《机器学习系统设计》之k-近邻分类算法
2015-08-10 20:14
661 查看
前言:
本系列是在作者学习《机器学习系统设计》([美] WilliRichert)过程中的思考与实践,全书通过Python从数据处理,到特征工程,再到模型选择,把机器学习解决问题的过程一一呈现。书中设计的源代码和数据集已上传到我的资源:http://download.csdn.net/detail/solomon1558/8971649第2章通过在真实的Seeds数据集构建一个k-近邻分类器,从而达到一个较好的分类效果。本章主要涉及数据可视化分析、特征和特征工程、数据归一化、交叉验证等知识内容。
1. 算法概述
k-近邻算法(kNN)的工作原理是:存在一个样本数据集合(训练集),并且样本集中每个数据都存在标签。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较(计算欧氏距离),然后算法提取样本集中特征最相似的前k个数据(k-近邻),通过投票的方式来选择标签。简单来说,k-近邻算法采用测量不同特征之间的距离方法进行分类。其优缺点如下:
优点:算法简单、精度较高、对异常值不敏感、无数据输入假定。
缺点:对每个数据集的每个数据特征都需要计算距离值,计算复杂度高、空间复杂度高;
单纯的距离计算忽略了数据本身可以带有和结果标签的强烈的关系,kNN无法给出数据的内在含义。
2. 分析数据
现有一个关于小麦种子的测量数据集Seeds,它包含7个特征数据:面积(A)、周长(P)、紧密度(C = 4πA/P^2)、谷粒的长度、谷粒的宽度、偏度系数、谷粒的槽长度。
这些种子一共分为三个类别,属于小麦的三个不同品种:Canadian、Kama和Rosa。
#coding=utf-8
from matplotlib import pyplot as plt
from load import load_dataset
feature_names = [
'area',
'perimeter',
'compactness',
'length of kernel',
'width of kernel',
'asymmetry coefficien',
'length of kernel groove',
]
lable_name = [
'Kama',
'Rosa',
'Canadian'
]
features, lables = load_dataset('seeds')
print lables
paris = [(0,1),(0,2),(0,3),(0,4),(0,5),(0,6),(1,2),(1,3),(1,4),(1,5),(1,6),(2,3),(2,4),(2,5),(2,6),(3,4),(3,5),(3,6),(4,5),(4,6),(5,6)]
for i, (p0, p1) in enumerate(paris):
plt.subplot(3, 7, i+1)
for t, marker, c in zip(range(3), ">ox", "rgb"):
plt.scatter(features[lables == lable_name[t], p0], features[lables == lable_name[t], p1], marker=marker, c=c)
plt.xlabel(feature_names[p0])
plt.ylabel(feature_names[p1])
plt.xticks([])
plt.yticks([])
plt.show()
7种特征一共有21种顺序无关的排列组合。其中可以观察到area-perimeter、area-length of kernel、area-width of kernel、perimeter-length of kernel等图像呈现正相关性;area-perimeter、area-lengthof kernel groove、length of kernel-length of kernel groove等图像的三类种子可区分性较好。
3. 数据归一化
观察数据集,原始数据包含面积、长度、无量纲的量都混合在了一起。比如第1个面积特征A(量纲为平方米)比第3个紧密度特征C(无量纲)高了一个数量级。这些量纲不同、数量级不同的特征数据会影响其对分类决策的贡献度。为了揭示数据归一化的必要性,下面从判别边界和交叉验证的准确度两个维度讨论。为方面可视化,这里仅考虑面积特征Area和紧密度特征Compactness两个相差较大的特征。对比图如下:
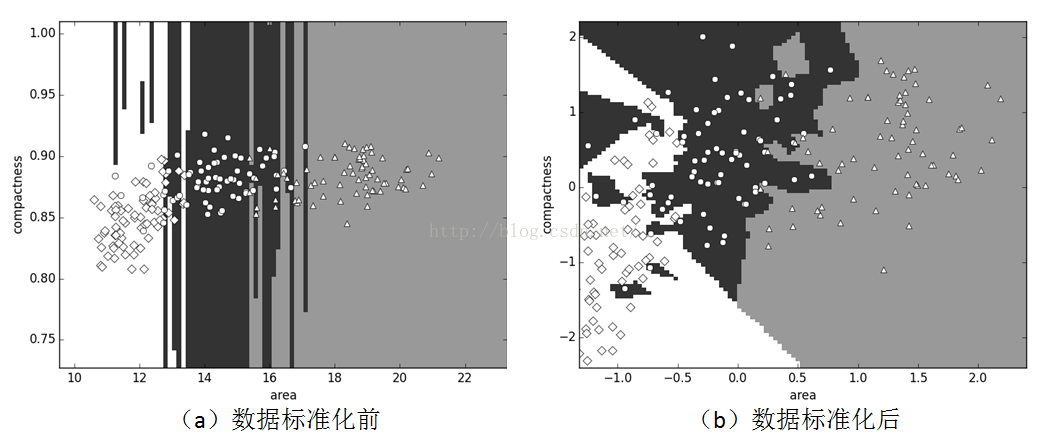
在a图中,Canadian种子用菱形表示,Kama种子用圆圈表示,Rosa种子用三角形表示。它们的区域分别是白死、黑色和灰色表示。这些判别区域都是水平方向,原因在于x轴(面积)的值域在10到22之间,而y轴(紧密度)在0.75至1.0之间。这意味着x值的一小点改变实际上比y值的一小点变化大的多。所以,在计算新数据点与原数据点的距离时,多半只把x轴考虑了进去。
为了解决上述问题,需要把所有特征都归一化到一个公共尺度上。一个常用的归一化方法是Z值(Z-score)。Z值表示的是特征值离它的平均值有多远,它用标准方差的数量来计算。其公式如下:
#
从特征值中减去特征的平均值
features -=features.mean(0)
# 将特征值除以它的标准差
features /=features.std(0)
在b图中,分界面变得复杂,而且在两个维度之间有一个相互交叉。对只使用面积特征Area和紧密度特征Compactness训练的k-近邻分类器进行交叉验证,我们会发现其准确率并不高:
模型准确率: 1.000000
Ten fold cross-validated error was86.2%.
模型准确率: 1.000000
Ten fold cross-validated errorafter z-scoring was 82.4%.
在训练集上进行测试的准确率都是100%,而使用10-折交叉验证,特征归一化前准确率86.2%,归一化后准确率反而下降到82.4%。这也从准确率的角度印证了图b分界边界复杂,分类效果不佳的情况。
综上所述,特征归一化是必要的,同时还应该加入更多的特征来保证良好的分类效果。
程序清单:
#coding=utf-8
COLOUR_FIGURE = False
from matplotlib import pyplot as plt
from matplotlib.colors import ListedColormap
from load import load_dataset
import numpy as np
from knn import learn_model, apply_model, accuracy
from seeds_knn import cross_validate
feature_names = [
'area',
'perimeter',
'compactness',
'length of kernel',
'width of kernel',
'asymmetry coefficien',
'length of kernel groove',
]
def train_plot(features, labels):
y0,y1 = features[:,2].min()*.9, features[:,2].max()*1.1
x0,x1 = features[:,0].min()*.9, features[:,0].max()*1.1
X = np.linspace(x0,x1,100)
Y = np.linspace(y0,y1,100)
X,Y = np.meshgrid(X,Y)
model = learn_model(1, features[:, (0,2)], np.array(labels))
test_error = accuracy(features[:, (0,2)], np.array(labels), model)
print (u"模型准确率: %f") % test_error
C = apply_model(np.vstack([X.ravel(),Y.ravel()]).T, model).reshape(X.shape)
if COLOUR_FIGURE:
cmap = ListedColormap([(1.,.6,.6),(.6,1.,.6),(.6,.6,1.)])
else:
cmap = ListedColormap([(1.,1.,1.),(.2,.2,.2),(.6,.6,.6)])
plt.xlim(x0,x1)
plt.ylim(y0,y1)
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[2])
plt.pcolormesh(X,Y,C, cmap=cmap)
if COLOUR_FIGURE:
cmap = ListedColormap([(1.,.0,.0),(.0,1.,.0),(.0,.0,1.)])
plt.scatter(features[:,0], features[:,2], c=labels, cmap=cmap)
else:
for lab,ma in zip(range(3), "Do^"):
plt.plot(features[labels == lab,0], features[labels == lab,2], ma, c=(1.,1.,1.))
features,labels = load_dataset('seeds')
names = sorted(set(labels))
labels = np.array([names.index(ell) for ell in labels])
train_plot(features, labels)
error = cross_validate(features[:, (0, 2)], labels)
print('Ten fold cross-validated error was {0:.1%}.\n'.format(error))
plt.savefig('../1400_02_04.png')
plt.show()
# 从特征值中减去特征的平均值
features -= features.mean(0)
# 将特征值除以它的标准差
features /= features.std(0)
train_plot(features, labels)
error = cross_validate(features[:, (0, 2)], labels)
print('Ten fold cross-validated error after z-scoring was {0:.1%}.'.format(error))
plt.savefig('../1400_02_05.png')
plt.show()4. 实施kNN算法
本节列出kNN算法的Python语言实现,首先给出k-近邻算法的伪代码:对未知类别属性的数据集中的每个点一次执行以下操作:
(1) 计算已知类别数据集中的每个点与当前的的欧氏距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类。
程序清单:
#coding=utf-8 import numpy as np def learn_model(k, features, labels): return k, features.copy(),labels.copy() def plurality(xs): from collections import defaultdict counts = defaultdict(int) # 默认字典 for x in xs: counts[x] += 1 # 以标签作为key值,类别对应的频次为value maxv = max(counts.values()) for k,v in counts.items(): if v == maxv: return k def apply_model(features, model): k, train_feats, labels = model results = [] for f in features: label_dist = [] for t,ell in zip(train_feats, labels): label_dist.append( (np.linalg.norm(f-t), ell) ) label_dist.sort(key=lambda d_ell: d_ell[0]) label_dist = label_dist[:k] # 取与新数据点欧氏距离最近的前k个样本 results.append(plurality([ell for _ , ell in label_dist])) return np.array(results) def accuracy(features, labels, model): preds = apply_model(features, model) return np.mean(preds == labels)
5. 分类预测和交叉验证
本节主要利用kNN算法,在一个真实的Seeds数据集上构建一个完整的分类器,然后用采用交叉验证评价模型。程序清单:
5.1 load.py
import numpy as np
def load_dataset(dataset_name):
'''
data,labels = load_dataset(dataset_name)
Load a given dataset
Returns
-------
data : numpy ndarray
labels : list of str
'''
data = []
labels = []
with open('../data/{0}.tsv'.format(dataset_name)) as ifile:
for line in ifile:
tokens = line.strip().split('\t')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
data = np.array(data)
labels = np.array(labels)
return data, labels5.2 knn.py
(已经在第4节出现。)
5.3 seeds_knn.py
from load import load_dataset
import numpy as np
from knn import learn_model, apply_model, accuracy
features,labels = load_dataset('seeds')
def cross_validate(features, labels):
error = 0.0
for fold in range(10):
training = np.ones(len(features), bool)
training[fold::10] = 0
testing = ~training
model = learn_model(1, features[training], labels[training])
test_error = accuracy(features[testing], labels[testing], model)
error += test_error
return error/ 10.0
error = cross_validate(features, labels)
print('Ten fold cross-validated error was {0:.1%}.'.format(error))
features -= features.mean(0)
features /= features.std(0)
error = cross_validate(features, labels)
print('Ten fold cross-validated error after z-scoring was {0:.1%}.'.format(error))5.4 测试结果:
F:\ProgramFile\Python27\python.exe E:/py_Space/ML_C2/code/seeds_knn.pyTenfold cross-validated error was 89.5%.
Tenfold cross-validated error after z-scoring was
94.3%.
从结果上来看,采用kNN算法在归一化特征数据集Seeeds上的交叉验证分类准确率到达94.3%,取得了一个较为满意的结果。

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法