用Python进行自然语言处理-2. Accessing Text Corpora and Lexical Resources
2015-07-27 16:59
651 查看
1. 处理文本语料库
1.1 古腾堡语料库
这是一个电子书语料库,目前提供49,000本免费电子书。我们可以看看nltk里集成了多少电子书:
>>> import nltk >>> nltk.corpus.gutenberg.fileids() ['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
我们可以用处理text1…text10的方法去处理。包括len、concordance等等。
我们还可以用raw方法获得所有字符,用words方法获得所有单词,用sents方法获得所有句子。进而可以计算平均词长、平均句长、用词多样性。
>>> for fileid in gutenberg.fileids(): ... num_chars = len(gutenberg.raw(fileid)) [1] ... num_words = len(gutenberg.words(fileid)) ... num_sents = len(gutenberg.sents(fileid)) ... num_vocab = len(set(w.lower() for w in gutenberg.words(fileid))) ... print(round(num_chars/num_words), round(num_words/num_sents), round(num_words/num_vocab), fileid) ... 5 25 26 austen-emma.txt 5 26 17 austen-persuasion.txt 5 28 22 austen-sense.txt 4 34 79 bible-kjv.txt 5 19 5 blake-poems.txt 4 19 14 bryant-stories.txt 4 18 12 burgess-busterbrown.txt 4 20 13 carroll-alice.txt 5 20 12 chesterton-ball.txt 5 23 11 chesterton-brown.txt 5 18 11 chesterton-thursday.txt 4 21 25 edgeworth-parents.txt 5 26 15 melville-moby_dick.txt 5 52 11 milton-paradise.txt 4 12 9 shakespeare-caesar.txt 4 12 8 shakespeare-hamlet.txt 4 12 7 shakespeare-macbeth.txt 5 36 12 whitman-leaves.txt
1.2 网络聊天语料库
从略1.3 布朗语料库
这是一个分类语料库:| ID | File | Genre | Description |
|---|---|---|---|
| A16 | ca16 | news | Chicago Tribune: Society Reportage |
| B02 | cb02 | editorial | Christian Science Monitor: Editorials |
| C17 | cc17 | reviews | Time Magazine: Reviews |
| D12 | cd12 | religion | Underwood: Probing the Ethics of Realtors |
| E36 | ce36 | hobbies | Norling: Renting a Car in Europe |
| F25 | cf25 | lore | Boroff: Jewish Teenage Culture |
| G22 | cg22 | belles_lettres | Reiner: Coping with Runaway Technology |
| H15 | ch15 | government | US Office of Civil and Defence Mobilization: The Family Fallout Shelter |
| J17 | cj19 | learned | Mosteller: Probability with Statistical Applications |
| K04 | ck04 | fiction | W.E.B. Du Bois: Worlds of Color |
| L13 | cl13 | mystery | Hitchens: Footsteps in the Night |
| M01 | cm01 | science_fiction | Heinlein: Stranger in a Strange Land |
| N14 | cn15 | adventure | Field: Rattlesnake Ridge |
| P12 | cp12 | romance | Callaghan: A Passion in Rome |
| R06 | cr06 | humor | Thurber: The Future, If Any, of Comedy |
>>> from nltk.corpus import brown >>> brown.categories() ['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction'] >>> brown.words(categories='news') ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...] >>> brown.words(fileids=['cg22']) ['Does', 'our', 'society', 'have', 'a', 'runaway', ',', ...] >>> brown.sents(categories=['news', 'editorial', 'reviews']) [['The', 'Fulton', 'County'...], ['The', 'jury', 'further'...], ...]
利用布朗语料库我们可以研究不同文体之间的风格差异。比如,我们可以比较不同文体的情态动词的差异,这里用到了tabulate方法制作表格,也用到了条件概率分布方法ConditionalFreqDist获得不同文体的概率分布:
>>> cfd = nltk.ConditionalFreqDist( ... (genre, word) ... for genre in brown.categories() ... for word in brown.words(categories=genre)) >>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor'] >>> modals = ['can', 'could', 'may', 'might', 'must', 'will'] >>> cfd.tabulate(conditions=genres, samples=modals) can could may might must will news 93 86 66 38 50 389 religion 82 59 78 12 54 71 hobbies 268 58 131 22 83 264 science_fiction 16 49 4 12 8 16 romance 74 193 11 51 45 43 humor 16 30 8 8 9 13
1.4 路透社语料库
方法同布朗语料库1.5 总统就职演讲语料库
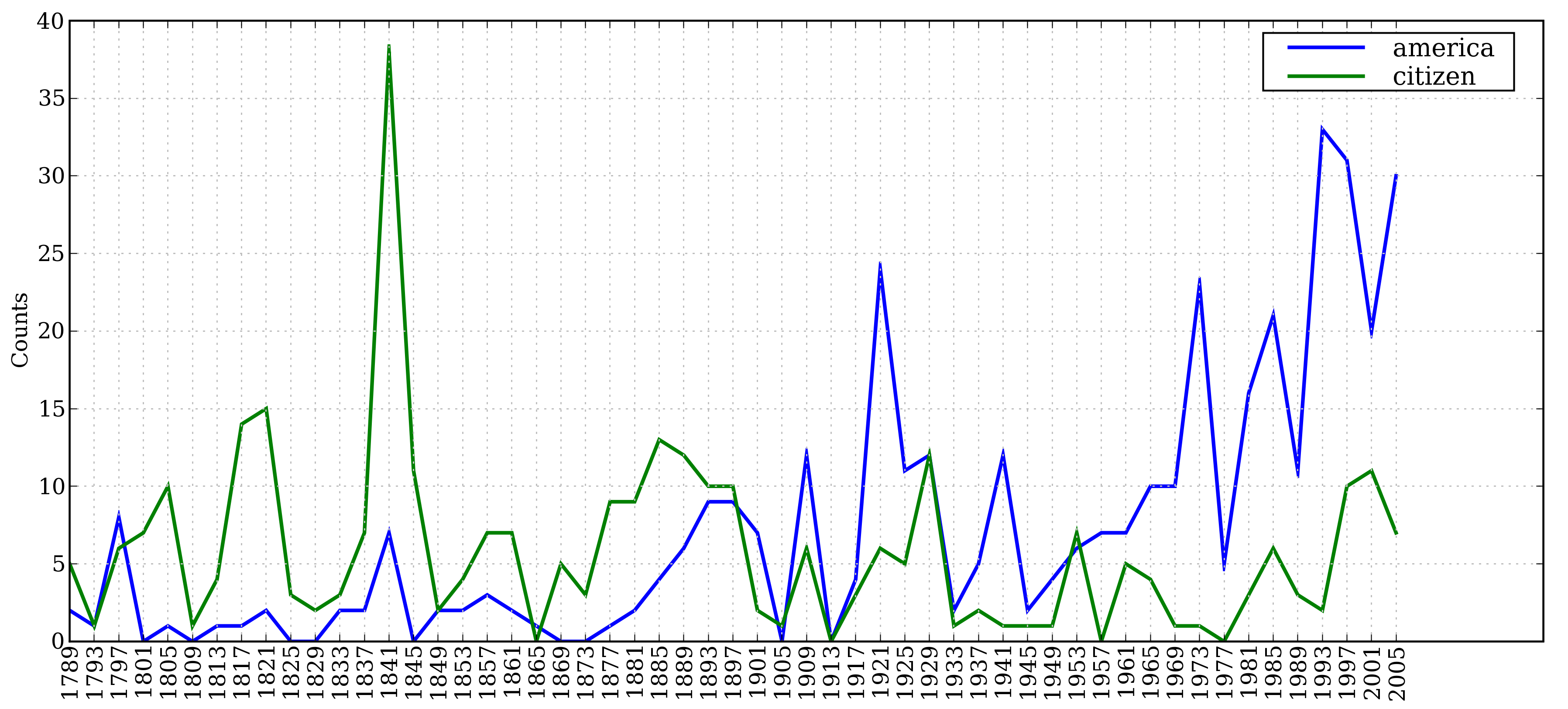
>>> from nltk.corpus import inaugural >>> inaugural.fileids() ['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', ...] >>> [fileid[:4] for fileid in inaugural.fileids()] ['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', ...]
根据文件名以“年份-总统名”命名的特点,我们可以计算不同时期,某些词的频度分布:
>>> cfd = nltk.ConditionalFreqDist( ... (target, fileid[:4]) ... for fileid in inaugural.fileids() ... for w in inaugural.words(fileid) ... for target in ['america', 'citizen'] ... if w.lower().startswith(target)) [1] >>> cfd.plot()

相关文章推荐
- python中string的操作函数
- SVN弱密码扫描(Python)
- django-mysql 中的金钱计算事务处理 分类: 小技巧 python学习 mysql 2015-07-27 16:52 10人阅读 评论(0) 收藏
- python学习总结
- 17个新手常见Python运行时错误
- python实现链表
- 在Python的Django框架中创建语言文件
- Vim as Python IDE on windows(转)
- python-re模块-使用案例
- 给Python初学者的一些技巧
- python基础教程总结15——3 XML构建网址
- 用Python进行自然语言处理-1. Language Processing and Python
- python(2.7.10) 安装后启动错误:IDLE's subprocess didn't make connection
- 在Python中的Django框架中进行字符串翻译
- python的copy,总结的很好
- Mac OS X 程序员利器 – Homebrew安装与使用以及python学习指南
- python 多线程中同步的小例子
- python class __slots__
- Logistic回归python代码
- Python正则表达式的七个使用范例