Hadoop学习3_在HADOOP集群中添加节点和删除节点
2015-09-01 19:53
603 查看
文章一:
无论是在Hadoop集群中添加机器和删除机器,都无需停机,整个服务不中断。本次操作之前,Hadoop的集群情况如下:
HDFS的机器情况如下:
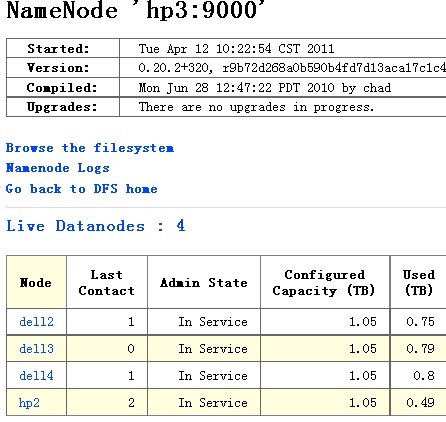
MR的机器情况如下:
添加机器
在集群的Master机器中,修改$HADOOP_HOME/conf/slaves文件,在其中添加需要加入集群的新机器(hp3)的主机名:hp3
hp2
dell1
dell2
dell3
dell4
然后在Master机器中执行如下命令:
$HADOOP_HOME/bin/start-all.sh
这样操作完成之后,新的机器就添加到集群中来了。
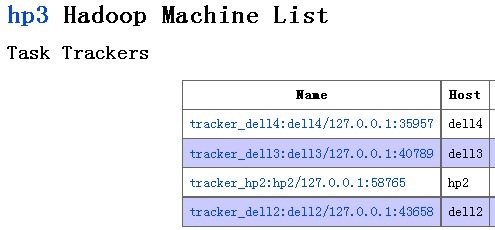
HDFS集群增加了一台新的机器:
MR集群中也新增了一台机器:
删除机器
不安全的方式
由于Hadoop集群自身具备良好的容错性,可以直接关闭相应的机器,从而达到将该机器撤除的目的。但是如果一次性操作3台以上的机器,就有可能造成部分数据丢失,所以不推荐使用这种方式进行操作。
安全的方式
在集群的Master机器中,新建一个文件:$HADOOP_HOME/conf/nn-excluded-list,在这个文件中指定需要删除的机器主机名(hp3):hp3
然后,修改Master机器的配置文件:$HADOOP_HOME/conf/hdfs-site.xml,添加如下内容:
<property>
<name>dfs.hosts.exclude</name>
<value>conf/nn-excluded-list</value>
</property>
最后,在Master机器中执行如下命令:
$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes
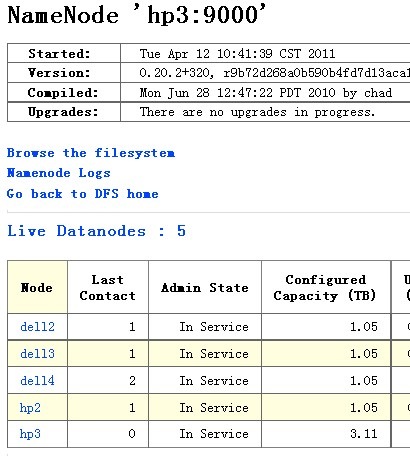
这样操作完成之后,可以在HDFS集群中看到,hp3机器已经处于Decommission In Progress状态:

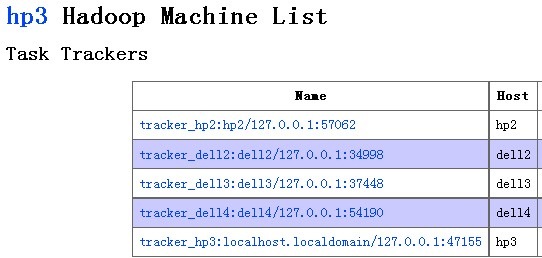
但是MR机器中hp3机器依旧在运行中:
我们需要等待一定的时间,等待hp3中datanode的Decommission操作完成以后,再到hp3机器中关闭所有的Hadoop进程即可。
这样就完成了整个从集群中删除机器的操作。
更多关于Hadoop的文章,可以参考:http://www.cnblogs.com/gpcuster/tag/Hadoop/
原文来自:http://www.cnblogs.com/gpcuster/archive/2011/04/12/2013411.html
文章二:
hadoop要发到每个节点的配置文件,只有core-site.xml mapred-site.xml hdfs-site.xml添加节点
1.修改host和普通的datanode一样。添加namenode的ip
2.修改namenode的配置文件conf/slaves
添加新增节点的ip或host
3.在新节点的机器上,启动服务
[root@slave-004 hadoop]# ./bin/hadoop-daemon.sh start datanode [root@slave-004 hadoop]# ./bin/hadoop-daemon.sh start tasktracker
4.均衡block
[root@slave-004 hadoop]# ./bin/start-balancer.sh
1) 如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低mapred的工作效率
2) 设置平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长
[root@slave-004 hadoop]# ./bin/start-balancer.sh -threshold 5
3) 设置balance的带宽,默认只有1M/s
<property> <name>dfs.balance.bandwidthPerSec</name> <value>1048576</value> <description> Specifies the maximum amount of bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description> </property>
注意:
1. 必须确保slave的firewall已关闭;
2. 确保新的slave的ip已经添加到master及其他slaves的/etc/hosts中,反之也要将master及其他slave的ip添加到新的slave的/etc/hosts中
删除节点
1.集群配置修改conf/hdfs-site.xml文件
<property> <name>dfs.hosts.exclude</name> <value>/data/soft/hadoop/conf/excludes</value> <description>Names a file that contains a list of hosts that are not permitted to connect to the namenode. The full pathname of the file must be specified. If the value is empty, no hosts are excluded.</description> </property>
2.确定要下架的机器
dfs.hosts.exclude定义的文件内容为,每个需要下线的机器,一行一个。这个将阻止他们去连接Namenode。如:
slave-003 slave-004
3.强制重新加载配置
[root@master hadoop]# ./bin/hadoop dfsadmin -refreshNodes
它会在后台进行Block块的移动
4.关闭节点
等待刚刚的操作结束后,需要下架的机器就可以安全的关闭了。
[root@master hadoop]# ./bin/ hadoop dfsadmin -report
可以查看到现在集群上连接的节点
正在执行Decommission,会显示: Decommission Status : Decommission in progress 执行完毕后,会显示: Decommission Status : Decommissioned
5.再次编辑excludes文件
一旦完成了机器下架,它们就可以从excludes文件移除了
登录要下架的机器,会发现DataNode进程没有了,但是TaskTracker依然存在,需要手工处理一下
原文来自:http://www.open-open.com/lib/view/open1349965401900.html

相关文章推荐
- Android基本架构
- Linux下gbk-utf8文件和目录下所有文件转码
- CentOS6.6源码编译升级GCC至4.8.2
- Awk中调用shell命令
- hadoop异常:虚拟机上搭建分布式集群org.apache.hadoop.ipc.Client: Retrying connect to server
- VIM配置笔记(cscope+NERDTree)
- php使用cookie显示用户上次访问网站日期的方法
- linux常用命令(17):whereis命令
- tomcat环境变量配置
- WordPress网站使用301转向实现网站迁移
- 软工之软件维护
- linux常用命令(16):which命令
- Linux mysql 以及sql 语句的使用
- tomcat eclipse问题
- linux利用crontab 自动备份或删除的方法
- OpenCV实现SfM(一):相机模型
- eclipse 部署tomcat中插件下载地址和方法
- Centos6 安装zabbix-server
- Linux安装JDK
- linux常用命令(15):tail命令