Ubuntu系统下的Hadoop集群(3)_Hadoop单机版自定义实现类以及编译运行
2015-08-10 19:58
627 查看
Hadoop 单机版——自定义实现类以及编译运行
概述
博主最近在学hadoop,而且在本实验室一位大神的指导下,我已配置好hadoop2.4.1开发环境,还没有配置或者不会配置的,请看链接hadoop单机版配置。由于之前运行的都是hadoop自带的实例,但是对于个人学习而言,肯定是要自己编写实现类以及编译运行实现类,因此博主就撰写了这篇文章,希望对学习hadoop的同道中人有所帮助。
编写实现类
首先在hadoop的根目录下新建一个工作目录workspace,即在/usr/local/hadoop执行命令
新建工作目录
接着在workspace目录下编写WordCount.java类

编写WordCount.java
(注:原图中有错误,应该是WordCount.java)
WordCount.java代码如下,各位可以自己复制粘帖,在hadoop官方网站上也可以找到。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {int sum = 0;
for (IntWritable val : values) {sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
[/code]
编译运行
接着将该WordCount.java文件编译为class文件,在编译之前,还需添加以下环境变量首先添加JAVA_HOME,因为我用的是系统自带的jdk,所以路径如下图所示:

添加JAVA_HOME环境变量2.将jdk目录下的bin文件夹添加到环境变量:

将bin文件夹加到环境变量
3.接着将hadoop_classpath添加到环境变量:

将hadoop_classpath加到环境变量
执行上述步骤后,即可开始编译WordCount.java文件,编译java文件的命令为javac,截图如下:

编译WordCount.java
此时,在workspace文件夹下将会出现生成三个class文件,

编译后生成class文件
编译成功后,即可将三个class文件打包成jar文件,

打包class成jar文件
执行成功后,在workspace文件下生成了WordCount.jar文件,

打包jar完成
接着,在/usr/local/hadoop文件夹下新建一个input文件夹,用于存放数据,

创建input文件夹
接着cd 到input文件下,执行以下命令,就是将’Hello World Bye World’写进file01文件,将’Hello Hadoop Goodbye Hadoop’ 写进file02文件
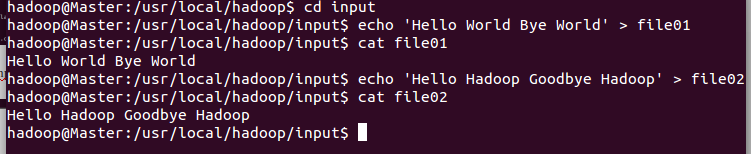
创建输入数据
最后运行程序,

运行程序
期间可以到程序执行的过程,
执行过程
最后,将output目录下的文件输出,即可到程序运行的结果,
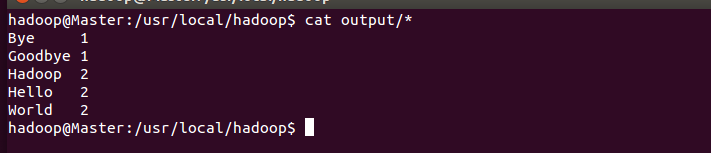
运行结果
到此,编写一个mapreduce实现类以及编译运行就成功实现了。
注:每次运行程序之前,要将之前运行的产生的output删除,不然程序会报错!
附(命令行指令):
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
../bin/hadoop com.sun.tools.javac.Main WordCount.java
ls -l
jar cf WordCount.jar WordCount*.class
cd input
echo 'Hello World Bye World'>file01
cat file01
echo 'Hello Hadoop Goodbye Hadoop'>file02
cat file02
bin/hadoop jar workspace/WordCount.jar WordCount input output
按照上面的说明进行操作,会出现如下错误:
15/08/10 18:30:10 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
15/08/10 18:30:10 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
15/08/10 18:30:11 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
15/08/10 18:30:11 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/usr/local/hadoop/tmp/mapred/staging/hadoop1178253544/.staging/job_local1178253544_0001
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist:hdfs://localhost:9000/user/hadoop/input
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at WordCount.main(WordCount.java:51)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
根据前面两篇文章,配置伪分布式环境时,要对core-site.xml 文件进行修改,所以很可能是产生上述错误的原因:
关于hdfs://localhost:9000和配置文件 core-site.xml (打开路径:
vim /usr/local/hadoop/etc/hadoop/core-site.xml)
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
开始验证,对core-site.xml文件修改,重新执行上述操作,成功
15/08/10 19:49:18 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
15/08/10 19:49:18 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
15/08/10 19:49:18 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
15/08/10 19:49:18 INFO input.FileInputFormat: Total input paths to process : 2
15/08/10 19:49:19 INFO mapreduce.JobSubmitter: number of splits:2
15/08/10 19:49:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1199218082_0001
15/08/10 19:49:19 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
15/08/10 19:49:19 INFO mapreduce.Job: Running job: job_local1199218082_0001
15/08/10 19:49:19 INFO mapred.LocalJobRunner: OutputCommitter set in config null
15/08/10 19:49:19 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
15/08/10 19:49:19 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Waiting for map tasks
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Starting task: attempt_local1199218082_0001_m_000000_0
15/08/10 19:49:20 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
15/08/10 19:49:20 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/08/10 19:49:20 INFO mapred.MapTask: Processing split: file:/usr/local/hadoop/input/file02:0+28
15/08/10 19:49:20 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
15/08/10 19:49:20 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
15/08/10 19:49:20 INFO mapred.MapTask: soft limit at 83886080
15/08/10 19:49:20 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
15/08/10 19:49:20 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
15/08/10 19:49:20 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
15/08/10 19:49:20 INFO mapred.LocalJobRunner:
15/08/10 19:49:20 INFO mapred.MapTask: Starting flush of map output
15/08/10 19:49:20 INFO mapred.MapTask: Spilling map output
15/08/10 19:49:20 INFO mapred.MapTask: bufstart = 0; bufend = 44; bufvoid = 104857600
15/08/10 19:49:20 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600
15/08/10 19:49:20 INFO mapred.MapTask: Finished spill 0
15/08/10 19:49:20 INFO mapred.Task: Task:attempt_local1199218082_0001_m_000000_0 is done. And is in the process of committing
15/08/10 19:49:20 INFO mapred.LocalJobRunner: map
15/08/10 19:49:20 INFO mapred.Task: Task 'attempt_local1199218082_0001_m_000000_0' done.
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Finishing task: attempt_local1199218082_0001_m_000000_0
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Starting task: attempt_local1199218082_0001_m_000001_0
15/08/10 19:49:20 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
15/08/10 19:49:20 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/08/10 19:49:20 INFO mapred.MapTask: Processing split: file:/usr/local/hadoop/input/file01:0+22
15/08/10 19:49:20 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
15/08/10 19:49:20 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
15/08/10 19:49:20 INFO mapred.MapTask: soft limit at 83886080
15/08/10 19:49:20 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
15/08/10 19:49:20 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
15/08/10 19:49:20 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
15/08/10 19:49:20 INFO mapred.LocalJobRunner:
15/08/10 19:49:20 INFO mapred.MapTask: Starting flush of map output
15/08/10 19:49:20 INFO mapred.MapTask: Spilling map output
15/08/10 19:49:20 INFO mapred.MapTask: bufstart = 0; bufend = 38; bufvoid = 104857600
15/08/10 19:49:20 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600
15/08/10 19:49:20 INFO mapred.MapTask: Finished spill 0
15/08/10 19:49:20 INFO mapred.Task: Task:attempt_local1199218082_0001_m_000001_0 is done. And is in the process of committing
15/08/10 19:49:20 INFO mapred.LocalJobRunner: map
15/08/10 19:49:20 INFO mapred.Task: Task 'attempt_local1199218082_0001_m_000001_0' done.
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Finishing task: attempt_local1199218082_0001_m_000001_0
15/08/10 19:49:20 INFO mapred.LocalJobRunner: map task executor complete.
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Waiting for reduce tasks
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Starting task: attempt_local1199218082_0001_r_000000_0
15/08/10 19:49:20 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
15/08/10 19:49:20 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
15/08/10 19:49:20 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1197c2dd
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=10
15/08/10 19:49:20 INFO reduce.EventFetcher: attempt_local1199218082_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
15/08/10 19:49:20 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1199218082_0001_m_000001_0 decomp: 36 len: 40 to MEMORY
15/08/10 19:49:20 INFO reduce.InMemoryMapOutput: Read 36 bytes from map-output for attempt_local1199218082_0001_m_000001_0
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 36, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->36
15/08/10 19:49:20 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
15/08/10 19:49:20 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1199218082_0001_m_000000_0 decomp: 41 len: 45 to MEMORY
15/08/10 19:49:20 INFO reduce.InMemoryMapOutput: Read 41 bytes from map-output for attempt_local1199218082_0001_m_000000_0
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 41, inMemoryMapOutputs.size() -> 2, commitMemory -> 36, usedMemory ->77
15/08/10 19:49:20 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
15/08/10 19:49:20 INFO mapred.LocalJobRunner: 2 / 2 copied.
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: finalMerge called with 2 in-memory map-outputs and 0 on-disk map-outputs
15/08/10 19:49:20 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
15/08/10 19:49:20 INFO mapred.Merger: Merging 2 sorted segments
15/08/10 19:49:20 INFO mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 61 bytes
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: Merged 2 segments, 77 bytes to disk to satisfy reduce memory limit
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: Merging 1 files, 79 bytes from disk
15/08/10 19:49:20 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
15/08/10 19:49:20 INFO mapred.Merger: Merging 1 sorted segments
15/08/10 19:49:20 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 69 bytes
15/08/10 19:49:20 INFO mapred.LocalJobRunner: 2 / 2 copied.
15/08/10 19:49:20 INFO mapreduce.Job: Job job_local1199218082_0001 running in uber mode : false
15/08/10 19:49:20 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
15/08/10 19:49:20 INFO mapred.Task: Task:attempt_local1199218082_0001_r_000000_0 is done. And is in the process of committing
15/08/10 19:49:20 INFO mapred.LocalJobRunner: 2 / 2 copied.
15/08/10 19:49:20 INFO mapred.Task: Task attempt_local1199218082_0001_r_000000_0 is allowed to commit now
15/08/10 19:49:20 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1199218082_0001_r_000000_0' to file:/usr/local/hadoop/output/_temporary/0/task_local1199218082_0001_r_000000
15/08/10 19:49:20 INFO mapred.LocalJobRunner: reduce > reduce
15/08/10 19:49:20 INFO mapred.Task: Task 'attempt_local1199218082_0001_r_000000_0' done.
15/08/10 19:49:20 INFO mapred.LocalJobRunner: Finishing task: attempt_local1199218082_0001_r_000000_0
15/08/10 19:49:20 INFO mapred.LocalJobRunner: reduce task executor complete.
15/08/10 19:49:20 INFO mapreduce.Job: map 100% reduce 100%
15/08/10 19:49:20 INFO mapreduce.Job: Job job_local1199218082_0001 completed successfully
15/08/10 19:49:21 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=10802
FILE: Number of bytes written=837543
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=82
Map output materialized bytes=85
Input split bytes=200
Combine input records=8
Combine output records=6
Reduce input groups=5
Reduce shuffle bytes=85
Reduce input records=6
Reduce output records=5
Spilled Records=12
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=116
Total committed heap usage (bytes)=455946240
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=50
File Output Format Counters
Bytes Written=53
执行结果符合预期:
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
实验结束后,重新更改core-site.xml文件。
原文来自:http://dblab.xmu.edu.cn/blog/wordcount/

相关文章推荐
- CentOS搭建Gitosis服务器
- Fbric、Ansible、Docker、Chaos Monkey:DevOps工具的年中回顾
- Fbric、Ansible、Docker、Chaos Monkey:DevOps工具的年中回顾
- CentOS6下安装docker
- 几个Linux distribution安装时可能用到的国内NTP server
- linux编程心得3:WebBench编译
- CentOS添加永久静态路由
- Linux常用命令(四)
- Android的MediaPlayer架构介绍
- 使用两个镜像安装CentOS切换镜像报错问题
- Linux裸设备管理详解
- CentOS安装GitLab
- (转)CentOS下一键安装GitLab
- [第2章]多线程:NSOperation的简单使用
- hadoop提供了一个跑在yarn上的示例,可以运行
- Linux进程管理 - ps,top,pstree,signal,kill,killall举例演示
- Linux进程管理 - ps,top,pstree,signal,kill,killall举例演示
- Linux进程的实际用户ID和有效用户ID
- 4、嵌入式开发之centos6.6+vmware绑定双网卡
- 关于linux内核重要文件的基本描述