机器学习算法需要注意的一些问题
2015-07-28 19:22
239 查看
对于机器学习的实际运用,光停留在知道了解的层面还不够,我们需要对实际中容易遇到的一些问题进行深入的挖掘理解。我打算将一些琐碎的知识点做一个整理。
更多于此话题相关内容请移步:
分类中数据不平衡问题的解决经验
机器学习中的数据不平衡问题
下载摘自某大牛博客一段话:
异常值并非错误值,而同样是真实情况的表现,我们之所以认为异常,只是因为我们的数据量不足够大而已。但是从实际的工业界来看,考虑到实际的计算能力以及效果,大多数公司都会对大数据做“去噪”,那么在去噪的过程中去除的不仅仅是噪音,也包括“异常点”,而这些“异常点”,恰恰把大数据的广覆盖度给降低了,于是利用大数据反而比小数据更容易产生趋同的现象。尤其对于推荐系统来说,这些“异常点”的观察其实才是“个性化”的极致。
既然说到大数据,同样是这位大牛的一段话:
说得学术一些,我们不妨认为大数据是频率学派对于贝叶斯学派一次强有力的逆袭。那么既然说到这个份上了,我们不妨思考一下,我们是不是有希望在回归贝叶斯学派,利用先验信息+小数据完成对大数据的反击呢?
某些机器学习算法对异常值很敏感,比如:K-means聚类,AdaBoost。使用此类算法必须处理异常值。
某些算法拥有对异常值不敏感的特性,比如:KNN,随机森林。
如何处理异常值?最简单的方法就是直接丢掉。其它方法我后面会继续研究。
训练数据太少
模型太复杂
训练数据中存在噪声点(就算训练数据足够多)
几乎所有的机器学习算法都会容易遇到过拟合的问题。所以先说一些解决过拟合的通用办法。当然,首先得保证训练数据不要太少。
线性回归正则化就是岭回归和lasso回归,分别对应L2,L1罚项。
决策树正则化就是剪枝,通常把子节点个数作为罚项。
其它详细研究请点击:
机器学习过度拟合问题一些原因
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
in a word, feature engineering is manually designing what the input x’s should be.
1. 特征维数越高,模型越容易过拟合,此时更复杂的模型就不好用。
2. 相互独立的特征维数越高,在模型不变的情况下,在测试集上达到相同的效果表现所需要的训练样本的数目就越大。
3. 特征数量增加带来的训练、测试以及存储的开销都会增大。
4. 在某些模型中,例如基于距离计算的模型KMeans,KNN等模型,在进行距离计算时,维度过高会影响精度和性能。
5. 可视化分析的需要。在低维的情况下,例如二维,三维,我们可以把数据绘制出来,可视化地看到数据。当维度增高时,就难以绘制出来了。
在机器学习中,有一个非常经典的维度灾难的概念。用来描述当空间维度增加时,分析和组织高维空间,因体积指数增加而遇到各种问题场景。例如,100个平均分布的点能把一个单位区间以每个点距离不超过0.01采样;而当维度增加到10后,如果以相邻点距离不超过0.01小方格采样单位超一单位超正方体,则需要10^20 个采样点。
正是由于高维特征有如上描述的各种各样的问题,所以我们需要进行特征降维和特征选择等工作。
特征降维常用的算法有PCA,LDA等。
PCA算法通过协方差矩阵的特征值分解能够得到数据的主成分,以二维特征为例,两个特征之间可能存在线性关系(例如运动的时速和秒速度),这样就造成了第二维信息是冗余的。PCA的目标是发现这种特征之间的线性关系,并去除。
LDA算法考虑label,降维后的数据点尽可能地容易被区分。
然后,是不是特征越多越好?其实也不是。盗一张图过来如下:
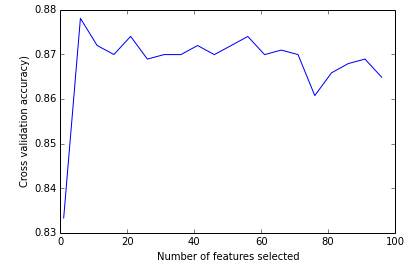
可以发现,刚开始模型的准确率随着特征数量的增加而增加,当增加到一定程度便趋于稳定了。如果还要强行加入如此多的特征,反而画蛇添足,容易过拟合。然后,如果出现特征过多出现过拟合的情况,就要适当地进行参数缩减。对于逻辑斯蒂回归,某一维特征对应的参数如果接近为零,说明这个特征影响不大,就可以去掉。因此,我们的特征选择过程一般如下:
选取尽可能多的特征,必要时先进行降维
对特征进行选择,保留最具有代表性的特征
这个过程的进行要同时观察模型准确率的变化。
最后,特征选择有哪些算法呢?
- 过滤方法:将所有特征进行打分评价,选择最有效的一些特征。比如:卡法检验,信息增益,相关系数打分。
- 包装方法:将特征组合的选择看做是一个在特征空间中的搜索问题。比如:随机爬山法,启发式的搜索方法等。
- 嵌入方法:将特征选择的过程嵌入到模型训练的过程中,其实也就是正则化的方法。比如lasso回归,岭回归,弹性网络(Elastic Net)等。
具体其它细节,以后补充。
推荐一篇美团网的技术报告:
机器学习中的数据清洗与特征处理综述
还有一篇参考:
机器学习中的特征选择问题
最后一篇特征选择的好文:
A introduction on feature seclection
1 数据不平衡问题
这个问题是经常遇到的。就拿有监督的学习的二分类问题来说吧,我们需要正例和负例样本的标注。如果我们拿到的训练数据正例很少负例很多,那么直接拿来做分类肯定是不行的。通常需要做以下方案处理:1.1 数据集角度
通过调整数据集中正负样本的比例来解决数据不平衡,方法有:1.1.1 增加正样本数量
正样本本来就少,怎么增加呢?方法是直接复制已有的正样本丢进训练集。这样可以稍微缓解正样本缺失的困境,但是容易带来一个问题,就是过拟合的潜在危险。因为这样粗暴的引入正样本并没有增加数据集的样本多样性。如何设计复制哪些正样本有一些技巧,比如选择有特定意义的代表性的那些。1.1.2 减少负样本的数量
首先这是一个通用的合理的方法,但是负样本的减少必然导致数据多样性的损失。有一种方法可以缓解这个问题,那就是类似于随机森林方法,每次正样本数量不变,随机选择等量的不同的负样本进行模型训练,反复几次,训练多个模型,最后所有的模型投票决定最终的分类结果。1.2 损失函数的角度
可以重新修改模型训练的损失函数,使得错分正样本的损失变大,错分负样本的损失变小。这样训练出来的模型就会对正负样本有一个合理的判断。更多于此话题相关内容请移步:
分类中数据不平衡问题的解决经验
机器学习中的数据不平衡问题
2 异常值处理问题
说到异常值,首先得说一下数据量的问题。异常值不是缺失值,更不是错误值,同样是真实情况的表现,之所以觉得一个数据异常,是因为我们能够用到的数据量不够大,无法准确地代表整个此类数据的分布。如果把异常值放在海量数据的大背景下,那么这个异常值也就不那么异常了。下载摘自某大牛博客一段话:
异常值并非错误值,而同样是真实情况的表现,我们之所以认为异常,只是因为我们的数据量不足够大而已。但是从实际的工业界来看,考虑到实际的计算能力以及效果,大多数公司都会对大数据做“去噪”,那么在去噪的过程中去除的不仅仅是噪音,也包括“异常点”,而这些“异常点”,恰恰把大数据的广覆盖度给降低了,于是利用大数据反而比小数据更容易产生趋同的现象。尤其对于推荐系统来说,这些“异常点”的观察其实才是“个性化”的极致。
既然说到大数据,同样是这位大牛的一段话:
说得学术一些,我们不妨认为大数据是频率学派对于贝叶斯学派一次强有力的逆袭。那么既然说到这个份上了,我们不妨思考一下,我们是不是有希望在回归贝叶斯学派,利用先验信息+小数据完成对大数据的反击呢?
某些机器学习算法对异常值很敏感,比如:K-means聚类,AdaBoost。使用此类算法必须处理异常值。
某些算法拥有对异常值不敏感的特性,比如:KNN,随机森林。
如何处理异常值?最简单的方法就是直接丢掉。其它方法我后面会继续研究。
3 过拟合问题
过拟合可要命了,好不容易训练一个模型,来一些测试数据,分类结果非常的差。过拟合产生的原因:训练数据太少
模型太复杂
训练数据中存在噪声点(就算训练数据足够多)
几乎所有的机器学习算法都会容易遇到过拟合的问题。所以先说一些解决过拟合的通用办法。当然,首先得保证训练数据不要太少。
3.1 正则化
正则化就是在模型的优化目标上再加入一个惩罚因子。这样模型的优化策略就从经验风险最小化变为结构风险最小化。线性回归正则化就是岭回归和lasso回归,分别对应L2,L1罚项。
决策树正则化就是剪枝,通常把子节点个数作为罚项。
3.2 交叉验证
在数据量足够的情况下,可以采用交叉验证的方式避免过拟合,甚至可以在正则化之后再做一次交叉验证。其它详细研究请点击:
机器学习过度拟合问题一些原因
4 特征工程问题
有句话必须得放在前面:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程尤其是特征选择在机器学习中占有相当重要的地位。4.1 什么是特征工程
首先拽一段英文定义:Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
in a word, feature engineering is manually designing what the input x’s should be.
4.2 为什么要进行特征降维和特征选择
主要是出于如下考虑:1. 特征维数越高,模型越容易过拟合,此时更复杂的模型就不好用。
2. 相互独立的特征维数越高,在模型不变的情况下,在测试集上达到相同的效果表现所需要的训练样本的数目就越大。
3. 特征数量增加带来的训练、测试以及存储的开销都会增大。
4. 在某些模型中,例如基于距离计算的模型KMeans,KNN等模型,在进行距离计算时,维度过高会影响精度和性能。
5. 可视化分析的需要。在低维的情况下,例如二维,三维,我们可以把数据绘制出来,可视化地看到数据。当维度增高时,就难以绘制出来了。
在机器学习中,有一个非常经典的维度灾难的概念。用来描述当空间维度增加时,分析和组织高维空间,因体积指数增加而遇到各种问题场景。例如,100个平均分布的点能把一个单位区间以每个点距离不超过0.01采样;而当维度增加到10后,如果以相邻点距离不超过0.01小方格采样单位超一单位超正方体,则需要10^20 个采样点。
正是由于高维特征有如上描述的各种各样的问题,所以我们需要进行特征降维和特征选择等工作。
4.3 特征提取
对于高维特征(成百上千维),比如图像,文本,声音的特征,特征的每一维没有显著意义的,最好要对特征先进行降维,也就是从初始数据中提取有用的信息。通过降维,将高维空间中的数据集映射到低维空间数据,同时尽可能少地丢失信息,或者降维后的数据点尽可能地容易被区分。这样,可以提取出显著特征,避免维度灾难,还可以避免特征之间的线性相关性。特征降维常用的算法有PCA,LDA等。
PCA算法通过协方差矩阵的特征值分解能够得到数据的主成分,以二维特征为例,两个特征之间可能存在线性关系(例如运动的时速和秒速度),这样就造成了第二维信息是冗余的。PCA的目标是发现这种特征之间的线性关系,并去除。
LDA算法考虑label,降维后的数据点尽可能地容易被区分。
4.4 特征选择
通常遇到的情况是:特征不够用。。在这种情况下,我们就要在设计算法之前,好好地挖掘一下特征。对于逻辑斯蒂回归和决策树,每一维的特征是有确切意义的。我们就要从各个方面,抽取与目标相关的所有可用信息作为特征。这个过程可能会比较痛苦。。然后,是不是特征越多越好?其实也不是。盗一张图过来如下:
可以发现,刚开始模型的准确率随着特征数量的增加而增加,当增加到一定程度便趋于稳定了。如果还要强行加入如此多的特征,反而画蛇添足,容易过拟合。然后,如果出现特征过多出现过拟合的情况,就要适当地进行参数缩减。对于逻辑斯蒂回归,某一维特征对应的参数如果接近为零,说明这个特征影响不大,就可以去掉。因此,我们的特征选择过程一般如下:
选取尽可能多的特征,必要时先进行降维
对特征进行选择,保留最具有代表性的特征
这个过程的进行要同时观察模型准确率的变化。
最后,特征选择有哪些算法呢?
- 过滤方法:将所有特征进行打分评价,选择最有效的一些特征。比如:卡法检验,信息增益,相关系数打分。
- 包装方法:将特征组合的选择看做是一个在特征空间中的搜索问题。比如:随机爬山法,启发式的搜索方法等。
- 嵌入方法:将特征选择的过程嵌入到模型训练的过程中,其实也就是正则化的方法。比如lasso回归,岭回归,弹性网络(Elastic Net)等。
具体其它细节,以后补充。
推荐一篇美团网的技术报告:
机器学习中的数据清洗与特征处理综述
还有一篇参考:
机器学习中的特征选择问题
最后一篇特征选择的好文:
A introduction on feature seclection

相关文章推荐
- 我是运营,我没有假期
- 动易2006序列号破解算法公布
- DB2数据库的安装
- C#实现把指定数据写入串口
- “传奇”图象数据存储方式
- Ruby实现的矩阵连乘算法
- 修复mysql数据库
- C#插入法排序算法实例分析
- SQLServer 数据导入导出的几种方法小结
- MySQL数据备份之mysqldump的使用详解
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- C#实现窗体间传递数据实例
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- 给你的数据库文件减肥
- Oracle数据更改后出错的解决方法
- C#实现的算24点游戏算法实例分析
- C#将Sql数据保存到Excel文件中的方法