go-内存分配
2015-08-11 21:40
495 查看
对go语言内存分配过程整理。原文为设计和实现。
Go的内存分配器主要也是解决小对象的分配管理和多线程的内存分配问题。内存分配器以32k作为对象大小的定夺标准,小于等于32k的内存对象一律视为小对象,而大于32k的对象就是大对象了。
go语言内存分配模型如图:

Cache、Central、Heap是三个核心组件。
go语言中,一个线程有一个cache对应,这个cache用来存放小对象。
所有线程共享Central和Heap。
这样一来,从cache里查询、获取空闲内存的时候就不需要加锁了,每次小对象的申请直接访问本线程对应的cache即可。只要是分配小对象就先到cache中查询一下,有空闲的内存就直接返回使用,不用向操作系统申请内存。其实绝大多数的内存申请都是小于32k的,属于小对象,因此这样的内存分配全部走本地cache,不用向操作系统申请显然是非常高效的。
有cache,必然就有cache不命中的情况,内存分配器在面对
总结一下:cache -> Central -> Heap -> MM .
小对象的内存分配是通过一级一级的缓存来实现的,目的就是为了提升内存分配释放的速度以及避免内存碎片等问题。大于32k的大对象直接向
详细过程如下,请耐心阅读下文。
内存布局结构图

我把整个核心代码的逻辑给抽象绘制出了这个内存布局图,它基本展示了Go语言内存分配器的整体结构以及部分细节(这结构图应该同样适用于tcmalloc)。从此结构图来看,内存分配器还是有一点小复杂的,但根据具体的逻辑层次可以拆成三个大模块——cache,central,heap,然后一个一个的模块分析下去,逻辑就显得特别清晰明了了。位于结构图最下边的
在分析内存分配器这部分源码的时候,首先需要明确的是所有内存分配的入口,有了入口就可以从这里作为起点一条线的看下去,不会有太大的障碍。这个入口就是malloc.goc源文件中的
在真正进入内存分配过程之前,还需要了解一下整个内存分配器是如何创建的以及初始化成什么样子。完成内存分配器创建初始化的函数是
初始化过程主要是在折腾mcache和mheap两个部分,而mcentral在实际逻辑中是属于mheap的子模块,所以初始化过程就没明确的体现出来,这和我绘制的结构图由两大块构造相对应。heap是所有底层线程共享的;而cache是每个线程都分别拥有一个,是独享的。在64位平台,heap从操作系统申请的内存地址保留区只有136G,其中bitmap需要8G空间,因此真正可申请的内存就是128G。当然128G在绝大多数情况都是够用的,但我所知道的还是有个别特殊应用的单机内存是超过128G的。
下面按小内存分配的处理路径,从cache到central到heap的过程详细介绍一下。
cache的实现主要在mcache.c源文件中,结构MCache定义在malloc.h中,从cache中申请内存的函数原型:
参数
runtime·MCache_Alloc分配内存的过程是,根据参数sizeclass从list数组中取出一个内存块链表,如果这个链表不为空,就直接把第一个节点返回即可;如果链表是空,说明cache中没有满足此类大小的缓存内存,这个时候就调用
cache上的内存分配逻辑很简单,就是cache取不到就到central中去取。除了内存的分配外,cache上还存在很多的状态计数器,主要是用来统计内存的分配情况,比如:分配了多少内存,缓存了多少内存等等。这些状态计数器非常重要,可以用来监控我们程序的内存管理情况以及profile等,runtime包里的
cache的释放条件主要有两个,一是当某个内存块链表过长(>=256)时,就会截取此链表的一部分节点,返还给central;二是整个cache缓存的内存过大(>=1M),同样将每个链表返还一部分节点给central。
cache层在进行内存分配和释放操作的时候,是没有进行加锁的,也不需要加锁,因为cache是每个线程独享的。所以cache层的主要目的就是提高小内存的频繁分配释放速度。
malloc.h源文件里MHeap结构关于central的定义如下:
结合结构图可以看出,在heap结构里,使用了一个0到n的数组来存储了一批central,并不是只有一个central对象。从上面结构定义可以知道这个数组长度位61个元素,也就是说heap里其实是维护了61个central,这61个central对应了cache中的list数组,也就是每一个sizeclass就有一个central。所以,在cache中申请内存时,如果在某个sizeclass的内存链表上找不到空闲内存,那么cache就会向对应的sizeclass的central获取一批内存块。注意,这里central数组的定义里面使用填充字节,这是因为多线程会并发访问不同central避免false
sharing。
central的实现主要在mcentral.c源文件,核心结构MCentral定义在malloc.h中,结构如下:
MCentral结构中的nonempty和empty字段是比较重要的,重点解释一下这两个字段。这两字段都是MSpan类型,大胆的猜测一下这两个字段将分别挂一个span节点构造的双向链表(MSpan在上一篇文章详细介绍了),只是这个双向链表的头节点不作使用罢了。
我们知道cache在内存不足的时候,会通过
从central中获取一批内存块交给cache的过程,看上去也不怎么复杂,只是这个过程是需要加锁的。这里重点要关注第一部分填充nonempty的情况,也就是central没有空闲内存,需要向heap申请。这里调用的是
central中的内存分配过程搞定了,看一下大概的释放过程。cache层在释放内存的时候,是将一批小内存块返还给central,central在收到这些归还的内存块的时候,会把每个内存块分别还给对应的span。在把内存块还给span后,如果span先前是被用完了内存,待在empty链表中,那么此刻就需要将它移动到nonempty中,表示又有可用内存了。在归还小内存块给span后,如果span中的所有page内存都收回来了,也就是没有任何内存被使用了,此刻就会将这个span整体归还给heap了。
在central这一层,内存的管理粒度基本就是span了,所以span是非常重要的一个工具组件。
Heap
总算来到了最大的一层heap,这是离Go程序最远的一层,离操作系统最近的一层,这一层主要就是从操作系统申请内存交给central等。heap的核心结构MHeap定义在malloc.h中,一定要细看。不管是通过central从heap获取内存,还是大内存情况跳过了cache和central直接向heap要内存,都是调用如下函数来请求内存的。
函数原型可以看出,向heap要内存,不是以字节为单位,而是要多少个page。参数npage就是需要的page数量,sizeclass等于0,就是绕过cache和central的直接找heap的大内存分配;central调用此函数时,sizecalss一定是1到60的一个值。从heap中申请到的所有page肯定都是连续的,并且是通过span来管理的,所以返回值是一个span,不是page数组等。
真正在heap中执行内存分配逻辑的是位于mheap.c中的
从heap中要内存,首先是根据请求的page数量到free或者large中获取一个最合适的span。当然,如果在large链表中都找不到合适的span,就只能调用MHeap_Grow函数从操作系统申请内存,然后填充Heap,再试图分配。拿到的span所含page数大于了请求的page数的的时候,并不会将整个span返回使用,而是对这个span进行拆分,拆为两个span,将剩余span重新放回到free或者large链表中去。因为heap面对的始终是page,如果全部返回使用,可能就会太浪费内存了,所以这里只返回请求的page数是有必要的。
从heap中请求出去的span,在遇到内存释放退还给heap的时候,主要也是将span放入到free或者large链表中。
heap比骄复杂的不是分配释放内存,而是需要维护很多的元数据,比如结构图还没有介绍的map域,这个map维护的就是page到span的映射,也就是任何一块内存在算出page后,就可以知道这块内存属于哪个span了,这样才能做到正确的内存回收。除了map以外,还有bitmap等结构,用来标记内存,为gc服务。
后面对垃圾收集器(gc)的分析时,还会回头来看heap。本文内容已经够多了,但确实还有很多的细节没有介绍到,比如:heap是如何从操作系统拿内存、heap中存在一个2分钟定时强制gc的goroutine等等。
最后,关于go如何在内存中分配堆栈,我看了一篇文章,精力所限,我就不翻译了,简单贴出这部分,想看的,请看原文。
In the previous section I discussed how goroutines reduce the overhead of managing many, sometimes hundreds of thousands of concurrent threads of execution. There is another side to the goroutine story, and that is stack management.
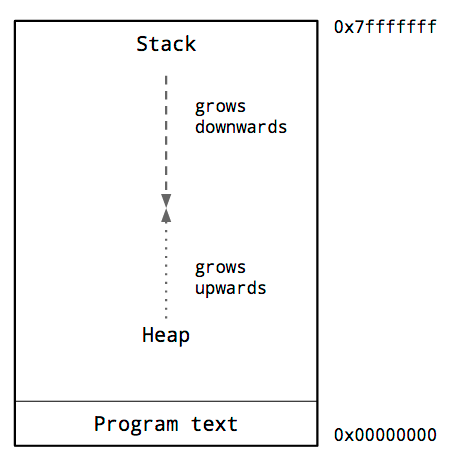
This
is a diagram of the typical memory layout of a process. The key thing we are interested in is the locations of the heap and the stack.
Inside the address space of a process, traditionally the heap is at the bottom of memory, just above the program code and grows upwards.
The stack is located at the top of the virtual address space, and grows downwards.
Because the heap and stack overwriting each other would be catastrophic, the operating system arranges an area of inaccessible memory between the stack and the heap.
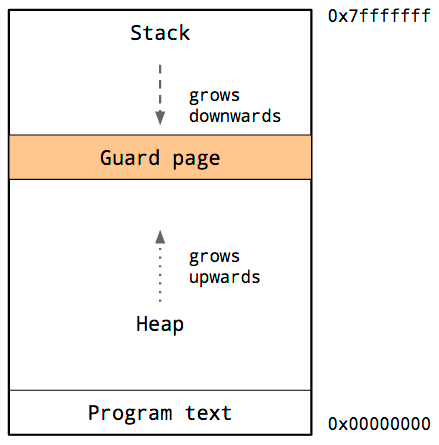
This is called a guard page, and effectively limits the stack size of a process, usually in the order of several megabytes.
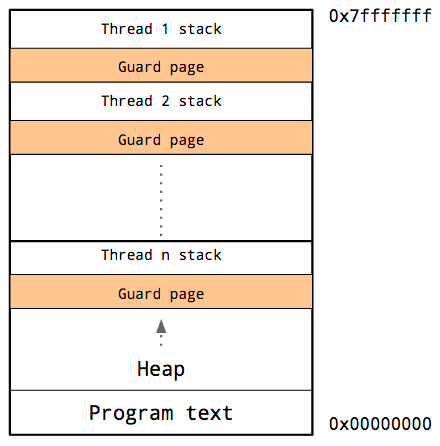
Threads
share the same address space, so for each thread, it must have its own stack and its own guard page.
Because it is hard to predict the stack requirements of a particular thread, a large amount of memory must be reserved for each thread’s stack. The hope is that this will be more than needed and the guard page will never be hit.
The downside is that as the number of threads in your program increases, the amount of available address space is reduced.
The early process model allowed the programmer to view the heap and the stack as large enough to not be a concern. The downside was a complicated and expensive subprocess model.
Threads improved the situation a bit, but require the programmer to guess the most appropriate stack size; too small, your program will abort, too large, you run out of virtual
address space.
We’ve seen that the Go runtime schedules a large number of goroutines onto a small number of threads, but what about the stack requirements of those goroutines ?
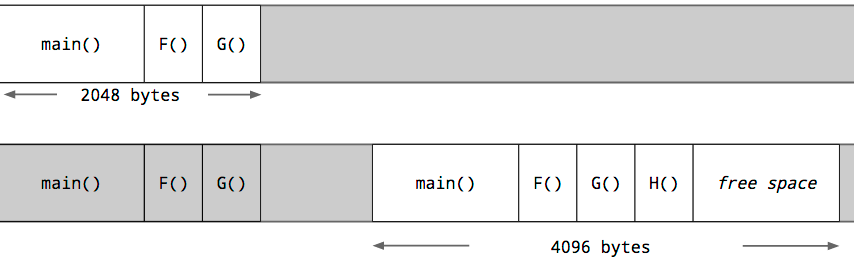
Each
goroutine starts with an small stack, allocated from the heap. The size has fluctuated over time, but in Go 1.5 each goroutine starts with a 2k allocation.
Instead of using guard pages, the Go compiler inserts a check as part of every function call to test if there is sufficient stack for the function to run. If there is sufficient stack space, the function runs as normal.
If there is insufficient space, the runtime will allocate a larger stack segment on the heap, copy the contents of the current stack to the new segment, free the old segment, and the function call is restarted.
Because of this check, a goroutine’s initial stack can be made much smaller, which in turn permits Go programmers to treat goroutines as cheap resources. Goroutine stacks can also shrink if a sufficient portion remains unused. This is handled during garbage
collection.
Go的内存分配器主要也是解决小对象的分配管理和多线程的内存分配问题。内存分配器以32k作为对象大小的定夺标准,小于等于32k的内存对象一律视为小对象,而大于32k的对象就是大对象了。
go语言内存分配模型如图:
Cache、Central、Heap是三个核心组件。
go语言中,一个线程有一个cache对应,这个cache用来存放小对象。
所有线程共享Central和Heap。
这样一来,从cache里查询、获取空闲内存的时候就不需要加锁了,每次小对象的申请直接访问本线程对应的cache即可。只要是分配小对象就先到cache中查询一下,有空闲的内存就直接返回使用,不用向操作系统申请内存。其实绝大多数的内存申请都是小于32k的,属于小对象,因此这样的内存分配全部走本地cache,不用向操作系统申请显然是非常高效的。
有cache,必然就有cache不命中的情况,内存分配器在面对
Cache查找不到空闲内存的时候,就会试图从
Central中申请一批小对象内存到本地缓存住,这里的Central是所有线程共享的一个组件,不是独占的,因此需要加锁操作。Central组件其实也是一个缓存,但它缓存的不是小对象内存块,而是一组一组的内存page(一个page占4k大小)。如果Central中没有缓存的空闲内存page的话,就从
Heap中申请内存来填充Central。当然对Heap的操作也是需要加锁,所有线程共享一个Heap。Heap中没有缓存的内存,当然就直接从操作系统拿取内存了。
总结一下:cache -> Central -> Heap -> MM .
小对象的内存分配是通过一级一级的缓存来实现的,目的就是为了提升内存分配释放的速度以及避免内存碎片等问题。大于32k的大对象直接向
Heap申请。
详细过程如下,请耐心阅读下文。
内存布局结构图
我把整个核心代码的逻辑给抽象绘制出了这个内存布局图,它基本展示了Go语言内存分配器的整体结构以及部分细节(这结构图应该同样适用于tcmalloc)。从此结构图来看,内存分配器还是有一点小复杂的,但根据具体的逻辑层次可以拆成三个大模块——cache,central,heap,然后一个一个的模块分析下去,逻辑就显得特别清晰明了了。位于结构图最下边的
Cache就是cache模块部分;central模块对应深蓝色部分的
MCentral,central模块的逻辑结构很简单,所以结构图就没有详细的绘制了;
Heap是结构图中的核心结构,对应heap模块,也可以看出来central是直接被Heap管理起来的,属于Heap的子模块。
在分析内存分配器这部分源码的时候,首先需要明确的是所有内存分配的入口,有了入口就可以从这里作为起点一条线的看下去,不会有太大的障碍。这个入口就是malloc.goc源文件中的
runtime·mallocgc函数,这个入口函数的主要工作就是分配内存以及触发gc(本文将只介绍内存分配),在进入真正的分配内存之前,此入口函数还会判断请求的是小内存分配还是大内存分配(32k作为分界线);小内存分配将调用
runtime·MCache_Alloc函数从Cache获取,而大内存分配调用
runtime·MHeap_Alloc直接从Heap获取。入口函数过后,就会真正的进入到具体的内存分配过程中去了。
在真正进入内存分配过程之前,还需要了解一下整个内存分配器是如何创建的以及初始化成什么样子。完成内存分配器创建初始化的函数是
runtime·mallocinit,看一下简化的源码:
void
runtime·mallocinit(void)
{
// 创建mheap对象,这个是直接从操作系统分配内存。heap是全局的,所有线程共享,一个Go进程里只有一个heap。
if((runtime·mheap = runtime·SysAlloc(sizeof(*runtime·mheap))) == nil)
runtime·throw("runtime: cannot allocate heap metadata");
// 64位平台,申请一大块内存地址保留区,后续所有page的申请都会从这个地址区里分配。这个区就是结构图中的arena。
if(sizeof(void*) == 8 && (limit == 0 || limit > (1<<30))) {
arena_size = MaxMem;
bitmap_size = arena_size / (sizeof(void*)*8/4);
p = runtime·SysReserve((void*)(0x00c0ULL<<32), bitmap_size + arena_size);
}
// 初始化好heap的arena以及bitmap。
runtime·mheap->bitmap = p;
runtime·mheap->arena_start = p + bitmap_size;
runtime·mheap->arena_used = runtime·mheap->arena_start;
runtime·mheap->arena_end = runtime·mheap->arena_start + arena_size;
// 初始化heap的其他内部结构,如:spanalloc、cacachealloc都FixAlloc的初始化,free、large字段都是挂载维护span的双向循环链表。
runtime·MHeap_Init(runtime·mheap, runtime·SysAlloc);
// 从heap的cachealloc从分配MCache,挂在一个线程上。
m->mcache = runtime·allocmcache();
}初始化过程主要是在折腾mcache和mheap两个部分,而mcentral在实际逻辑中是属于mheap的子模块,所以初始化过程就没明确的体现出来,这和我绘制的结构图由两大块构造相对应。heap是所有底层线程共享的;而cache是每个线程都分别拥有一个,是独享的。在64位平台,heap从操作系统申请的内存地址保留区只有136G,其中bitmap需要8G空间,因此真正可申请的内存就是128G。当然128G在绝大多数情况都是够用的,但我所知道的还是有个别特殊应用的单机内存是超过128G的。
下面按小内存分配的处理路径,从cache到central到heap的过程详细介绍一下。
Cache
cache的实现主要在mcache.c源文件中,结构MCache定义在malloc.h中,从cache中申请内存的函数原型:void *runtime·MCache_Alloc(MCache *c, int32 sizeclass, uintptr size, int32 zeroed)
参数
size是需要申请的内存大小,需要知道的是这个size并不一定是我们申请内存的时候指定的大小,一般来说它会稍大于指定的大小。从结构图上可以清晰看到cache有一个0到n的list数组,list数组的每个单元挂载的是一个链表,链表的每个节点就是一块可用的内存,同一链表中的所有节点内存块都是大小相等的;但是不同链表的内存大小是不等的,也就是说list数组的一个单元存储的是一类固定大小的内存块,不同单元里存储的内存块大小是不等的。这就说明cache缓存的是不同类大小的内存对象,当然想申请的内存大小最接近于哪类缓存内存块时,就分配哪类内存块。list数组的0到n下标就是不同的sizeclass,n是一个固定值等于60,所以cache能够提供60类(0<sizeclass<61)不同大小的内存块。这60类大小是如何划分的,可以查看msize.c源文件。
runtime·MCache_Alloc分配内存的过程是,根据参数sizeclass从list数组中取出一个内存块链表,如果这个链表不为空,就直接把第一个节点返回即可;如果链表是空,说明cache中没有满足此类大小的缓存内存,这个时候就调用
runtime·MCentral_AllocList从central中获取 **一批** 此类大小的内存块,再把第一个节点返回使用,其他剩余的内存块挂到这个链表上,为下一次分配做好缓存。
cache上的内存分配逻辑很简单,就是cache取不到就到central中去取。除了内存的分配外,cache上还存在很多的状态计数器,主要是用来统计内存的分配情况,比如:分配了多少内存,缓存了多少内存等等。这些状态计数器非常重要,可以用来监控我们程序的内存管理情况以及profile等,runtime包里的
MemStats类的数据就是来自这些底层的计数器。
cache的释放条件主要有两个,一是当某个内存块链表过长(>=256)时,就会截取此链表的一部分节点,返还给central;二是整个cache缓存的内存过大(>=1M),同样将每个链表返还一部分节点给central。
cache层在进行内存分配和释放操作的时候,是没有进行加锁的,也不需要加锁,因为cache是每个线程独享的。所以cache层的主要目的就是提高小内存的频繁分配释放速度。
Central
malloc.h源文件里MHeap结构关于central的定义如下:struct MHeap
{
。。。
struct {
MCentral;
byte pad[CacheLineSize];
} central[NumSizeClasses];
。。。
}结合结构图可以看出,在heap结构里,使用了一个0到n的数组来存储了一批central,并不是只有一个central对象。从上面结构定义可以知道这个数组长度位61个元素,也就是说heap里其实是维护了61个central,这61个central对应了cache中的list数组,也就是每一个sizeclass就有一个central。所以,在cache中申请内存时,如果在某个sizeclass的内存链表上找不到空闲内存,那么cache就会向对应的sizeclass的central获取一批内存块。注意,这里central数组的定义里面使用填充字节,这是因为多线程会并发访问不同central避免false
sharing。
central的实现主要在mcentral.c源文件,核心结构MCentral定义在malloc.h中,结构如下:
struct MCentral
{
Lock;
int32 sizeclass;
MSpan nonempty;
MSpan empty;
int32 nfree;
};MCentral结构中的nonempty和empty字段是比较重要的,重点解释一下这两个字段。这两字段都是MSpan类型,大胆的猜测一下这两个字段将分别挂一个span节点构造的双向链表(MSpan在上一篇文章详细介绍了),只是这个双向链表的头节点不作使用罢了。
nonempty字面意思是非空,表示这个链表上存储的span节点都是非空状态,也就是说这些span节点都有空闲的内存;
empty表示此链表存储的span都是空的,它们都没有空闲可用的内存了。其实一开始empty链表就是空的,是当nonempty上的的一个span节点被用完后,就会将span移到empty链表中。
我们知道cache在内存不足的时候,会通过
runtime·MCentral_AllocList从central获取一批内存块,central其实也只有cache一个上游用户,看一下此函数的简化逻辑:
int32
runtime·MCentral_AllocList(MCentral *c, int32 n, MLink **pfirst)
{
runtime·lock(c);
// 第一部分:判断nonempty是否为空,如果是空的话,就需要从heap中获取span来填充nonempty链表了。
// Replenish central list if empty.
if(runtime·MSpanList_IsEmpty(&c->nonempty)) {
if(!MCentral_Grow(c)) {
。。。。。。。
}
}
// 第二部分:从nonempty链表上取一个span节点,然后从span的freelist里获取足够的内存块。这个span内存不足时,就有多少拿多少了。
s = c->nonempty.next;
cap = (s->npages << PageShift) / s->elemsize;
avail = cap - s->ref;
if(avail < n)
n = avail;
// First one is guaranteed to work, because we just grew the list.
first = s->freelist;
last = first;
for(i=1; i<n; i++) {
last = last->next;
}
s->freelist = last->next;
last->next = nil;
s->ref += n;
c->nfree -= n;
// 第三部分:如果上面的span内存被取完了,就将它移到empty链表中去。
if(n == avail) {
runtime·MSpanList_Remove(s);
runtime·MSpanList_Insert(&c->empty, s);
}
runtime·unlock(c);
// 第四部分:最后将取得的内存块链通过参数pfirst返回。
*pfirst = first;
return n;
}从central中获取一批内存块交给cache的过程,看上去也不怎么复杂,只是这个过程是需要加锁的。这里重点要关注第一部分填充nonempty的情况,也就是central没有空闲内存,需要向heap申请。这里调用的是
MCentral_Grow函数。MCentral_Grow函数的主要工作是,首先调用runtime·MHeap_Alloc函数向heap申请一个span;然后将span里的连续page给切分成central对应的sizeclass的小内存块,并将这些小内存串成链表挂在span的freelist上;最后将span放入到nonempty链表中。central在无空闲内存的时候,向heap只要了一个span,不是多个;申请的span含多少page是根据central对应的sizeclass来确定。
central中的内存分配过程搞定了,看一下大概的释放过程。cache层在释放内存的时候,是将一批小内存块返还给central,central在收到这些归还的内存块的时候,会把每个内存块分别还给对应的span。在把内存块还给span后,如果span先前是被用完了内存,待在empty链表中,那么此刻就需要将它移动到nonempty中,表示又有可用内存了。在归还小内存块给span后,如果span中的所有page内存都收回来了,也就是没有任何内存被使用了,此刻就会将这个span整体归还给heap了。
在central这一层,内存的管理粒度基本就是span了,所以span是非常重要的一个工具组件。
Heap
总算来到了最大的一层heap,这是离Go程序最远的一层,离操作系统最近的一层,这一层主要就是从操作系统申请内存交给central等。heap的核心结构MHeap定义在malloc.h中,一定要细看。不管是通过central从heap获取内存,还是大内存情况跳过了cache和central直接向heap要内存,都是调用如下函数来请求内存的。
MSpan* runtime·MHeap_Alloc(MHeap *h, uintptr npage, int32 sizeclass, int32 acct, int32 zeroed)
函数原型可以看出,向heap要内存,不是以字节为单位,而是要多少个page。参数npage就是需要的page数量,sizeclass等于0,就是绕过cache和central的直接找heap的大内存分配;central调用此函数时,sizecalss一定是1到60的一个值。从heap中申请到的所有page肯定都是连续的,并且是通过span来管理的,所以返回值是一个span,不是page数组等。
真正在heap中执行内存分配逻辑的是位于mheap.c中的
MHeap_AllocLocked函数。分析此函数的逻辑前,先看一下结构图中heap的free和large两个域。
free是一个256个单元的数组,每个单元上存储的都是一个span链表;但是不同的单元span含page的个数也是不同的,span含page的个数等于此span所在单元的下标,比如:free[5]中的span都含有5个page。如果一个span的page数超过了255,那这个span就会被放到
large链表中。
从heap中要内存,首先是根据请求的page数量到free或者large中获取一个最合适的span。当然,如果在large链表中都找不到合适的span,就只能调用MHeap_Grow函数从操作系统申请内存,然后填充Heap,再试图分配。拿到的span所含page数大于了请求的page数的的时候,并不会将整个span返回使用,而是对这个span进行拆分,拆为两个span,将剩余span重新放回到free或者large链表中去。因为heap面对的始终是page,如果全部返回使用,可能就会太浪费内存了,所以这里只返回请求的page数是有必要的。
从heap中请求出去的span,在遇到内存释放退还给heap的时候,主要也是将span放入到free或者large链表中。
heap比骄复杂的不是分配释放内存,而是需要维护很多的元数据,比如结构图还没有介绍的map域,这个map维护的就是page到span的映射,也就是任何一块内存在算出page后,就可以知道这块内存属于哪个span了,这样才能做到正确的内存回收。除了map以外,还有bitmap等结构,用来标记内存,为gc服务。
后面对垃圾收集器(gc)的分析时,还会回头来看heap。本文内容已经够多了,但确实还有很多的细节没有介绍到,比如:heap是如何从操作系统拿内存、heap中存在一个2分钟定时强制gc的goroutine等等。
最后,关于go如何在内存中分配堆栈,我看了一篇文章,精力所限,我就不翻译了,简单贴出这部分,想看的,请看原文。
Stack management
In the previous section I discussed how goroutines reduce the overhead of managing many, sometimes hundreds of thousands of concurrent threads of execution. There is another side to the goroutine story, and that is stack management.
Process address space
This
is a diagram of the typical memory layout of a process. The key thing we are interested in is the locations of the heap and the stack.
Inside the address space of a process, traditionally the heap is at the bottom of memory, just above the program code and grows upwards.
The stack is located at the top of the virtual address space, and grows downwards.
Because the heap and stack overwriting each other would be catastrophic, the operating system arranges an area of inaccessible memory between the stack and the heap.
This is called a guard page, and effectively limits the stack size of a process, usually in the order of several megabytes.
Thread stacks
Threads
share the same address space, so for each thread, it must have its own stack and its own guard page.
Because it is hard to predict the stack requirements of a particular thread, a large amount of memory must be reserved for each thread’s stack. The hope is that this will be more than needed and the guard page will never be hit.
The downside is that as the number of threads in your program increases, the amount of available address space is reduced.
Goroutine stack management
The early process model allowed the programmer to view the heap and the stack as large enough to not be a concern. The downside was a complicated and expensive subprocess model.Threads improved the situation a bit, but require the programmer to guess the most appropriate stack size; too small, your program will abort, too large, you run out of virtual
address space.
We’ve seen that the Go runtime schedules a large number of goroutines onto a small number of threads, but what about the stack requirements of those goroutines ?
Goroutine stack growth
Each
goroutine starts with an small stack, allocated from the heap. The size has fluctuated over time, but in Go 1.5 each goroutine starts with a 2k allocation.
Instead of using guard pages, the Go compiler inserts a check as part of every function call to test if there is sufficient stack for the function to run. If there is sufficient stack space, the function runs as normal.
If there is insufficient space, the runtime will allocate a larger stack segment on the heap, copy the contents of the current stack to the new segment, free the old segment, and the function call is restarted.
Because of this check, a goroutine’s initial stack can be made much smaller, which in turn permits Go programmers to treat goroutines as cheap resources. Goroutine stacks can also shrink if a sufficient portion remains unused. This is handled during garbage
collection.

相关文章推荐
- How To Create a Significant Goal ?
- go-内存分配器
- hdu 3635 Dragon Balls (并查集,路径压缩应用)
- hdu 3635 Dragon Balls (并查集,路径压缩应用)
- Hexagon的程序执行顺序(一)
- Singapore National Day (SG50 Golden Jubilee)
- GoLang入门5-调试我们自己写的包mymath
- GoLang入门4-编译应用mymath测试
- GoLang入门3-应用目录结构
- GoLang入门1-安装-配置
- go- 特点
- DjangoWeb: 快速搭建Blog
- django安装tinymce
- Go开发工具
- Installing LiteIDE(Go 语言开发工具)
- Gonet2 游戏服务器框架解析之Agent(2)
- MAC OS X 系统设置PAC文件代理教程 又可以访问google了。
- UVA 11292 The Dragon of Loowater
- django orm排序
- CodeForces 5A - Chat Servers Outgoing Traffic