Linux内核工程导论——用户空间设备管理
2015-08-28 23:02
441 查看
用户空间设备管理
用户空间所能见到的所有设备都放在/dev目录下(当然,只是一个目录,是可以变化的),文件系统所在的分区被当成一个单独的设备也放在该目录下。以前的2.4版本的曾经出现过devfs,这个思路非常好,在内核态实现对磁盘设备的动态管理。可以做到当用户访问一个设备的设备的时候,devfs驱动才会去加载该设备的驱动。甚至每个节点的设备号都是动态获得的。但是该机制的作者不再维护他的代码,linux成员经过讨论,使用用户态的udev代替内核态的devfs,所以现在的devfs已经废弃了。用户态的udev在设备发现的时候加载设备驱动,动态的在/dev目录下创建节点。/dev只是一个目录,而不是挂载devfs文件系统了。当然,这个udev只是个应用的程序,还可以用别的程序替代,例如busybox就实现了mdev完成同样的工作。
设备变化通知用户端
udevd
系统在启动时会对设备做检测,系统启动后设备的变化也应该能够识别。本质上,启动时发现的硬件也是一种设备的变化。这种设备的变化仅仅是内核知道是没有意义的,因为使用设备的用户是用户空间的程序,内核只是管理者,单管理却不能使用,资源就是无意义的存在。那么内核如何将设备的变动信息通知到用户程序?这个机制叫做uevent。
内核通过向用户空间发送uevent事件来通知用户空间程序设备资源的变化,事件所传递的变化的具体内容是通过uevent事件所附带的参数缓存来实现的。而用户空间对该事件进行响应的程序就叫做udevd(或者叫其他的名字),但是这种内核通知,用户响应的机制就叫做udev。
但是这只是目前的机制。linux是个不断演化的系统,之前为了完成相同的功能还使用过hotplug程序(有设备变动就执行一遍该程序,可重入的多次执行),还有devfs(提前在/dev目录创建了一堆节点文件,无动态性),而udevd是一个后台服务程序,不是像hotplug一样来一个信息执行一个程序副本。udevd这种处理消息的能力免除了可重入问题,加快了用户端响应内核设备变动的效率。
虽然说了udevd是用户端检测内核设备变动。那么其检测来干什么呢?这就是linux的机制所决定的。linux用户端要使用每个设备都要在/dev/目录中引用,除非更上层的封装(如mount),然而这也离不开/dev文件系统中对设备的引用。所以,对用户端应用来说,/dev/目录时他们与内核设备直接打交道的唯一途径。例如drm设备可以直接访问显卡,tty设备可以直接访问串口,sr0可以直接访问cdrom,sda可以直接访问磁盘。内核确认规定了如何使用各个设备,但是使用何种设备需要用户来指定(例如你修改一个文件整个操作都是在内核中驱动的,但是首先你得先把文件所在分区设别mount到你的文件系统中)。
所以,udevd最重要的功能就是创建dev下的设备节点。
但是并不是所有做这个事情的应用都用的udevd,这只是udev协议的一种广泛使用的实现软件,还有一个是busybox使用的mdev,也可以完成相同的功能。
另外,近代的操作系统倾向于把所有的服务程序纳入统一的管理,有的是管理用来在需要的使用启动该程序实体,例如inetd,有的则直接是整合了程序本身进管理程序,例如目前被开始广泛使用的systemd程序。如果你打开你的进程,你会发现在后台运行的可能不是udevd程序了,变成了/lib/systemd/systemd-udevd –daemon 服务。这就是被systemd统一管辖的结果。甚至在initrd中也是直接使用了这种服务,大有一统江湖的趋势。
那么,linux是用何种通信手段与用户端的服务程序通信的呢?答案是netlink。
其他应用程序对热插播事件的捕捉
是不是只有udevd通过监听netlink事件才能得到内核事件的变化?肯定不是。内核在实现的过程中考虑了各种情况,你甚至还可以像以前一样指定hotplug程序。但是内核在实现KObject机制的同时也顺便实现了这种功能,叫做uevent_helper。在用户空间是/sys/kernel/uevent_helper。通过向这个文件写入一个程序路径,linux的uevent就会顺便通知这个程序。
这个目录的存在是需要内核支持的,内核配置中的CONFIG_UEVENT_HELPER=y
CONFIG_UEVENT_HELPER_PATH="" 可以控制该机制。
设备类型
内核中定义的设备类型共有2种:字符类和块类。这些/dev目录下的设备并不一定都对应着具体的硬件(如zero、tty),有的一个硬件可能对应着多个节点(如sda、sda1)。大部分发挥特殊功能的设备都是字符设备,正是由于设备是可以虚拟的,所以诞生了框架设备这一种新的设备子类型。
input设备是一种字符设备,很多输入相关的设备都是使用这个input设备进行管理的。也就是说input虚拟设备是为其他输入设备服务的。
磁盘相关一般是sda、sdb等,这里的s代表是scsi设备。以前还经常出现hd、fd等,fd表示软盘,hd表示IDE硬盘。由于sata和scsi已经很大程度合并,软件上已经可以处理相同的命令,所以对于只关心软件的linux来说sata设备也是sd设备。sr是cdrom,一般也有一个cdrom节点文件。
tty是串口,一般会模拟很多出来,通过ctrl+alt+F1...F7分别调用。但还有一种模拟串口的方式是图形界面的pty。在ubuntu的程序打开一个terminal就是一个pty,p是伪装的意思。
Loop是回环设备,是块设备。其本身不是设备,将一个文件挂载到一个目录,这个文件就被认为是一个虚拟的磁盘,里面是有分区结构的。在设备中就是一个回环设备。
内核数据结构的面向用户组织KObject
linux内核用的一种组织数据的方式是实现一个结构体(或一种数据组织方式),为这个组织方式的每个元素定义了结构体。任何其他的部分想要使用这个数据组织方式只需要包含对应的结构体,就可以把自己安放在数据结构的特定位置。例如list数据结构的实现,还有一个很重要的就是KObject。
KObject也是内核预先设计好的数据结构组织方式,是一个树形的结构的实例。每一个KObject都是这棵树的一个节点,每一个KSet都是这棵树的一颗非叶子节点,里面包含了KSet或者一些KObject。按照定义,同样的,一个KSet也是一个KObject。包含KSet的可以是KSet,还可以是该组织方式定义的最高层的分层数据类型KSubsystem。从树的角度看,KSubsystem与KSet没有区别,但是这个数据组织方式是在树的基础上定义了,对最上层的树做了额外的区别于KSet的定义,就命名为KSubsystem。
操作用户空间设备节点的命令和工具
mknod
磁盘管理
MBR与GPT
见bootloader
LVM
概览
Linux和Windows都经常面对一个问题就是磁盘空间的划分不能有效的适用长时间的使用。动态的调整大小在Windows下有优秀的工具,但是非常费时,并且需要关机重启。这对个人用户来说不算什么,所以可以适用家用。但linux不只是家用,企业通常在有分区扩张需求的时候又不希望重启电脑,并且要较快的完成操作。这时LVM就诞生了。现在已经在发展LVM2。
LVM的主要思想是不以硬件的sda1、sdb2等物理分区为划分分区的手段,而是允许组织多个物理磁盘到一个分区。将很多磁盘组成卷组(volumegroup),然后在卷组上随意划分逻辑卷组(logicalvolumes)。
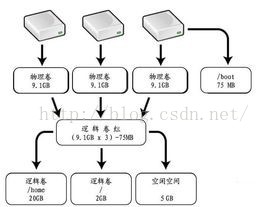
一个卷组叫做VG(Volume Group),物理磁盘叫做PV(PhysicalVolume),划分的逻辑卷组叫做LV(Logical Volume)。在一个PV上不像是以前划分为文件系统,而是划分为相同大小的存储单元叫PE(Physical Extents),默认一个PE的大小是4MB。PE是LVM可以寻址的最小单位。逻辑卷LV也被划分为可被寻址的基本单位,称为LE。在同一个卷组中,LE的大小和PE是相同的,并且一一对应。
和非LVM系统将包含分区信息的元数据保存在位于分区的起始位置的分区表中一样,逻辑卷以及卷组相关的元数据也是保存在位于物理卷起始处的VGDA(卷组描述符区域)中。VGDA包括以下内容:PV描述符、VG描述符、LV描述符、和一些PE描述符。
系统启动LVM时激活VG,并将VGDA加载至内存,来识别LV的实际物理存储位置。当系统进行I/O操作时,就会根据VGDA建立的映射机制来访问实际的物理位置。
LVM并不是取代文件系统,而是文件系统以下的分区手段。在创建完LVM之后,在LV上还要像传统分区一样进行文件系统格式化才能被使用。
优点与缺点
LVM的最大优势是可以快照,这在传统磁盘是不可想象的,只在vmware这种虚拟化机制中容易实现。快照也是同样的采用写时拷贝。通过一个写时拷贝表记录新写入和修改的PE,而在修改时并不修改原有的PE,而是使用新的,如此就可以回溯到快照了。
另一个优势是可伸缩性。可以无需停机就调整分区的大小。这对于RAID系统来说由其有用。
也正是LVM的设计原因导致了其缺点也很明显。就是当一个分区的物理PE不连续时,就会造成极大的性能损耗。
除了LVM之外,还有其他类似的机制,如EVMS、dmraid。但是LVM被广泛采用。
工作方式

这个机制不可能只在用户空间完成,需要内核空间的代码协助,这部分代码是device-mapper(dm_mod模块)。dm_mod模块完成IO请求的转换工作,与内存管理一样本质上是映射。代码位于driver/md。这部分代码是策略与机制分离的生动体现,策略由用户端指定,机制由内核提供。
这个模块建模了3个实体:mappeddevice、映射表和target device。映射表用来记录两个设备的映射。一个是mapped device,是内核向外提供的设备,是逻辑存在的。一个是target device,所有对逻辑设备的操作最后都会转变为对target device的操作,是物理存在的。
我们知道通用块层的核心数据请求是BIO,而BIO不能跨越多个物理设备。因此在映射的情况下,一个BIO会被克隆分割为多个送到各个target device。

相关文章推荐
- Linux socket 初步
- 10 篇对初学者和专家都有用的 Linux 命令教程
- Linux 与 Windows 对UNICODE 的处理方式
- Ubuntu12.04下QQ完美走起啊!走起啊!有木有啊!
- 解決Linux下Android开发真机调试设备不被识别问题
- 运维入门
- 运维提升
- Linux 自检和 SystemTap
- Ubuntu Linux使用体验
- c语言实现hashmap(转载)
- Linux 信号signal处理机制
- linux下mysql添加用户
- Scientific Linux 5.5 图形安装教程
- 基于 Linux 集群环境上 GPFS 的问题诊断
- 谁是桌面王者?Win PK Linux三大镇山之宝
- vivi下重新调整分区
- Linux VS Unix:Linux欲一统天下 Unix不死
- linux下设定环境变量