hihocoder1032 最长回文子串
2015-08-10 10:03
204 查看
传说中的Manacher算法,算法的核心就在这一句上了:p[i] = min(p[2*id-i], p[id] + id - i);
这个算法要解决的就是一个字符串中最长的回文子串有多长。这个算法可以在O(n)的时间复杂度内既线性时间复杂度的情况下,求出以每个字符为中心的最长回文有多长,这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w# a # a # b# w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
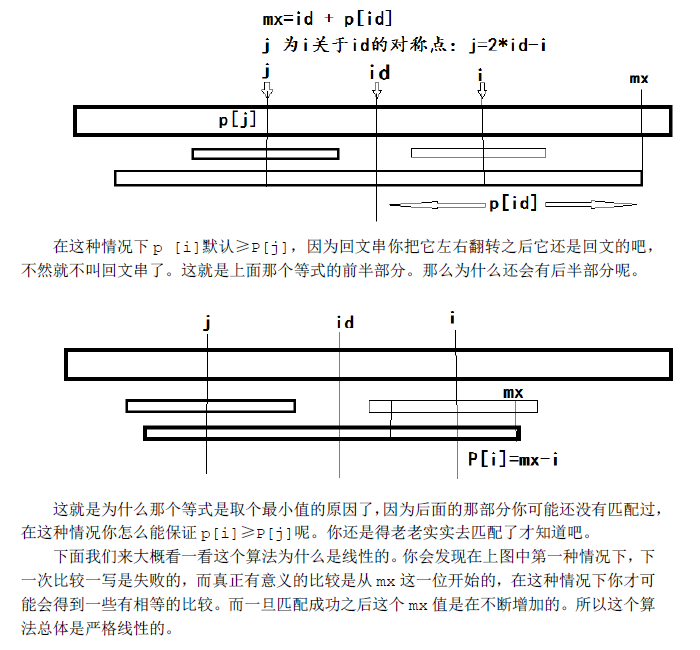
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
if( mx > i)
p[i]=MIN( p[2*id-i], mx-i);
就是当前面比较的最远长度mx>i的时候,P[i]有一个最小值。这个算法的核心思想就在这里,为什么P数组满足这样一个性质呢?
(下面的部分为图片形式)
这个算法要解决的就是一个字符串中最长的回文子串有多长。这个算法可以在O(n)的时间复杂度内既线性时间复杂度的情况下,求出以每个字符为中心的最长回文有多长,这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w# a # a # b# w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
if( mx > i)
p[i]=MIN( p[2*id-i], mx-i);
就是当前面比较的最远长度mx>i的时候,P[i]有一个最小值。这个算法的核心思想就在这里,为什么P数组满足这样一个性质呢?
(下面的部分为图片形式)
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define M 1000005
string s;
int f[M*2+4];
int solve(string s)
{
string s1;
s1.resize(s.length()*2+2);
s1[0]='$';
s1[1]='#';
for(int i=0;i<s.length();i++)
{
s1[(i+1)<<1]=s[i]; //从1开始的
s1[(i+1)*2+1]='#';
}
memset(f,0,sizeof(f));
int ans=0,mx=0; //mx即为上面说的最右端的位置
for(int id=0,i=1;i<s1.length();i++)
{
if(mx>i)
f[i]=min(f[id*2-i],f[id]-i+id);
else
f[i]=1;
while(s1[i+f[i]]==s1[i-f[i]]) //更新i位置的f[i]
f[i]++;
if(f[i]+i>mx)
{
mx=f[i]+i;
id=i;
}
ans=max(f[i],ans);
}
return ans-1;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
cin >> s;
printf("%d\n",solve(s));
}
return 0;
}

相关文章推荐
- 关于CPU过热导致主机自行断电重启的解决办法
- ios网络编程(http、socket)
- 如果大家关注SOA的事务一致性的处理,那么不妨看看我们是怎么解决的
- Android利用activity启动模式退出整个应用
- HDU 4818 RP problem 高斯消元
- 计蒜客 难题题库 200 判断m是否为质数
- 计蒜客 难题题库 176 判断链表是否有环
- 关于jsp页面头部<%@ %>报错的问题
- Android 异步消息处理机制 让你深入理解 Looper、Handler、Message三者关系
- Pricing Factors
- 转载:HttpClient使用详解
- JavaScript学习笔记——对表单的操作
- SOA初探
- 如何用代码控制以不同屏幕方向打开新页面【iOS】
- 打造安全的App!iOS安全系列之 HTTPS
- 源码推荐(8.10):iOS 大文件断点下载库,仿微信发布语音
- hdu 1558 Segment set(线段相交+并查集)
- poj 1470 Closest Common Ancestors 【并查集 求根 + 求解每一个节点是多少对(a,b)的LCA】
- 【汇编语言】纯汇编语言编写打飞机小游戏
- HDOJ1233 还是畅通工程(kru)