void)
{
int bitNumber = (1 + N / BIT_INT) * BIT_INT;
cout << bitNumber << endl;
setAllZero();
int i = 0;
for(i = 0; i < bitNumber; i++)
{
cout << getState(i);
}
cout << endl;
setOne(0);
setOne(1);
setOne(2);
setOne(3);
setOne(4);
for(i = 0; i < bitNumber; i++)
{
cout << getState(i);
}
cout << endl;
setZero(0);
setZero(1);
setZero(2);
for(i = 0; i < bitNumber; i++)
{
cout << getState(i);
}
cout << endl;
return 0;
}
看看结果吧:
128
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
11111000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00011000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
果然, 结果与预期符合。
我们再看程序:
[cpp] view
plaincopy
#include <iostream>
#include <set>
using namespace std;
#define BIT_INT 32 // 1个int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 100
int a[1 + N / BIT_INT]; // 需要1 + N / BIT_INT 个整数来标志N个事物
// 产生伪随机数
unsigned int getRandom()
{
return rand();
}
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(int));
}
// 设置第i位为1, 表示有人在厕所里面
void setOne(int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1, 表示没有人在厕所里面
void setZero(int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值, 看看有没有人在厕所里面
int getState(int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
int main(void)
{
int r = N;
int size = 40; // 假设有40个事物(数字), 他们在[0, N-1]这个区间内
// 构造40个互不相等的事物, 实际上, s中的元素是有序的, 但在该程序中, 我们不需要太关注这个
set<int> s;
while(size != s.size())
{
s.insert(getRandom() % r);
}
// 将所有坑位的人赶出来, 初始化
setAllZero();
set<int>::iterator it;
for(it = s.begin(); it != s.end(); it++)
{
setOne(*it); // 将事物*it与其对应的坑位*it联系起来, 当*it这个事物存在时, 对应的坑位*it的状态为1
cout << *it << " ";
}
cout << endl;
int i = 0;
int bitNumber = (1 + N / BIT_INT) * BIT_INT;
for(i = 0; i < bitNumber; i++)
{
cout << i << "对应的坑位状态为:--->" << getState(i) << endl; // 获取坑位状态
}
cout << endl;
return 0;
}
结果为:
0 2 3 4 5 11 12 16 18 21 22 24 26 27 33 34 35 36 38 41 42 45 47 53 58 61 62 64 67 69 71 73 78 81 82 91 92 94 95 99
0对应的坑位状态为:--->1
1对应的坑位状态为:--->0
2对应的坑位状态为:--->1
3对应的坑位状态为:--->1
4对应的坑位状态为:--->1
5对应的坑位状态为:--->1
6对应的坑位状态为:--->0
7对应的坑位状态为:--->0
8对应的坑位状态为:--->0
9对应的坑位状态为:--->0
10对应的坑位状态为:--->0
11对应的坑位状态为:--->1
12对应的坑位状态为:--->1
13对应的坑位状态为:--->0
14对应的坑位状态为:--->0
15对应的坑位状态为:--->0
16对应的坑位状态为:--->1
17对应的坑位状态为:--->0
18对应的坑位状态为:--->1
19对应的坑位状态为:--->0
20对应的坑位状态为:--->0
21对应的坑位状态为:--->1
22对应的坑位状态为:--->1
23对应的坑位状态为:--->0
24对应的坑位状态为:--->1
25对应的坑位状态为:--->0
26对应的坑位状态为:--->1
27对应的坑位状态为:--->1
28对应的坑位状态为:--->0
29对应的坑位状态为:--->0
30对应的坑位状态为:--->0
31对应的坑位状态为:--->0
32对应的坑位状态为:--->0
33对应的坑位状态为:--->1
34对应的坑位状态为:--->1
35对应的坑位状态为:--->1
36对应的坑位状态为:--->1
37对应的坑位状态为:--->0
38对应的坑位状态为:--->1
39对应的坑位状态为:--->0
40对应的坑位状态为:--->0
41对应的坑位状态为:--->1
42对应的坑位状态为:--->1
43对应的坑位状态为:--->0
44对应的坑位状态为:--->0
45对应的坑位状态为:--->1
46对应的坑位状态为:--->0
47对应的坑位状态为:--->1
48对应的坑位状态为:--->0
49对应的坑位状态为:--->0
50对应的坑位状态为:--->0
51对应的坑位状态为:--->0
52对应的坑位状态为:--->0
53对应的坑位状态为:--->1
54对应的坑位状态为:--->0
55对应的坑位状态为:--->0
56对应的坑位状态为:--->0
57对应的坑位状态为:--->0
58对应的坑位状态为:--->1
59对应的坑位状态为:--->0
60对应的坑位状态为:--->0
61对应的坑位状态为:--->1
62对应的坑位状态为:--->1
63对应的坑位状态为:--->0
64对应的坑位状态为:--->1
65对应的坑位状态为:--->0
66对应的坑位状态为:--->0
67对应的坑位状态为:--->1
68对应的坑位状态为:--->0
69对应的坑位状态为:--->1
70对应的坑位状态为:--->0
71对应的坑位状态为:--->1
72对应的坑位状态为:--->0
73对应的坑位状态为:--->1
74对应的坑位状态为:--->0
75对应的坑位状态为:--->0
76对应的坑位状态为:--->0
77对应的坑位状态为:--->0
78对应的坑位状态为:--->1
79对应的坑位状态为:--->0
80对应的坑位状态为:--->0
81对应的坑位状态为:--->1
82对应的坑位状态为:--->1
83对应的坑位状态为:--->0
84对应的坑位状态为:--->0
85对应的坑位状态为:--->0
86对应的坑位状态为:--->0
87对应的坑位状态为:--->0
88对应的坑位状态为:--->0
89对应的坑位状态为:--->0
90对应的坑位状态为:--->0
91对应的坑位状态为:--->1
92对应的坑位状态为:--->1
93对应的坑位状态为:--->0
94对应的坑位状态为:--->1
95对应的坑位状态为:--->1
96对应的坑位状态为:--->0
97对应的坑位状态为:--->0
98对应的坑位状态为:--->0
99对应的坑位状态为:--->1
100对应的坑位状态为:--->0
101对应的坑位状态为:--->0
102对应的坑位状态为:--->0
103对应的坑位状态为:--->0
104对应的坑位状态为:--->0
105对应的坑位状态为:--->0
106对应的坑位状态为:--->0
107对应的坑位状态为:--->0
108对应的坑位状态为:--->0
109对应的坑位状态为:--->0
110对应的坑位状态为:--->0
111对应的坑位状态为:--->0
112对应的坑位状态为:--->0
113对应的坑位状态为:--->0
114对应的坑位状态为:--->0
115对应的坑位状态为:--->0
116对应的坑位状态为:--->0
117对应的坑位状态为:--->0
118对应的坑位状态为:--->0
119对应的坑位状态为:--->0
120对应的坑位状态为:--->0
121对应的坑位状态为:--->0
122对应的坑位状态为:--->0
123对应的坑位状态为:--->0
124对应的坑位状态为:--->0
125对应的坑位状态为:--->0
126对应的坑位状态为:--->0
127对应的坑位状态为:--->0
现在应该完成清楚了bit-map吧, 所谓bit-map, 实际上就是用一个bit去map一个事物的状态(二值状态). bit-map的好处是: 节省空间。
实际上, bit-map在大数据处理中经常会用到, 一些笔试面试题经常考, 后续我们会陆续介绍到。
《bitmap再出江湖:a.txt中有40亿个无符号整数, b.txt中有10000个无符号整数,
求交集。 可用内存:1G》
原文链接: http://blog.csdn.net/stpeace/article/details/47285163
之前聊过很多与bitmap有关的东东, 今天我们来看这样一个问题:a.txt中有40亿个无符号整数, b.txt中有10000个无符号整数, 求交集。 可用内存:1G.
很简单, 还是用bitmap, 思路我就不说了, 因为思路完全在下面的代码中:
[cpp] view
plaincopy
#include <iostream>
#include <fstream>
using namespace std;
#define BIT_INT 32 // 1个unsigned int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 4294967296 // 2的32次方
unsigned int *a = NULL;
// 必须用堆
void createArr()
{
a = new unsigned int[1 + N / BIT_INT];
}
void deleteArr()
{
delete []a;
a = NULL;
}
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(unsigned int));
}
// 设置第i位为1
void setOne(unsigned int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1
void setZero(unsigned int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值
int getState(unsigned int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
// 用bitmap记录是否存在
void setStateFromFile()
{
ifstream cin("a.txt");
unsigned int n;
while(cin >> n)
{
setOne(n);
}
}
// 哈哈
void printCommonNumber()
{
ifstream cin("b.txt");
unsigned int n;
while(cin >> n)
{
if(1 == getState(n))
{
cout << n << " ";
}
}
cout << endl;
}
int main()
{
createArr();
setAllZero();
// a.txt: 4 5 7 2 9 2 4 8 0 11 (其实a.txt中可以有40亿个无符号整数)
// b.txt: 6 11 0 2 3 (其实b.txt中可以有10000个无符号整数)
setStateFromFile();
printCommonNumber(); // 11 0 2
deleteArr();
return 0;
}
OK, 不多说, 一切思路尽在代码之中。
《2路bit-map的应用:test.txt中有42亿个无符号整数,从小到大打印其中只出现过一次的数
。限制: 可用内存为1.5GB》
原文链接:http://blog.csdn.net/stpeace/article/details/46673007
先看这样一个问题:test.txt中有42亿个无符号整数,从小到大打印其中只出现过一次的数 。限制: 可用内存为1.5GB.
前面, 我们已经深入讨论了bit-map, 在本文中, 我们来看看2路bit-map, 其实, 它无非是对bit-map的扩展, 用了两个数组而已罢了。 既然已经熟悉了bit-map, 那我就不多啰嗦了, 直接给出代码:
[cpp] view
plaincopy
#include <iostream>
#include <fstream>
using namespace std;
#define BIT_INT 32 // 1个unsigned int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 4294967296 // 2的32次方
unsigned int *a = NULL;
unsigned int *b = NULL;
// 标志数组a还是b(其实,a、b本是指针)
enum
{
arrA,
arrB
};
// 必须用堆
void createArr()
{
a = new unsigned int[1 + N / BIT_INT];
b = new unsigned int[1 + N / BIT_INT];
}
void deleteArr()
{
delete []a;
a = NULL;
delete []b;
b = NULL;
}
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(unsigned int));
memset(b, 0, (1 + N / BIT_INT) * sizeof(unsigned int));
}
// 设置第i位为1
void setOne(unsigned int i, int flag)
{
if(arrA == flag)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
else
{
b[i >> SHIFT] |= (1 << (i & MASK));
}
}
// 设置第i位为1
void setZero(unsigned int i, int flag)
{
if(arrA == flag)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
else
{
b[i >> SHIFT] &= ~(1 << (i & MASK));
}
}
// 检查第i位的值
int getState(unsigned int i, int flag)
{
if(arrA == flag)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
return (b[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
void setStateFromFile()
{
ifstream cin("test.txt"); // 我测试的时候, 文件中的数据为:7 7 9 2 5 2 0 0 1 4 3 2 8
unsigned int n;
while(cin >> n)
{
// 采用2路bitmap, 其中a数组表示高位, b数组表示低位
// ab组合, 00表示出现0次, 01表示出现1次, 10表示出现2次, 11表示出现次数大于2次
int aState = getState(n, arrA);
int bState = getState(n, arrB);
if(0 == aState && 0 == bState) // 当前记录为0次
{
setOne(n, arrB);
}
else if(0 == aState && 1 == bState) // 当前记录为1次
{
setOne(n, arrA);
setZero(n, arrB);
}
else if(1 == aState && 0 == bState) // 当前记录为2次
{
setOne(n, arrB);
}
else // 当前记录大于2次,不做处理
{
NULL;
}
}
}
void printSingleNum()
{
unsigned int i = 0;
unsigned int bits = (1 + N / BIT_INT) * sizeof(unsigned int);
for(i = 0; i < bits; i++)
{
if(0 == getState(i, arrA) && 1 == getState(i, arrB))
{
cout << i << " "; // 结果:1, 3, 4, 5, 8, 9
}
}
cout << endl;
}
int main()
{
createArr();
setAllZero();
setStateFromFile();
printSingleNum();
deleteArr();
return 0;
}
运行一下, 结果与预期相符。 我运行的时候, 电脑卡的厉害啊。大家在玩的时候, 可以把N的值尽量调小一点, 比如N为429.
OK, 2路bit-map的介绍到此为止, 多路bit-map与此同理, 简单。
《bit-map再显身手:test.txt中有42亿个无符号整数, 求文件中有多少不重复的数(重复的数算一个)。限制: 可用内存为600MB.》
原文链接:/article/2222637.html
来看看这样一个问题:test.txt中有42亿个无符号整数, 求文件中有多少不重复的数(重复的数算一个)。限制: 可用内存为600MB.
思路很简单, 还是用bitmap, 无需多啰嗦, 大家可以直接参考我之前的与bit-map有关的博文:
/article/2222597.html
http://blog.csdn.net/stpeace/article/details/46594797
http://blog.csdn.net/stpeace/article/details/46595517
下面, 我给出程序, 经验证, 结果ok, 程序如下:
[cpp] view
plaincopy
#include <iostream>
#include <fstream>
using namespace std;
#define BIT_INT 32 // 1个unsigned int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 4294967296 // 2的32次方
unsigned int *a = NULL;
// 必须用堆
void createArr()
{
a = new unsigned int[1 + N / BIT_INT];
}
void deleteArr()
{
delete []a;
a = NULL;
}
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(unsigned int));
}
// 设置第i位为1
void setOne(unsigned int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1
void setZero(unsigned int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值
int getState(unsigned int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
void setStateFromFile()
{
ifstream cin("test.txt"); // 我测试的时候, 文件中的数据为:7 8 9 2 5 2 6 0 1 4
unsigned int n;
while(cin >> n)
{
setOne(n);
}
}
int getNonDupNum()
{
unsigned int count = 0;
unsigned int i = 0;
unsigned int bits = (1 + N / BIT_INT) * sizeof(unsigned int);
for(i = 0; i < bits; i++)
{
if(1 == getState(i))
{
count++;
}
}
return count;
}
int main()
{
createArr();
setAllZero();
setStateFromFile();
cout << getNonDupNum() << endl; // 9, 也就是说, 文件中有9个不重复的数
deleteArr();
return 0;
}
《bit-map再显身手:test.txt中有42亿个无符号整数, 求不存在于test.txt中的最小无符号整数。限制:
可用内存为600MB.》
原文链接:http://blog.csdn.net/stpeace/article/details/46595517
先看看这个题目:test.txt中有42亿个无符号整数, 求不存在于test.txt中的最小无符号整数. 限制: 可用内存为600MB.
又是大数据。 看到42亿, 有灵感没? 要知道, 2的32次方就是42亿多一点点啊。42亿个无符号整数存在于文件中, 我们可以考虑在内存中用bit-map与之建立二值状态映射。 2的32次方个无符号整数, 需要内存空间为512M, 这个是很容易计算的。
这么大的空间, 要用栈数组肯定不行, 可考虑用堆。 还是我们之前介绍过的bit-map, 用不着多说(别说我不描述思路啊, 代码就体现了思路), 直接给出代码:
[cpp] view
plaincopy
#include <iostream>
#include <fstream>
using namespace std;
#define BIT_INT 32 // 1个unsigned int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 4294967296 // 2的32次方
unsigned int *a = NULL;
// 必须用堆
void createArr()
{
a = new unsigned int[1 + N / BIT_INT];
}
void deleteArr()
{
delete []a;
a = NULL;
}
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(unsigned int));
}
// 设置第i位为1
void setOne(unsigned int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1
void setZero(unsigned int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值
int getState(unsigned int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
void setStateFromFile()
{
ifstream cin("test.txt"); // 我测试的时候, 文件中的数据为:7 8 9 2 5 2 6 0 1 4
unsigned int n;
while(cin >> n)
{
setOne(n);
}
}
void printResult()
{
unsigned int i = 0;
for(i = 0; i < N; i++)
{
if(0 == getState(i))
{
cout << i << endl; // 3
break;
}
}
}
int main()
{
createArr();
setAllZero();
setStateFromFile();
printResult();
deleteArr();
return 0;
}
结果与预期相符。 我们在测试的时候, 用的数据较小, 有兴趣的朋友可以把数据量加大, 进行测试。
OK, 无非又是利用bit-map来节省空间而已, 其实很简单。 本文先介绍到这里了。
《bit-map牛刀小试:数组test[X]的值全部在区间[1, 8000]中, 现要输出test中重复的数。要求:1.
不能改变原数组; 2.时间复杂度为O(X);3.除test外空间不超过1KB》
原文链接:http://blog.csdn.net/stpeace/article/details/46594797
先来看看这个题目:数组test[X]的值全部在区间[1, 8000]中, 现要输出test中重复的数。要求:1. 不能改变原数组; 2.时间复杂度为O(X);3.除test外空间不超过1KB.
好, 我们先给出一个不限空间的解法(为了程序方便, 假设X为10, 实际上可能很大):
[cpp] view
plaincopy
#include <iostream>
using namespace std;
#define X 10
#define N 8000
// 输出重复的数字
void printDup(const int test[], int n)
{
int a
= {0};
int i = 0;
for(i = 0; i < n; i++)
{
a[test[i] - 1]++;
}
for(i = 0; i < N; i++) // 注意, 此处是N而不是n
{
if(a[i] > 1)
{
cout << i + 1 << endl;
}
}
}
int main(void)
{
int test[X] = {1, 2, 3, 4, 2, 5, 6, 7, 5, N};
printDup(test, X);
return 0;
}
结果为:
2
5
显然, 上述程序在空间上超标(且当X<N=8000时, 时间超标), 究其原因是: 让一个int去存一个二值状态, 太浪费空间了, 和不用一个bit来存呢? 所以, 我们自然想到了用bit-map来操作, 如下:
[cpp] view
plaincopy
#include <iostream>
using namespace std;
#define X 10
#define BIT_INT 32 // 1个int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 8000
int a[1 + N / BIT_INT]; // 需要1 + N / BIT_INT 个整数来标志N个事物
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(int));
}
// 设置第i位为1
void setOne(int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1
void setZero(int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值
int getState(int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
// 输出重复的数字
void printDup(const int test[], int n)
{
int i = 0;
for(i = 0; i < n; i++)
{
int state = getState(test[i] - 1);
if(0 == state)
{
setOne(test[i] - 1);
}
else
{
cout << test[i] << endl;
}
}
}
int main(void)
{
setAllZero();
int test[X] = {1, 2, 3, 4, 2, 5, 6, 7, 5, N};
printDup(test, X);
return 0;
}
结果为:
2
5
且满足题目要求。 但是, 我随后发现这个程序还有个问题: 当test数组中某元素出现次数大于2时, 会重复输出, 比如:
[cpp] view
plaincopy
#include <iostream>
using namespace std;
#define X 10
#define BIT_INT 32 // 1个int可以标志32个坑
#define SHIFT 5
#define MASK 0x1f
#define N 8000
int a[1 + N / BIT_INT]; // 需要1 + N / BIT_INT 个整数来标志N个事物
// 将所有位都初始化为0状态
void setAllZero()
{
memset(a, 0, (1 + N / BIT_INT) * sizeof(int));
}
// 设置第i位为1
void setOne(int i)
{
a[i >> SHIFT] |= (1 << (i & MASK));
}
// 设置第i位为1
void setZero(int i)
{
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
// 检查第i位的值
int getState(int i)
{
return (a[i >> SHIFT] & (1 << (i & MASK))) && 1;
}
// 输出重复的数字
void printDup(const int test[], int n)
{
int i = 0;
for(i = 0; i < n; i++)
{
int state = getState(test[i] - 1);
if(0 == state)
{
setOne(test[i] - 1);
}
else
{
cout << test[i] << endl;
}
}
}
int main(void)
{
setAllZero();
int test[X] = {1, 2, 3, 4, 2, 5, 6, 2, 5, N}; // 2出现3次
printDup(test, X);
return 0;
}
结果为:
2
2
5
我想了一下, 暂时没有想到只打印2, 5且符合题意的方法。 如果大家有好的思路, 欢迎赐教

相关文章推荐
- 海量数据处理面试题集锦
- git创建与使用步骤
- VS2010 如何使用宏添加注释
- 将class 编译后文件内容输入到 文本文件中的命令
- JFinal 实现jQuery EasyUI ComboTree数据加载并收起菜单节点
- 去掉android的屏幕上title bar的三种方法
- 为什么eval某个json字符串时要加括号?
- 770 仿射密码【暴力枚举】
- Spring事务的传播行为
- Hibernate各种关联映射关系梳理
- Median of Two Sorted Arrays——算法课上经典的二分和分治算法
- CacheHelper类
- C++primer 阅读笔记-模板与泛型编程(模板参数)
- 利用volley进行http设置请求头、超时及请求参数设置(post)
- 新博客(Hexo)地址:http://leoios.github.io
- CMD 批处理 选择器
- git remote & origin master & 远程分支,git branch
- Java 命名小技巧
- win10小娜打开没有声音该怎么办?
- 【UI初级 连载二】------做一个100秒倒计时的程序,注意考虑,当程序进入后台时的情况。