话务预测(3) ARIMA
2015-08-12 15:36
239 查看
这里问题其实是一个预测问题,但是正如我们前面所讲到的,我们要预测的是未来某一天的话务量,所以本问题是一个关于时间序列的预测问题,但并非典型的时间序列预测问题,因为所要预测的时间点之前的一系列时间序列的值并不是可知的。
这里我们不妨一起来讨论讨论一个在话务预测相关文献中经常出现的典型的时间序列预测方法——ARIMA(Autoregressive Integrated Moving Average model),中文叫差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动)。
相比于HMM(隐马尔科夫模型),ARIMA模型其实在经济金融方面的应用更多,而且是一种纯统计检验的方法,这里借用Box的一句话“All models are wrong, but some are useful.”。ARIMA其实在很多指标建模中还是取得了不错的效果的,说白了现实中的很多时间序列他还是可以解释、预测的很不错的。
例如下面的序列:
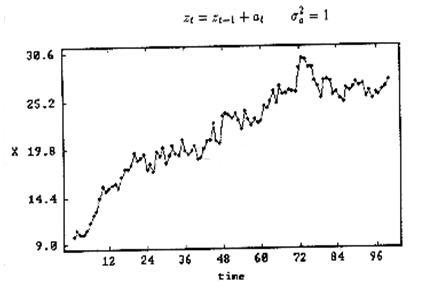
可以看出,均值随时间增长,但是如果我对时间序列做一阶差分(差分是获得平稳时间序列的最常用的方法),也就是说让wi=zi−zi−1,则时间序列变成:
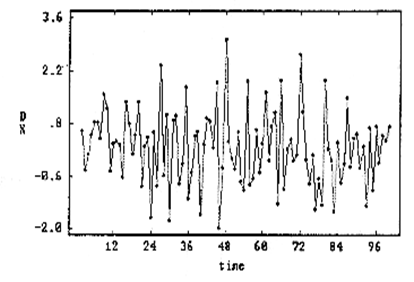
当然,通过ADF检验(Augment Dickey-Fuller test),可以来判断一个过程是否是平稳的。
其实,差分(类似于求导数的思想),是时间序列中最常用的手段,在特征提取中,差分也是最基础的操作,问题往往不是“要不要做差分”,而是“怎样做差分”、“做几阶差分”、“差分以后怎样进一步处理”。
自回归模型(AR,Autoregressive Model)的意思是时间序列值由前面的p个时间序列指标来确定(成为p阶的自回归模型),公式为:

其中at是白噪声,c为常数项,zt表示时间t的指标值,而ϕi表示之前的指标的系数。
移动平均模型(MA,Moving Average Model)认为指标是由一系列的白噪声和其系数组成:

其中at为白噪声,服从分布N(0,σ2),而θ表示震动影响或者记忆函数(shock effect or memory function)。这里是一个q阶的滑动平均模型。
其实到这里,ARIMA的三个参数d,p,q就都出现了,d是差分的阶数,而p,q就是上面的p个q的意思。ARIMA模型无非就是认为时间序列是p阶的自回归和q阶的移动平均模型的和。
然后建模无非就是寻找这样的三个参数。
很多人不明白这两个函数的区别,我这里引用别人说的一段话:
对于一个平稳AR(p)模型,求出滞后k自相关系数p(k)时,实际上得到并不是x(t)与x(t-k)之间单纯的相关关系。
因为x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响,而这k-1个随机变量又都和x(t-k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响。
为了能单纯测度x(t-k)对x(t)的影响,引进偏自相关系数的概念。对于平稳时间序列{x(t)},所谓滞后k偏自相关系数指在给定中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的条件下,或者说,在剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后,x(t-k)对x(t)影响的相关程度。
利用上面两种函数的截尾特性,我们可以分析出模型是AR还是MA还是ARMA,然后用基于迭代的极大似然估计来求解参数的精确值。(具体怎么判断大家可以参考“下面的参考文献2”)这样模型就建立了,利用这个模型,我们可以对时间序列的未来值进行预测了。
接下来,我们看看在序列分析中另一个常用的模型HMM(隐马尔科夫模型)。
参考文献:
ARIMA模型 http://people.duke.edu/~rnau/411arim.htm
时间序列的平稳性和单位根检验http://wenku.baidu.com/view/83d709e0b8f67c1cfad6b841.html?re=view
时间序列预测方法 http://www.360docs.net/doc/info-291bd409b7360b4c2f3f6401.html
这里我们不妨一起来讨论讨论一个在话务预测相关文献中经常出现的典型的时间序列预测方法——ARIMA(Autoregressive Integrated Moving Average model),中文叫差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动)。
相比于HMM(隐马尔科夫模型),ARIMA模型其实在经济金融方面的应用更多,而且是一种纯统计检验的方法,这里借用Box的一句话“All models are wrong, but some are useful.”。ARIMA其实在很多指标建模中还是取得了不错的效果的,说白了现实中的很多时间序列他还是可以解释、预测的很不错的。
ARIMA模型
平稳时间序列(Stationary Time Series),所谓平稳,就是其统计特性(均值、方差、协方差(定间隔两个时间点指标的协方差))不随着时间发生变化。ARIMA处理的时间序列,首先就要求是一个平稳的时间序列。例如下面的序列:
可以看出,均值随时间增长,但是如果我对时间序列做一阶差分(差分是获得平稳时间序列的最常用的方法),也就是说让wi=zi−zi−1,则时间序列变成:
当然,通过ADF检验(Augment Dickey-Fuller test),可以来判断一个过程是否是平稳的。
其实,差分(类似于求导数的思想),是时间序列中最常用的手段,在特征提取中,差分也是最基础的操作,问题往往不是“要不要做差分”,而是“怎样做差分”、“做几阶差分”、“差分以后怎样进一步处理”。
自回归模型(AR,Autoregressive Model)的意思是时间序列值由前面的p个时间序列指标来确定(成为p阶的自回归模型),公式为:
其中at是白噪声,c为常数项,zt表示时间t的指标值,而ϕi表示之前的指标的系数。
移动平均模型(MA,Moving Average Model)认为指标是由一系列的白噪声和其系数组成:
其中at为白噪声,服从分布N(0,σ2),而θ表示震动影响或者记忆函数(shock effect or memory function)。这里是一个q阶的滑动平均模型。
其实到这里,ARIMA的三个参数d,p,q就都出现了,d是差分的阶数,而p,q就是上面的p个q的意思。ARIMA模型无非就是认为时间序列是p阶的自回归和q阶的移动平均模型的和。
然后建模无非就是寻找这样的三个参数。
ARIMA求解
自相关函数和偏自相关函数衡量的是时间序列的指标值和之前的值的相关性,相关概念大家可以去维基一下。很多人不明白这两个函数的区别,我这里引用别人说的一段话:
对于一个平稳AR(p)模型,求出滞后k自相关系数p(k)时,实际上得到并不是x(t)与x(t-k)之间单纯的相关关系。
因为x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响,而这k-1个随机变量又都和x(t-k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响。
为了能单纯测度x(t-k)对x(t)的影响,引进偏自相关系数的概念。对于平稳时间序列{x(t)},所谓滞后k偏自相关系数指在给定中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的条件下,或者说,在剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后,x(t-k)对x(t)影响的相关程度。
利用上面两种函数的截尾特性,我们可以分析出模型是AR还是MA还是ARMA,然后用基于迭代的极大似然估计来求解参数的精确值。(具体怎么判断大家可以参考“下面的参考文献2”)这样模型就建立了,利用这个模型,我们可以对时间序列的未来值进行预测了。
接下来,我们看看在序列分析中另一个常用的模型HMM(隐马尔科夫模型)。
参考文献:
ARIMA模型 http://people.duke.edu/~rnau/411arim.htm
时间序列的平稳性和单位根检验http://wenku.baidu.com/view/83d709e0b8f67c1cfad6b841.html?re=view
时间序列预测方法 http://www.360docs.net/doc/info-291bd409b7360b4c2f3f6401.html

相关文章推荐
- 2010年天灾预测年度报告简表
- 基于神经网络的预测模型
- 2008年11月【51CTO版】软考考前冲刺预测卷
- 独立思考者模型:识别媒体与砖家的谎言
- 大盘分析
- 灰色系统模型GM(1,1)的R语言实现
- 2045的世界?吓人...!!
- 知道得越多,越难改变观点
- 正则表达式---零宽度正预测先行断言 (?=X)
- 卡尔曼滤波算法原理
- h264码流分析
- 宽带离网用户分析(2) 数据预处理和特征抽取
- 玩家流失预测
- 度量,看上去很美
- 傅立叶外推算法的python实现和缺点
- 美元兑人民币汇率对黄金价格的预测
- 各种TCP版本 之 TCP Reno 与 TCP Vegas 共存
- 关于matlab中movavg的用法
- TF-IDF及其算法
- 2017容器发展趋势预测:更快速的采纳和创新