超级小白的scrapy爬虫经历——初章
2015-07-26 13:36
453 查看
打从一个多月前开始用scrapy开始,就没一天顺畅过。。。怎么装就不说了,看链接: http://blog.csdn.net/playstudy/article/details/17296473。
需要注意的地方就是widows、python和各个包之间的对应(我前前后装了3次也是醉了)。我的scrapy是1.0.0版的,python2.7 。
(1)然后就是第一个坎了,scrapy startproject xxx,呵呵,报错了>_<,IOERR!。

没有setting.py.tmpl,那么这个文件本来应该放哪呢??答案是
\Lib\site-packages\scrapy\templates\project\module(用google搜setting.py.tmpl)
打开看了一下,果然里面没有,用python新建一个文件,命名为setting.py.tmpl放到那个文件夹下就可以了,pipelines.py.tmpl和items.py.tmpl也一样,这三个文件的内容google可以搜到。都搞定之后,就可以start your first spider。
(2)我的spider要实现的内容非常简单,就是提取网页内容和自动多页爬取,完全没有对settings和pipelines的修改。要爬的网站是http://www.xici.net.co/wn/1,第一步就是在items.py里定义item了,这是代码:
要的东西只有三个,Ipadress、Port和Type。下一步就是编写spider了,取个名字,限制一下爬取的域名,把要爬的第一个网页链接放到start_urls里。
接下来就是用xpath从网页上提出这三个毛毛,但是xpath怎么用,因为我是超级小白啊!!?
看教程:
http://www.w3school.com.cn/xpath/
最起码把xpath语法和xpath实例看了,但是还不够。
还得会用scrapy shell +url测试xpath路径是否可用
(我看教程里没有提scrapy shell,凄惨的经历就不说了…),
用scrapy shell http://www.xici.net.co/wn/1测试
(路径需要用到浏览器的审查元素功能,貌似不同浏览器开启方法不一样,chrome按F12就可以了),输出结果是这个样子的:
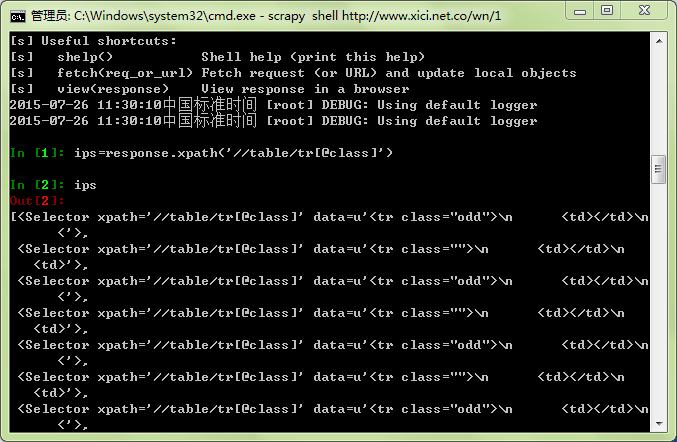
可以看到这是一个由路径组成的列表,然后对这个列表循环就能提取出每条代理的那三个信息,要注意的地方就是循环时用相对路径‘td[3]/text()’就可以了,就是:
你也可以试一下‘//td[3]/text()’和‘/td[3]/text()’,然后后者是错的,要是不知道原因可以再看一下xpath语法。到此为止,spider的第一部分就完成了,这时候它可以爬取单页上的内容了。
(3)怎么多页爬取,怎么跟进,利用Rule的那个方法完全没看懂(超级小白>…<),Request的方法麻烦一点但是很好理解。先看一下scrapy 1.0.0的documentation,链接:http://doc.scrapy.org/en/latest/。里面对scrapy.http.Request()介绍得很详细,参数很多,但这里只用到两个就行了,url和callback。
要爬的页面的链接的前半部分长得都像这个样子:http://www.xici.net.co/wn/,后面跟一个整数。利用审查元素看到“下一页”的超链接只有“wn/2”,其他的链接也只有一部分,超级小白在这里又不知所措了>…<,然而处理方法特别特别简单,链接不全补上去就行了(那么努力的看教程,都看到猪身上去了…)。
为了防止重复爬取,把爬过的页面记录下来就可以了(这里得吐槽一下,明明写的有131页,爬了之后发现只有10页的链接是可用的,我还以为是程序的问题,在网站试了一下就是翻不到第11页…),接下来就是多页爬取最最关键的地方了,
在yield语句里,callback回调函数,意思就是用parse方法解析url这个页面。
yield相关知识,链接:
http://blog.csdn.net/preterhuman_peak/article/details/40615201
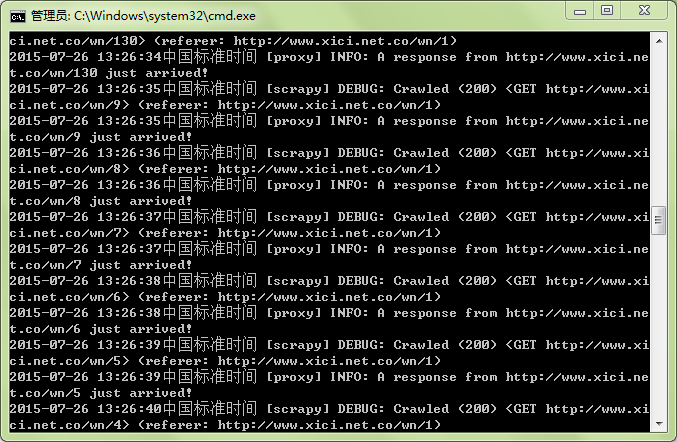
到此,用scrapy实现的最简单的多页爬取就完成了。这是部分运行结果:
致谢:感谢文中链接所指文章的各位博主,^_^
需要注意的地方就是widows、python和各个包之间的对应(我前前后装了3次也是醉了)。我的scrapy是1.0.0版的,python2.7 。
(1)然后就是第一个坎了,scrapy startproject xxx,呵呵,报错了>_<,IOERR!。
没有setting.py.tmpl,那么这个文件本来应该放哪呢??答案是
\Lib\site-packages\scrapy\templates\project\module(用google搜setting.py.tmpl)
打开看了一下,果然里面没有,用python新建一个文件,命名为setting.py.tmpl放到那个文件夹下就可以了,pipelines.py.tmpl和items.py.tmpl也一样,这三个文件的内容google可以搜到。都搞定之后,就可以start your first spider。
(2)我的spider要实现的内容非常简单,就是提取网页内容和自动多页爬取,完全没有对settings和pipelines的修改。要爬的网站是http://www.xici.net.co/wn/1,第一步就是在items.py里定义item了,这是代码:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class MyproxyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Ipadress=scrapy.Field() Port=scrapy.Field() Type=scrapy.Field()
要的东西只有三个,Ipadress、Port和Type。下一步就是编写spider了,取个名字,限制一下爬取的域名,把要爬的第一个网页链接放到start_urls里。
from scrapy.spiders import Spider,Rule from scrapy.selector import Selector from myProxy.items import MyproxyItem from scrapy.linkextractors import LinkExtractor from scrapy.http import Request import re
class ProxySpider(Spider): name = "proxy" allowed_domains = ["www.xici.net.co"] start_urls = ["http://www.xici.net.co/wn/1",]
接下来就是用xpath从网页上提出这三个毛毛,但是xpath怎么用,因为我是超级小白啊!!?
看教程:
http://www.w3school.com.cn/xpath/
最起码把xpath语法和xpath实例看了,但是还不够。
还得会用scrapy shell +url测试xpath路径是否可用
(我看教程里没有提scrapy shell,凄惨的经历就不说了…),
用scrapy shell http://www.xici.net.co/wn/1测试
response.xpath('//table/tr[@class]')(路径需要用到浏览器的审查元素功能,貌似不同浏览器开启方法不一样,chrome按F12就可以了),输出结果是这个样子的:
可以看到这是一个由路径组成的列表,然后对这个列表循环就能提取出每条代理的那三个信息,要注意的地方就是循环时用相对路径‘td[3]/text()’就可以了,就是:
sites=response.xpath('//table/tr[@class]')
item=MyproxyItem()
for site in sites:
item['Ipadress']=site.xpath('td[3]/text()').extract()[0]
item['Port']=site.xpath('td[4]/text()').extract()[0]
item['Type']=site.xpath('td[7]/text()').extract()[0]你也可以试一下‘//td[3]/text()’和‘/td[3]/text()’,然后后者是错的,要是不知道原因可以再看一下xpath语法。到此为止,spider的第一部分就完成了,这时候它可以爬取单页上的内容了。
(3)怎么多页爬取,怎么跟进,利用Rule的那个方法完全没看懂(超级小白>…<),Request的方法麻烦一点但是很好理解。先看一下scrapy 1.0.0的documentation,链接:http://doc.scrapy.org/en/latest/。里面对scrapy.http.Request()介绍得很详细,参数很多,但这里只用到两个就行了,url和callback。
要爬的页面的链接的前半部分长得都像这个样子:http://www.xici.net.co/wn/,后面跟一个整数。利用审查元素看到“下一页”的超链接只有“wn/2”,其他的链接也只有一部分,超级小白在这里又不知所措了>…<,然而处理方法特别特别简单,链接不全补上去就行了(那么努力的看教程,都看到猪身上去了…)。
urls=response.xpath('//div[@class="pagination"]/a/@href').extract()#提取链接部分
urls=["http://www.xici.net.co"+url0 for url0 in urls]#补全链接为了防止重复爬取,把爬过的页面记录下来就可以了(这里得吐槽一下,明明写的有131页,爬了之后发现只有10页的链接是可用的,我还以为是程序的问题,在网站试了一下就是翻不到第11页…),接下来就是多页爬取最最关键的地方了,
for url in urls: if url not in urllist: urllist.append(url)#爬过的链接列表 print url#测试用 yield Request(url,callback=self.parse)#跟进
在yield语句里,callback回调函数,意思就是用parse方法解析url这个页面。
yield相关知识,链接:
http://blog.csdn.net/preterhuman_peak/article/details/40615201
到此,用scrapy实现的最简单的多页爬取就完成了。这是部分运行结果:
致谢:感谢文中链接所指文章的各位博主,^_^

相关文章推荐
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- python使用scrapy解析js示例
- Python基于scrapy采集数据时使用代理服务器的方法
- 使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
- Python打印scrapy蜘蛛抓取树结构的方法
- Python实现在线程里运行scrapy的方法
- Python使用scrapy采集时伪装成HTTP/1.1的方法
- Python使用Scrapy爬取妹子图
- 基于scrapy实现的简单蜘蛛采集程序
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- Python使用scrapy采集数据时为每个请求随机分配user-agent的方法
- Python自定义scrapy中间模块避免重复采集的方法
- 在Linux系统上安装Python的Scrapy框架的教程
- Python使用scrapy采集数据过程中放回下载过大页面的方法
- Python实现从脚本里运行scrapy的方法
- Python使用scrapy抓取网站sitemap信息的方法
- 零基础写python爬虫之爬虫框架Scrapy安装配置
- Python+Scrapy安装