第十章 Call 和 Ret 指令
2015-07-26 10:23
316 查看
10.1 ret 和 retf
call和ret 指令都是转移指令,它们都修改IP,或同时修改CS和IP。
它们经常被共同用来实现自程序的设计。
这一章,我们讲解call和ret 指令的原理。
(一)ret指令用栈中的数据,修改IP的内容,从而实现近转移!
CPU执行ret指令时,进行下面两步操作:
(1)(IP)=((ss)*16+(sp))
(2)(sp)=(sp)+2
(二)retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移;
CPU执行retf指令时,进行下面两步操作:
(1)(IP)=((ss)16+(sp))
(2)(sp)=(sp)+2
(3)(CS)=((ss)16+(sp))
(4)(sp)=(sp)+2
可以看出,如果我们用汇编语法来解释ret和retf指令,则:
CPU执行ret指令时,相当于进行:
pop IP
CPU执行retf指令时,相当于进行:
pop IP
pop CS
---------------------------------------------------------------
分析源码
assume cs:codesg
stack segment
db 16 dup (0)
stack ends
codesg segment
mov ax,4c00h
int 21h
start:
mov ax,stack
mov ss,ax
mov sp,16
mov ax,0
codesg ends
end start
ret指令
程序中ret指令执行后,(IP)=0,CS:IP指向代码段的第一条指令。
---------------------------------------------------------------------------------------------
assume cs:codesg
stack segment
db 16 dup (0)
stack ends
codesg segment
mov ax,4c00h
int 21h
start:
mov ax,stack
mov ss,ax
mov sp,16
mov ax,0
push cs
push ax
codesg ends
end start
retf指令
程序中retf指令执行后,CS:IP指向代码段的第一条指令。
10.2 call 指令
call指令经常跟ret指令配合使用,因此CPU执行call指令,进行两步操作:
(1)将当前的 IP 或 CS和IP 压入栈中;
(2)转移(jmp)。
call 指令不能实现短转移,除此之外,call指令实现转移的方法和 jmp 指令的原理相同。
下面的几个小节中 ,我们以给出转移目的地址的不同方法为主线,讲解call指令的主要应用格式。
10.3 依据位移进行转移的call指令
call 标号(将当前的 IP 压栈后,转到标号处执行指令)
CPU执行此种格式的call指令时,进行如下的操作:
(1) (sp) = (sp) – 2
((ss)*16+(sp)) = (IP)
(2) (IP) = (IP) + 16位位移
call 标号
16位位移=“标号”处的地址-call指令后的第一个字节的地址;
16位位移的范围为 -32768~32767,用补码表示;
16位位移由编译程序在编译时算出。
演示
从上面的描述中,可以看出,如果我们用汇编语法来解释此种格式的 call指令,则:
CPU 执行指令“call 标号”时,相当于进行:
push IP
jmp near ptr 标号
前面讲解的call指令,其对应的机器指令中并没有转移的目的地址 ,而是相对于当前IP的转移位移。
10.4 转移的目的地址在指令中的call指令
CPU执行“call far ptr 标号”这种格式的call指令时的操作:
(1) (sp) = (sp) – 2
((ss) ×16+(sp)) = (CS)
(sp) = (sp) – 2
((ss) ×16+(sp)) = (IP)
(2) (CS) = 标号所在的段地址
(IP) = 标号所在的偏移地址
从上面的描述中可以看出,如果我们用汇编语法来解释此种格式的 call 指令,则:
CPU 执行指令 “call far ptr 标号” 时,相当于进行:
push CS
push IP
jmp far ptr 标号
-------------------------------------------------------------------------------------------------------
10.5 转移地址在寄存器中的call指令
指令格式:call 16位寄存器
功能:
(sp) = (sp) – 2
((ss)*16+(sp)) = (IP)
(IP) = (16位寄存器)
汇编语法解释此种格式的 call 指令,CPU执行call 16位reg时,相当于进行:
push IP
jmp 16位寄存器
10.6 转移地址在内存中的call指令
转移地址在内存中的call指令有两种格式:
(1) call word ptr 内存单元地址
汇编语法解释:
push IP
jmp word ptr 内存单元地址
比如下面的指令:
mov sp,10h
mov ax,0123h
mov ds:[0],ax
call word ptr ds:[0]
执行后,(IP)=0123H,(sp)=0EH
(2) call dword ptr 内存单元地址
汇编语法解释:
push CS
push IP
jmp dword ptr 内存单元地址(高位字节放CS,低位字节放IP)
比如,下面的指令:
mov sp,10h
mov ax,0123h
mov ds:[0],ax
mov word ptr ds:[2],0
call dword ptr ds:[0]
前面,我们已经分别学习了 ret 和call指令的原理。现在我们看一下,如何将它们配合使用来实现子程序的机制。
assume cs:code
code segment
start: mov ax,1
mov cx,3
call s
mov bx,ax ;(bx) = ?
mov ax,4c00h
int 21h
s: add ax,ax
loop s
ret
code ends
end start
我们来看一下 CPU 执行这个程序的主要过程:
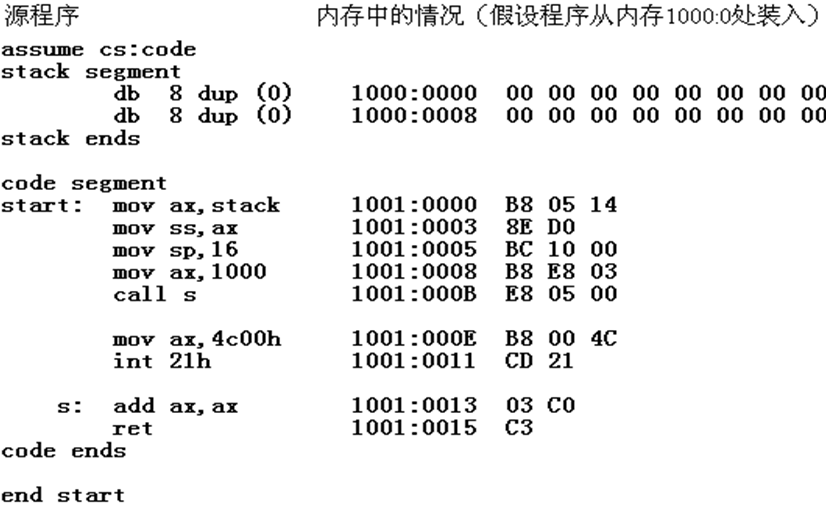
(1)CPU 将call s指令的机器码读入,IP指向了call s后的指令mov bx,ax,然后CPU执行call s指令,将当前的 IP值(指令mov bx,ax的偏移地址)压栈,并将 IP 的值改变为标号 s处的偏移地址;
(2)CPU从标号 s 处开始执行指令,loop循环完毕,(ax)=8;
(3)CPU将ret指令的机器码读入,IP指向了ret 指令后的内存单元,然后CPU 执行 ret 指令 ,从栈中弹出一个值(即 call 先前压入的mov bx,ax 指令的偏移地址)送入 IP 中。则CS:IP指向指令mov bx,ax;
(4)CPU从 mov bx,ax 开始执行指令,直至完成。
因此,程序返回前,(bx)=8 。我们可以看出,从标号s 到ret的程序段的作用是计算2的N次方,计算前,N的值由CX提供。

10.8 mul 指令
因下面要用到,我们介绍一下mul指令,mul是乘法指令,使用 mul 做乘法的时候:
(1)相乘的两个数:要么都是8位,要么都是16位。
8 位: AL中和 8位寄存器或内存字节单元中;
16 位: AX中和 16 位寄存器或内存字单元中。
(2)结果
8位:AX中;
16位:DX(高位)和AX(低位)中。
格式如下:
mul reg
mul 内存单元
内存单元可以用不同的寻址方式给出,比如:
mul byte ptr ds:[0]
含义为: (ax)=(al)((ds)16+0);
mul word ptr [bx+si+8]
含义为:
(ax)=(ax)((ds)16+(bx)+(si)+8)结果的低16位;
(dx)=(ax)((ds)16+(bx)+(si)+8)结果的高16位;
例如:
(1)计算100*10
100和10小于255,可以做8位乘法,程序如下:
mov al,100
mov bl,10
mul bl
又例如:
(2)计算100*10000
100小于255,可10000大于255,所以必须做16位乘法,程序如下:
mov ax,100
mov bx,10000
mul bx
10.9 模块化程序设计
从上面我们看到 ,call 与 ret 指令共同支持了汇编语言编程中的模块化设计。在实际编程中,程序的模块化是必不可少的。
因为现实的问题比较复杂,对现实问题进行分析时,把它转化成为相互联系、不同层次的子问题,是必须的解决方法。
而call和ret 指令对这种分析方法提供了程序实现上的支持。利用 call和ret指令,我们可以用简洁的方法,实现多个互相联系、功能独立的子程序来解决一个复杂的问题。
子程序一般都要根据提供的参数处理一定的事务,处理后,将结果(返回值)提供给调用者。
其实,我们讨论参数和返回值传递的问题,实际上就是在探讨,应该如何存储子程序需要的参数和产生的返回值。
我们设计一个子程序,可以根据提供的N,来计算N的3次方。
这里有两个问题:
(1)我们将参数N存储在什么地方?
(2)计算得到的数值,我们存储在什么地方?
很显然,我们可以用寄存器来存储,可以将参数放到 bx 中 ;
因为子程序中要计算 N×N×N ,可以使用多个 mul 指令,为了方便,可将结果放到 dx 和 ax中。
子程序:
说明:计算N的3次方
参数: (bx)=N
结果: (dx:ax)=N∧3
cube:mov ax,bx
mul bx
mul bx
ret
注意,我们在编程的时候要注意良好的风格,对于程序应有详细的注释。子程序的注释信息应该包含对子程序的功能、参数和结果的说明。
因为今天写的子程序,以后可能还会用到;自己写的子程序,也很可能要给别人使用,所以一定要有全面的注释说明。
用寄存器来存储参数和结果是最常使用的方法。对于存放参数的寄存器和存放结果的寄存器,调用者和子程序的读写操作恰恰相反:
调用者将参数送入参数寄存器,从结果寄存器中取到返回值;
子程序从参数寄存器中取到参数,将返回值送入结果寄存器。
编程:计算data段中第一组数据的 3 次方,结果保存在后面一组dword单元中。
程序:
assume cs:code
data segment
dw 1,2,3,4,5,6,7,8
dd 0,0,0,0,0,0,0,0
data ends
code segment
start:mov ax,data
mov ds,ax
mov si,0 ;ds:si指向第一组word单元
mov di,16 ;ds:di指向第二组dword单元
cube:mov ax,bx
mul bx
mul bx
ret
code ends
end start
--------------------------------------------------------------------------------------------------------------------
10.11 批量数据的传递
前面的例程中,子程序 cube 只有一个参数,放在bx中。如果有两个参数,那么可以用两个寄存器来放,可是如果需要传递的数据有3个、4个或更多直至 N个,我们怎样存放呢?
寄存器的数量终究有限,我们不可能简单地用寄存器来存放多个需要传递的数据。对于返回值,也有同样的问题。
在这种时候,我们将批量数据放到内存中,然后将它们所在内存空间的首地址放在寄存器中,传递给需要的子程序。
对于具有批量数据的返回结果,也可用同样的方法。
编程:将data段中的字符串转化为大写。
assume cs:code
程序如下:
assume cs:code
data segment
db 'conversation'
data ends
code segment
start: mov ax,data
mov ds,ax
mov si,0 ;ds:si指向字符串(批量数据)所在空间的首地址
capital:and byte ptr [si],11011111b
inc si
loop capital
ret
code ends
end start
注意:除了寄存器、内存传递参数外,还有一种通用的方法使用栈来传递参数。关于这种技巧请参看附注4。
10.12 寄存器冲突的问题
设计一个子程序:
功能:将一个全是字母,以0结尾的字符串,转化为大写。
程序要处理的字符串以0作为结尾符,这个字符串可以如下定义:
db ‘conversation’,0
分析分析~
分析
应用这个子程序 ,字符串的内容后面定要有一个0,标记字符串的结束。子程序可以依次读取每个字符进行检测,如果不是0,就进行大写的转化,如果是0,就结束处理。
由于可通过检测0而知道是否己经处理完整个字符串 ,所以子程序可以不需要字符串的长度作为参数。我们可以直接用jcxz来检测0。
子程序的应用
将data段中字符串全部转化为大写
assume cs:code
data segment
db ‘word',0
db ‘unix',0
db ‘wind',0
db ‘good',0
data ends
程序如下:
assume cs:code
data segment
db 'word', 0
db 'unix', 0
db 'wind', 0
db 'good', 0
data ends
code segment
start: mov ax,data
mov ds,ax
mov bx,0
capital:mov cl,[si]
mov ch, 0
jcxz ok
and byte ptr [si], 11011111b
inc si
jmp short capital
ok:ret
code ends
end start
CX应用错误,应该暂存


assume cs:code,ss:stack
stack segment
stack ends
code segment
start:
divdw: ;子程序定义开始
code ends
end start
call和ret 指令都是转移指令,它们都修改IP,或同时修改CS和IP。
它们经常被共同用来实现自程序的设计。
这一章,我们讲解call和ret 指令的原理。
(一)ret指令用栈中的数据,修改IP的内容,从而实现近转移!
CPU执行ret指令时,进行下面两步操作:
(1)(IP)=((ss)*16+(sp))
(2)(sp)=(sp)+2
(二)retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移;
CPU执行retf指令时,进行下面两步操作:
(1)(IP)=((ss)16+(sp))
(2)(sp)=(sp)+2
(3)(CS)=((ss)16+(sp))
(4)(sp)=(sp)+2
可以看出,如果我们用汇编语法来解释ret和retf指令,则:
CPU执行ret指令时,相当于进行:
pop IP
CPU执行retf指令时,相当于进行:
pop IP
pop CS
---------------------------------------------------------------
分析源码
assume cs:codesg
stack segment
db 16 dup (0)
stack ends
codesg segment
mov ax,4c00h
int 21h
start:
mov ax,stack
mov ss,ax
mov sp,16
mov ax,0
push ax mov bx,0 ret
codesg ends
end start
ret指令
程序中ret指令执行后,(IP)=0,CS:IP指向代码段的第一条指令。
---------------------------------------------------------------------------------------------
assume cs:codesg
stack segment
db 16 dup (0)
stack ends
codesg segment
mov ax,4c00h
int 21h
start:
mov ax,stack
mov ss,ax
mov sp,16
mov ax,0
push cs
push ax
mov bx,0 retf
codesg ends
end start
retf指令
程序中retf指令执行后,CS:IP指向代码段的第一条指令。
10.2 call 指令
call指令经常跟ret指令配合使用,因此CPU执行call指令,进行两步操作:
(1)将当前的 IP 或 CS和IP 压入栈中;
(2)转移(jmp)。
call 指令不能实现短转移,除此之外,call指令实现转移的方法和 jmp 指令的原理相同。
下面的几个小节中 ,我们以给出转移目的地址的不同方法为主线,讲解call指令的主要应用格式。
10.3 依据位移进行转移的call指令
call 标号(将当前的 IP 压栈后,转到标号处执行指令)
CPU执行此种格式的call指令时,进行如下的操作:
(1) (sp) = (sp) – 2
((ss)*16+(sp)) = (IP)
(2) (IP) = (IP) + 16位位移
call 标号
16位位移=“标号”处的地址-call指令后的第一个字节的地址;
16位位移的范围为 -32768~32767,用补码表示;
16位位移由编译程序在编译时算出。
演示
从上面的描述中,可以看出,如果我们用汇编语法来解释此种格式的 call指令,则:
CPU 执行指令“call 标号”时,相当于进行:
push IP
jmp near ptr 标号
前面讲解的call指令,其对应的机器指令中并没有转移的目的地址 ,而是相对于当前IP的转移位移。
10.4 转移的目的地址在指令中的call指令
CPU执行“call far ptr 标号”这种格式的call指令时的操作:
(1) (sp) = (sp) – 2
((ss) ×16+(sp)) = (CS)
(sp) = (sp) – 2
((ss) ×16+(sp)) = (IP)
(2) (CS) = 标号所在的段地址
(IP) = 标号所在的偏移地址
从上面的描述中可以看出,如果我们用汇编语法来解释此种格式的 call 指令,则:
CPU 执行指令 “call far ptr 标号” 时,相当于进行:
push CS
push IP
jmp far ptr 标号
-------------------------------------------------------------------------------------------------------
10.5 转移地址在寄存器中的call指令
指令格式:call 16位寄存器
功能:
(sp) = (sp) – 2
((ss)*16+(sp)) = (IP)
(IP) = (16位寄存器)
汇编语法解释此种格式的 call 指令,CPU执行call 16位reg时,相当于进行:
push IP
jmp 16位寄存器
10.6 转移地址在内存中的call指令
转移地址在内存中的call指令有两种格式:
(1) call word ptr 内存单元地址
汇编语法解释:
push IP
jmp word ptr 内存单元地址
比如下面的指令:
mov sp,10h
mov ax,0123h
mov ds:[0],ax
call word ptr ds:[0]
执行后,(IP)=0123H,(sp)=0EH
(2) call dword ptr 内存单元地址
汇编语法解释:
push CS
push IP
jmp dword ptr 内存单元地址(高位字节放CS,低位字节放IP)
比如,下面的指令:
mov sp,10h
mov ax,0123h
mov ds:[0],ax
mov word ptr ds:[2],0
call dword ptr ds:[0]
执行后,(CS)=0,(IP)=0123H,(sp)=0CH
10.7 call 和 ret 的配合使用前面,我们已经分别学习了 ret 和call指令的原理。现在我们看一下,如何将它们配合使用来实现子程序的机制。
assume cs:code
code segment
start: mov ax,1
mov cx,3
call s
mov bx,ax ;(bx) = ?
mov ax,4c00h
int 21h
s: add ax,ax
loop s
ret
code ends
end start
我们来看一下 CPU 执行这个程序的主要过程:
(1)CPU 将call s指令的机器码读入,IP指向了call s后的指令mov bx,ax,然后CPU执行call s指令,将当前的 IP值(指令mov bx,ax的偏移地址)压栈,并将 IP 的值改变为标号 s处的偏移地址;
(2)CPU从标号 s 处开始执行指令,loop循环完毕,(ax)=8;
(3)CPU将ret指令的机器码读入,IP指向了ret 指令后的内存单元,然后CPU 执行 ret 指令 ,从栈中弹出一个值(即 call 先前压入的mov bx,ax 指令的偏移地址)送入 IP 中。则CS:IP指向指令mov bx,ax;
(4)CPU从 mov bx,ax 开始执行指令,直至完成。
因此,程序返回前,(bx)=8 。我们可以看出,从标号s 到ret的程序段的作用是计算2的N次方,计算前,N的值由CX提供。
10.8 mul 指令
因下面要用到,我们介绍一下mul指令,mul是乘法指令,使用 mul 做乘法的时候:
(1)相乘的两个数:要么都是8位,要么都是16位。
8 位: AL中和 8位寄存器或内存字节单元中;
16 位: AX中和 16 位寄存器或内存字单元中。
(2)结果
8位:AX中;
16位:DX(高位)和AX(低位)中。
格式如下:
mul reg
mul 内存单元
内存单元可以用不同的寻址方式给出,比如:
mul byte ptr ds:[0]
含义为: (ax)=(al)((ds)16+0);
mul word ptr [bx+si+8]
含义为:
(ax)=(ax)((ds)16+(bx)+(si)+8)结果的低16位;
(dx)=(ax)((ds)16+(bx)+(si)+8)结果的高16位;
例如:
(1)计算100*10
100和10小于255,可以做8位乘法,程序如下:
mov al,100
mov bl,10
mul bl
结果: (ax)=1000(03E8H)
又例如:
(2)计算100*10000
100小于255,可10000大于255,所以必须做16位乘法,程序如下:
mov ax,100
mov bx,10000
mul bx
结果: (ax)=4240H,(dx)=000FH (F4240H=1000000)
10.9 模块化程序设计
从上面我们看到 ,call 与 ret 指令共同支持了汇编语言编程中的模块化设计。在实际编程中,程序的模块化是必不可少的。
因为现实的问题比较复杂,对现实问题进行分析时,把它转化成为相互联系、不同层次的子问题,是必须的解决方法。
而call和ret 指令对这种分析方法提供了程序实现上的支持。利用 call和ret指令,我们可以用简洁的方法,实现多个互相联系、功能独立的子程序来解决一个复杂的问题。
下面的内容中,我们来看一下子程序设计中的相关问题和解决方法。
10.10 参数和结果传递的问题子程序一般都要根据提供的参数处理一定的事务,处理后,将结果(返回值)提供给调用者。
其实,我们讨论参数和返回值传递的问题,实际上就是在探讨,应该如何存储子程序需要的参数和产生的返回值。
我们设计一个子程序,可以根据提供的N,来计算N的3次方。
这里有两个问题:
(1)我们将参数N存储在什么地方?
(2)计算得到的数值,我们存储在什么地方?
很显然,我们可以用寄存器来存储,可以将参数放到 bx 中 ;
因为子程序中要计算 N×N×N ,可以使用多个 mul 指令,为了方便,可将结果放到 dx 和 ax中。
子程序:
说明:计算N的3次方
参数: (bx)=N
结果: (dx:ax)=N∧3
cube:mov ax,bx
mul bx
mul bx
ret
注意,我们在编程的时候要注意良好的风格,对于程序应有详细的注释。子程序的注释信息应该包含对子程序的功能、参数和结果的说明。
因为今天写的子程序,以后可能还会用到;自己写的子程序,也很可能要给别人使用,所以一定要有全面的注释说明。
用寄存器来存储参数和结果是最常使用的方法。对于存放参数的寄存器和存放结果的寄存器,调用者和子程序的读写操作恰恰相反:
调用者将参数送入参数寄存器,从结果寄存器中取到返回值;
子程序从参数寄存器中取到参数,将返回值送入结果寄存器。
编程:计算data段中第一组数据的 3 次方,结果保存在后面一组dword单元中。
data segment dw 1,2,3,4,5,6,7,8 dd 0,0,0,0,0,0,0,0 data ends
程序:
assume cs:code
data segment
dw 1,2,3,4,5,6,7,8
dd 0,0,0,0,0,0,0,0
data ends
code segment
start:mov ax,data
mov ds,ax
mov si,0 ;ds:si指向第一组word单元
mov di,16 ;ds:di指向第二组dword单元
mov cx,8 s:mov bx,[si] call cube mov [di],ax mov [di].2,dx add si,2 ;ds:si指向下一个word单元 add di,4 ;ds:di指向下一个dword单元 loop s mov ax,4c00h int 21h
cube:mov ax,bx
mul bx
mul bx
ret
code ends
end start
--------------------------------------------------------------------------------------------------------------------
10.11 批量数据的传递
前面的例程中,子程序 cube 只有一个参数,放在bx中。如果有两个参数,那么可以用两个寄存器来放,可是如果需要传递的数据有3个、4个或更多直至 N个,我们怎样存放呢?
寄存器的数量终究有限,我们不可能简单地用寄存器来存放多个需要传递的数据。对于返回值,也有同样的问题。
在这种时候,我们将批量数据放到内存中,然后将它们所在内存空间的首地址放在寄存器中,传递给需要的子程序。
对于具有批量数据的返回结果,也可用同样的方法。
编程:将data段中的字符串转化为大写。
assume cs:code
data segment db 'conversation' data ends code segment start: …… code ends end start
程序如下:
assume cs:code
data segment
db 'conversation'
data ends
code segment
start: mov ax,data
mov ds,ax
mov si,0 ;ds:si指向字符串(批量数据)所在空间的首地址
mov cx,12 ;cx存放字符串的长度 call capital mov ax,4c00h int 21h
capital:and byte ptr [si],11011111b
inc si
loop capital
ret
code ends
end start
注意:除了寄存器、内存传递参数外,还有一种通用的方法使用栈来传递参数。关于这种技巧请参看附注4。
10.12 寄存器冲突的问题
设计一个子程序:
功能:将一个全是字母,以0结尾的字符串,转化为大写。
程序要处理的字符串以0作为结尾符,这个字符串可以如下定义:
db ‘conversation’,0
分析分析~
分析
应用这个子程序 ,字符串的内容后面定要有一个0,标记字符串的结束。子程序可以依次读取每个字符进行检测,如果不是0,就进行大写的转化,如果是0,就结束处理。
由于可通过检测0而知道是否己经处理完整个字符串 ,所以子程序可以不需要字符串的长度作为参数。我们可以直接用jcxz来检测0。
子程序的应用
将data段中字符串全部转化为大写
assume cs:code
data segment
db ‘word',0
db ‘unix',0
db ‘wind',0
db ‘good',0
data ends
程序如下:
assume cs:code
data segment
db 'word', 0
db 'unix', 0
db 'wind', 0
db 'good', 0
data ends
code segment
start: mov ax,data
mov ds,ax
mov bx,0
mov cx,4 s: mov si,bx call capital add bx,5 loop s mov ax,4c00h int 21h
capital:mov cl,[si]
mov ch, 0
jcxz ok
and byte ptr [si], 11011111b
inc si
jmp short capital
ok:ret
code ends
end start
CX应用错误,应该暂存
assume cs:code,ss:stack
stack segment
dw 8 dup(0)
stack ends
code segment
start:
mov ax,stack mov ss,ax mov sp,10h mov ax,4240h mov dx,0fh mov cx,0ah call divdw mov ax,4c00h int 21h
divdw: ;子程序定义开始
push ax ;低16位先保存 mov ax,dx ;ax这时候的值是高16位了 mov dx,0 ;dx置0是为了不影响下边余数位,使得高16位为0 div cx ;H/N mov bx,ax ;ax,bx的值为(int)H/N ,dx的值为(rem)H/N pop ax ;ax的值现在是L div cx ;L/N,注意,16位除法的时候默认被除数DX为高16位,AX为低16位 mov cx,dx mov dx,bx ret ;子程序定义结束
code ends
end start

相关文章推荐
- [LeetCode]Lowest Common Ancestor of a Binary Tree
- 已知中序遍历序列和后序遍历序列,求先序遍历
- UVA 11987 Almost Union-Find (带权并查集的操作及并查集的删除操作)
- 【攻克Android (11)】适配器视图与适配器
- Eclipse开发Android程序如何在手机上运行
- hdu5304 Eastest Magical Day Seep Group's Summer 状压dp+生成树
- BestCoder 1st Anniversary
- LeetCode(54)(59) Spiral Matrix I II
- 操作系统内存管理之 内部碎片vs外部碎片
- Python Matplotlib的安装使用及Scipy,numpy,dateutil,pyparsing的安装
- 树莓派的供电问题
- !leetcode[162]:Find Peak Element
- STL学习顺序
- generic_socket_receive_data.hdev socket通信相关例程学习
- 派生关系中的二义性处理
- Unable to read the project file 'client.csproj'. Could not load file or assembly 'Microsoft.Build.En
- leetcode[151]:Reverse Words in a String
- Unable to read the project file 'client.csproj'. Could not load file or assembly 'Microsoft.Build.En
- IT 技术人必须思考的 15 个问题
- Linux多线程与同步