文件编码和RandomAccessFile文件流的使用--IO学习笔记(一)
2015-08-06 13:58
746 查看
文件编码
UTF-8编码:中文占用3个字节,英文占用1个字节GBK编码:中文占用2个字节,英文占用1个字节
UTF-16BE编码:中文占用2个字节,英文占用两个字节
注意:其中UTF-16BE编码是java的双字节编码采用的编码方式。Java里使用的是UTF-16BE 方式来存储数据的。eg:String 字符串就是采用UTF-16BE编码。
package com.test.test;
/**
* 使用三种编码方式打印同一个字符串,查看每种编码方式所占用字节多少的区别
*
*/
public class Test {
public static void main(String[] args) throws Exception{
String s = "小灰灰ABC";
encodeGBK(s);
encodeUTF8(s);
encodeUTF16BE(s);
}
/**
* 使用GBK编码方式
* @param s
*/
private static void encodeGBK(String s) {
System.out.println("GBK编码:");
// 将字符串转换成字节数组(默认采用的是项目设置的编码格式(我这里设置的是GBK)的转换的编码格式)
byte[] byte1 = s.getBytes();
for (byte b : byte1) {
/*
* 1.toHexString()方法,把字节转换成了int类型并且以16进制的方式显示
* 2.方法中把byte(字节)转换成了int类型
* 3.&0xff的意思是只取最低的后8位:因为int类型占32位(4个字节)但是byte类型是占用8位(1个字节),
* 所以将byte转换成int后,int类型前面的24位就会是0,所以可以使用&0xff只取后8位
*/
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
System.out.println();
}
/**
* 使用UTF-8编码方式
* @param s
*/
private static void encodeUTF8(String s) throws Exception{
System.out.println("UTF8编码:");
// 将字符串转换成字节数组(默认采用的是项目设置的编码格式(我这里设置的是GBK)的转换的编码格式)
byte[] byte1 = s.getBytes("utf-8");
for (byte b : byte1) {
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
System.out.println();
}
/**
* 使用UTF-16BE编码方式
* @param s
*/
private static void encodeUTF16BE(String s) throws Exception{
System.out.println("UTF16BE编码:");
// 将字符串转换成字节数组(默认采用的是项目设置的编码格式(我这里设置的是GBK)的转换的编码格式)
byte[] byte1 = s.getBytes("utf-16be");
for (byte b : byte1) {
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
System.out.println();
}
}结果截图:
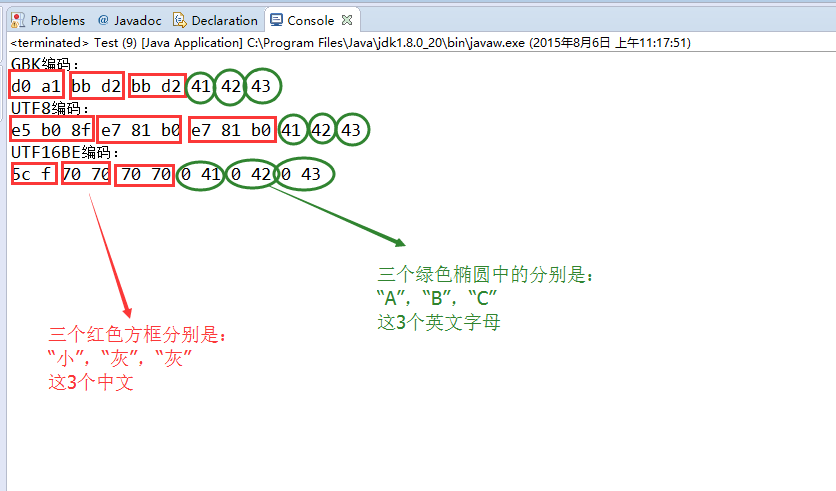
从图中可以看出这三种编码方式的中英文所占用的字节数的差别。
注意:当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码。
eg:
package com.test.test;
public class Test {
public static void main(String[] args) throws Exception{
String s = "小灰灰ABC";
System.out.println("UTF8编码:");
// 将字符串转换成字节数组(默认采用的是项目设置的编码格式(我这里设置的是GBK)的转换的编码格式)
byte[] bytes = s.getBytes("utf-8");
for (byte b : bytes) {
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
System.out.println();
String str = new String(bytes);//这里使用的是项目设置的编码格式(我设置的是GBK编码)
System.out.println(str);
}
}结果截图:
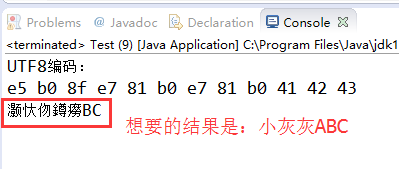
这里可以知道如果想要出现原来的结果就必须采用原来的编码方式转换。
所以上边的构造字符串的代码应该修改为:
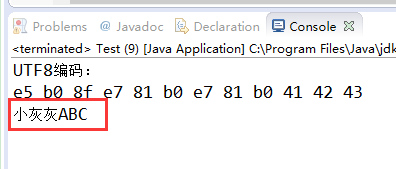
String str = new String(bytes,“utf-8”);
就会出现正确的结果:
RandomAccessFile文件流:
java文件的模型:在硬盘上的文件是byte byte byte存储的,是数据的集合。
1.介绍:
(1)RandomAccessFile是java提供的对文件内容的访问类,既可以读文件,也可以写文件。
(2)支持随机访问文件,可以访问文件的任意位置
2.打开文件
有两种方式:“rw”(读写)和“r”(只读)
eg:
RandomAccessFile raf = new RandomAccessFile(file,”rw”);
3.文件指针
这里的文件指针就是RandomAccessFile可以访问文件任意位置的基础。
打开文件的时候指针在开头,pointer = 0;
获取文件指针的方法:raf.getFilePointer();
4.写方法
raf.write();
只能写一个字节(也就是只写最后的8位),写完之后指针会自动指向下一个位置,准备再次写入。
5.读文件
int i = raf.read();
从指针所在的位置读一个字节,同时将这个字节转换成为int类型,就是说都出一个字节,填充到int的最后8位。
read();只能读取一个字节。
read(byte[]);就可以读到一个字节数组里边
6.关闭流
raf.close();
文件读写完成后一定要关闭流
下面是RandomAccessFile类的基本的使用方法的例子:
package com.test.random;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.Arrays;
public class RandomAccessFileTest {
public static void main(String[] args) throws IOException {
File dir = new File("demo");// 如果没有写绝对路径,那么默认就是在项目中创建该文件
if (!dir.exists()) {
dir.mkdir();//创建目录文件
}
File file = new File(dir, "test.txt");
if (!file.exists()) {
file.createNewFile();//创建文件
}
RandomAccessFile raf = new RandomAccessFile(file, "rw");//设置可读,可写操作
System.out.println("指针的位置:"+raf.getFilePointer());//指针的位置
//写一个字节(后8位)进去(这里写入的内容是char类型的,其实char类型所占就是8位(1个字节),所以这里可以完整的写入一个A)
raf.write('A');
System.out.println("指针的位置:"+raf.getFilePointer());//指针的位置
raf.write('B');
System.out.println("已经写入的长度:"+raf.length());//写入的长度
//用write()方法,写一个int类型的值(int是4个字节(32位))
int i = 1;
raf.write(i>>>24&0xff);//写int的最高8位(24-32之间的8位)
raf.write(i>>>16&0xff);//写int的(16-24之间的8位)
raf.write(i>>>8&0xff);//写int的(8-16之间的8位)
raf.write(i&0xff);//写int的后8位(0-8之间的8位)
//用writeInt()方法(RandomAccessFile自带的写int类型的方法),写一个int类型的值
int j = 1;
raf.writeInt(j);//其实writeInt()方法内部就是通过上边的方法实现的写int类型的值
System.out.println("指针的位置:"+raf.getFilePointer());
System.out.println("已经写入的长度:"+raf.length());
//写一个String类型的值
String s = "我";//中文是2个字节(16位)
byte[] bytes = s.getBytes();//将String类型转换成字节数组(byte类型的),byte占用1个字节(8位)
raf.write(bytes);//write()方法可以写一个字节数组
//如果想从头开始读取文件内容,就必须把指针移到文件头部
raf.seek(0);//把指针移到文件的头部
//一次性读取,把文件的内容都读到字节数组中去
byte[] buf = new byte[(int)raf.length()];
raf.read(buf);
System.out.println(Arrays.toString(buf));
//封装成字符串
String str = new String(buf);
System.out.println(str);
//以16进制的方式输出
for (byte b : buf) {
System.out.println(Integer.toHexString(b&0xff)+" ");
}
raf.close();
}
}结果截图:


相关文章推荐
- Tomcat端口被占用解决方法(不用重启)
- “传奇”图象数据存储方式
- 超大数据量存储常用数据库分表分库算法总结
- SQL Server误区30日谈 第18天 有关FileStream的存储,垃圾回收以及其它
- XML指南——XML编码
- C#中字符串编码处理
- ExtJS中文乱码之GBK格式编码解决方案及代码
- 程序员趣味读物 谈谈Unicode编码
- 文本文件编码方式区别
- C++实现图的邻接表存储和广度优先遍历实例分析
- C语言安全编码之数值中的sizeof操作符
- C#实现获取文本文件的编码的一个类(区分GB2312和UTF8)
- VC中BASE64编码和解码使用详解
- 计算机中的字符串编码、乱码、BOM等问题详解
- Base64编码解码原理及C#编程实例
- C#编码好习惯小结
- javascript编码的几个方法详细介绍
- C#调用sql2000存储过程方法小结
- UTF8编码开发中页面空白问题的解决方法
- php生成固定长度纯数字编码的方法