Read Large Files in Python
2015-08-07 08:01
537 查看
I have a large file ( ~4G) to process in Python. I wonder whether it is OK to "read" such a large file. So I tried in the following several ways:
The original large file to deal with is not "./CentOS-6.5-i386.iso", I just take this file as an example here.
1: Normal Method. (ignore try/except/finally)
2: "With" Method.
3: "readlines" Method. [Bad Idea]
4: "fileinput" Method.
5: "Generator" Method.
The methods above, all work well for small files, but not always for large files(readlines Method). The readlines() function loads the entire file into memory as it runs.
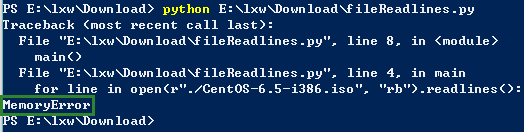
When I run the readlines Method, I got the following error message:
When using the readlines Method, the Percentage of Used CPU and Used Memory rises rapidly(in the following figure). And when the percentage of Used Memory reaches over 50%, I got the "MemoryError" in Python.

The other methods (Normal Method, With Method, fileinput Method, Generator Method) works well for large files. And when using these methods, the workload for CPU and memory which is shown in the following figure does not get a distinct rise.

By the way, I recommend the generator method, because it shows clearly that you have taken the file size into account.
Reference:
How to read large file, line by line in python
The original large file to deal with is not "./CentOS-6.5-i386.iso", I just take this file as an example here.
1: Normal Method. (ignore try/except/finally)
def main(): f = open(r"./CentOS-6.5-i386.iso", "rb") for line in f: print(line, end="") f.close() if __name__ == "__main__": main()
2: "With" Method.
def main(): with open(r"./CentOS-6.5-i386.iso", "rb") as f: for line in f: print(line, end="") if __name__ == "__main__": main()
3: "readlines" Method. [Bad Idea]
#NO. readlines() is really bad for large files. #Memory Error. def main(): for line in open(r"./CentOS-6.5-i386.iso", "rb").readlines(): print(line, end="") if __name__ == "__main__": main()
4: "fileinput" Method.
import fileinput def main(): for line in fileinput.input(files=r"./CentOS-6.5-i386.iso", mode="rb"): print(line, end="") if __name__ == "__main__": main()
5: "Generator" Method.
def readFile(): with open(r"./CentOS-6.5-i386.iso", "rb") as f: for line in f: yield line def main(): for line in readFile(): print(line, end="") if __name__ == "__main__": main()
The methods above, all work well for small files, but not always for large files(readlines Method). The readlines() function loads the entire file into memory as it runs.
When I run the readlines Method, I got the following error message:
When using the readlines Method, the Percentage of Used CPU and Used Memory rises rapidly(in the following figure). And when the percentage of Used Memory reaches over 50%, I got the "MemoryError" in Python.
The other methods (Normal Method, With Method, fileinput Method, Generator Method) works well for large files. And when using these methods, the workload for CPU and memory which is shown in the following figure does not get a distinct rise.
By the way, I recommend the generator method, because it shows clearly that you have taken the file size into account.
Reference:
How to read large file, line by line in python

相关文章推荐
- python基础学习笔记<内建模块与第三方模块>
- python基础学习笔记<进阶>
- Python开源异步并发框架
- Python开源异步并发框架
- pycurl,Python cURL library
- pycurl,Python cURL library
- python中if __name__ == '__main__': 的解析
- python中if __name__ == '__main__': 的解析
- Python转码问题的解决方法:ignore,replace,xmlcharrefreplace
- Python转码问题的解决方法:ignore,replace,xmlcharrefreplace
- python:利用asyncio进行快速抓取
- python:利用asyncio进行快速抓取
- Python: 在Unicode和普通字符串之间转换
- Python: 在Unicode和普通字符串之间转换
- chr()、unichr()和ord(),全半角转换,ValueError: unichr() arg not in range() (wide Python build)
- chr()、unichr()和ord(),全半角转换,ValueError: unichr() arg not in range() (wide Python build)
- Python中单引号、双引号和三引号的区别
- Python中单引号、双引号和三引号的区别
- python概要
- python概要