Python-技巧
2015-07-24 15:31
232 查看
0.推荐的扩展
requests urilib的替代品
BeautifulSoup4 解析HTML代码
rq 任务队列
selenium 自动化测试工具,模拟浏览器
1.sys.modules, 根据已加载的模块创建对象, 其中 page 为类名
2.hasattr, setattr, locals(), globals() 动态创建变量
3.绑定、未绑定
未绑定的类方法: 没有self
通过类来引用方法返回一个未绑定方法对象, 要调用它, 你必须显示地提供一个实例作为第一个参数
绑定的实例方法: 有self
通过实例访问方法返回一个绑定的方法对象, Python自动地给方法绑定一个实例, 所以我们调用它时不用再传一个实例参数
object1 = Test()生成一个实例, object1.func返回一个绑定的方法, 把实例object1和方法func绑定, 而Test.func是用类去引用方法, 我们得到一个未绑定的方法对象, 要调用它就得传一个实例参数, 如t(object1,'未绑定的方法对象,需要传递一个实例')
4.MRO(method resolution order, 多继承时判断调的属性的类)
MRO要先确定一个线性序列, 然后查找路径由由序列中类的顺序决定, 所以MRO的算法就是生成一个线性序列
Python先后有三种不同的MRO: 经典方式、Python2.2 新式算法、Python2.3 新式算法(C3), Python 3中只保留了最后一种, 即C3算法
经典方式: 非常简单, 深度优先, 按定义从左到右
新式算法: 还是经典方式, 但出现重复的, 只保留最后一个
C3算法: 最早被提出是用于Lisp的, 应用在Python中是为了解决原来基于深度优先搜索算法不满足本地优先级, 和单调性的问题:
本地优先级: 指声明时父类的顺序, 比如C(A, B), 如果访问C类对象属性时, 应该根据声明顺序, 优先查找A类, 然后再查找B类
单调性: 如果在C的解析顺序中, A排在B的前面, 那么在C的所有子类里, 也必须满足这个顺序
class B(A) 这时B的mro序列为[B,A]
class B(A1,A2,A3 ...) 这时B的mro序列 mro(B) = + merge(mro(A1), mro(A2), mro(A3) ..., [A1,A2,A3])
merge操作就是C3算法的核心, 遍历执行merge操作的序列, 如果一个序列的第一个元素, 是其他序列中的第一个元素, 或不在其他序列出现, 则从所有执行merge操作序列中删除这个元素, 合并到当前的mro中, merge操作后的序列, 继续执行merge操作, 直到merge操作的序列为空, 如果merge操作的序列无法为空, 则说明不合法
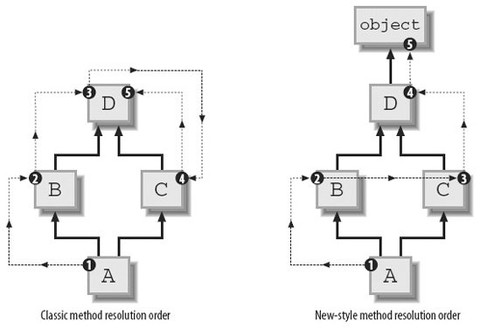
比如此菱形继承结构
按经典方式, d类MRO为dbaca, 缺点是如果c类重写了a类中得方法, c类的方法将不会被调用到(即本地优先顺序问题)
按新式算法, d类MRO为dbca, 缺点是单调性, 比如d继承b、c, 且b在c的前面, 如果f继承d, 那么f的MRO中也应该和d的一样b在c的前面, 单调性即继承时要保持顺序, 现在e继承c、b, 且c在b的前面, f继承d, e时, bc的顺序就没法决定了, 无论怎样排都违反了单调性
按C3算法, A、B、C都继承至一个基类, 所以mro序列依次为[A,O]、[B,O]、[C,O]
mro(E) = [E] + merge(mro(A), mro(B), [A,B])
= [E] + merge([A,O], [B,O], [A,B])
此时需要执行merge操作的序列为[A,O]、[B,O]、[A,B]
A是序列[A,O]中的第一个元素, 在序列[B,O]中不出现, 在序列[A,B]中也是第一个元素, 所以从执行merge操作的序列([A,O]、[B,O]、[A,B])中删除A, 合并到当前mro, [E]中
mro(E) = [E,A] + merge([O], [B,O], [B])
再执行merge操作, O是序列[O]中的第一个元素, 但O在序列[B,O]中出现并且不是其中第一个元素, 继续查看[B,O]的第一个元素B, B满足条件, 所以从执行merge操作的序列中删除B, 合并到[E, A]中
mro(E) = [E,A,B] + merge([O], [O])
= [E,A,B,O]
实现C3算法的代码:
查看一个类的MRO列表, 可以使用 classname.__mro__
5.super 避免多次调用基类
1). super并不是一个函数, 是一个类名, 形如super(B, self)事实上调用了super类的初始化函数产生了一个super对象;
2). super类的初始化函数并没有做什么特殊的操作, 只是简单记录了类类型和具体实例;
3). super(B, self).func的调用并不是用于调用当前类的父类的func函数;
4). Python的多继承类是通过mro的方式来保证各个父类的函数被逐一调用, 而且保证每个父类函数只调用一次(如果每个类都使用super);
5). 混用super类和非绑定的函数是一个危险行为, 这可能导致应该调用的父类函数没有调用或者一个父类函数被调用多次
6).super并不是像我们想象中一样直接找到当前类的父类, 而是沿着mro顺藤摸瓜
参考:http://blog.csdn.net/johnsonguo/article/details/585193
6.模块即模块对象
7.利用 __new__ 实现单例
8.__new__ 执行顺序
9.判断一个变量是否存在
1).
2).
3).
10.根据类名创建实例, 主要是获得类的 class 对象
1).类名cls为class类型, 直接 cls() 即可
2).类名cls为str类型
如果myclass并不在mymodule的自动导出列表中(__all__), 则必须显式地导入, __import__('mymodule', globals(), locals(), ['myclass'])
11.获取当前模块名
locals()/globals().get("__name__")
12.import, reload, __import__
del sys.modules[modulename] 即可实现 unimport
import 调用的 __import__, 比如 import sys => sys = __import__("sys")
reload 对已经加载的模块进行重新加载, 一般用于原模块有变化等特殊情况, reload前该模块必须已经import过, 但原来已经使用的实例还是会使用旧的模块, 新生产的实例会使用新的模块
__import__, 返回模块实例
13.迭代器
基本原理:
实现了__iter__方法的对象是可迭代的, 实现了next()方法的对象是迭代器(迭代器就是一个有next()方法的对象), 所以iter(实现了__iter__方法的对象)会调用此对象的__iter__方法, 返回一个实现了next()方法的迭代器对象, 不断调用此迭代器对象的next()方法, 实现遍历, 直到遇到StopIteration异常, 使用迭代器一个显而易见的好处就是每次只从对象中读取一条数据, 不会造成内存的过大开销
序列、字典、文件中当使用for x in y的结构时, 其实质就是迭代器, 迭代器是和实际对象绑定在一起的, 所以在使用迭代器时或者上述3者时不能修改可变对象的值, 这会产生错误
迭代器不要求你事先准备好整个迭代过程中所有的元素, 迭代器仅仅在迭代至某个元素时才计算该元素, 而在这之前或之后, 元素可以不存在或者被销毁, 这个特点使得它特别适合用于遍历一些巨大的或是无限的集合, 比如几个G的文件, 或是斐波那契数列等等, 这个特点被称为延迟计算或惰性求值(Lazy evaluation)
创建迭代器的方法: iter(object)和iter(func, sentinel)两种, 一种使用的是序列, 另一种使用类来创建, 迭代器更大的功劳是提供了一个统一的访问集合的接口, 只要是实现了__iter__()方法的对象, 就可以使用迭代器进行访问, 返回一个对象, 这个对象拥有一个next()方法, 这个方法能在恰当的时候抛出StopIteration异常即可
实际为:
字典中, iterkeys(), itervalues(), iteritems() 比 keys(), values(), items() 更省内存
open("test.txt").readlines() 返回的是列表, open("test.txt") 返回的是迭代器
14.生成器
如果一个函数返回的列表非常大, 仅仅创建这个列表就会用完系统所有内存, 因为在我们的观念中函数只有一次返回结果的机会, 因而必须一次返回所有的结果, 此类问题可以用生成器解决
生成器是特定的函数, 允许你返回一个值, 然后“暂停”代码的执行, 稍后恢复, 生成器使用了“延迟计算”, 所以在内存上面更加有效, 生成器函数不能有返回值, 因为 yield 的值就是返回值, 生成器就是一类特殊的迭代器
1).调用生成器函数将返回一个生成器
2).第一次调用生成器的next方法时, 生成器才开始执行生成器函数(而不是构建生成器时), 直到遇到yield时暂停执行(挂起), 并且yield的参数将作为此次next方法的返回值
3).之后每次调用生成器的next方法, 生成器将从上次暂停执行的位置恢复执行生成器函数, 直到再次遇到yield时暂停, 并且同样的, yield的参数将作为next方法的返回值
4).如果当调用next方法时生成器函数结束(遇到空的return语句或是到达函数体末尾), 则这次next方法的调用将抛出StopIteration异常(即for循环的终止条件)
5).生成器函数在每次暂停执行时, 函数体内的所有变量都将被封存(freeze)在生成器中, 并将在恢复执行时还原, 并且类似于闭包, 即使是同一个生成器函数返回的生成器, 封存的变量也是互相独立的, 我们的小例子中并没有用到变量, 所以这里另外定义一个生成器来展示这个特点
看到while True可别太吃惊, 因为生成器可以挂起, 所以是延迟计算的, 无限循环并没有关系, 这个例子中我们定义了一个生成器用于获取斐波那契数列
如果生成器函数调用了return, 或者执行到函数的末尾, 会出现一个StopIteration异常
有一篇好文章:点击进入
15.列表解析器
也可以直接生成 dict
列表解析一次生成一个列表, 所占内存较大
由于返回迭代器时, 并不是在一开始就计算所有的元素, 这样能得到更多的灵活性并且可以避开很多不必要的计算, 所以除非你明确希望返回列表, 否则应该始终使用生成器表达式
可以在Python Shell中试一下一下两个语句的执行时间
或者提供多条for子句进行嵌套循环, 嵌套次序就是for子句的顺序:
同样外部也可以使用 if
16.在Python里, 函数的默认值实在函数定义的时候实例化的, 而不是在调用的时候, 如果在调用函数的时候重写了默认值, 那么这个存储的值就不会被使用, 当你不重写默认值的时候, 那么Python就会让默认值引用存储的值(这个例子里的numbers)
abc(): [9] #第一次执行
abc(): [9, 9] #第二次执行
abc([1, 2]): [1, 2, 9] #第三次执行
abc(): [9, 9, 9] #第四次执行
默认参数最好指向不变对象!
17.当def这个声明执行的时候, Python会静态地从函数的局部作用域里获取信息, 当来到 xxx = yyy 这行的时候(不是执行到这行代码, 而是当Python解释器读到这行代码的时候), 它会把xxx这个变量加入到函数的局部变量列表里
18.__builtin__模块, 在Python启动后、且没有执行程序员所写的任何代码前, Python会首先加载该内建模块到内存, 另外, 该内建模块中的功能可以直接使用, 不用在其前添加内建模块前缀, 导入仅仅是让__builitin__标识符在该作用域内可见
19.from __future__ import xxx, 必须是模块或程序的第一个语句, 此外,'__ future__' 模块中存在的特性最终将成为Python语言标准的一部分, 到那时, 将不再需要使用 '__future__' 模块
20.序列解包
21.最好了解下二进制文件和文本文件的区别以及编码问题, ASCII(固定一个字节)->Unicode(固定两个字节)->UTF-8(变长), 在计算机内存中, 统一使用Unicode编码, 当需要保存到硬盘或者需要传输的时候, 就转换为UTF-8编码, 用记事本编辑的时候, 从文件读取的UTF-8字符被转换为Unicode字符到内存里, 编辑完成后, 保存的时候再把Unicode转换为UTF-8保存到文件, len()函数计算的是str(Unicode编码)的字符数, 如果换成bytes(UTF-8等编码), len()函数就计算字节数:
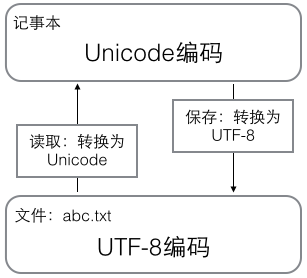
参考自:廖雪峰Python
22.dict的key必须是不可变对象
23.Python函数参数顺序
定义: (arg, kwarg = <value>, *args, **kwargs)
调用:
第一, 按顺序把"arg"这种形式的实参给对应的形参
第二, 把"arg=<value>"这种形式的实参赋值给形式kwarg
第三, 把多出来的"arg"这种形式的实参组成一个tuple给带一个星号的形参args
第四, 把多出来的"key=value"这种形式的实参转为一个dictionary给带两个星号的形参kwargs
24.限制 **kwargs 参数个数
25.functools 模块
wraps: 用来装饰返回func的函数, 以同步func与被装饰的函数的属性, 比如__name__等 @functools.wraps(func)
partial: 变化函数的参数创建偏函数, 固定住原函数的部分参数, 比如 int2 = functools.partial(x, base = 2), 此时 int2 是一个把二进制字符串转为十进制数字的函数, int2('10010')
26.一个.py文件称为一个模块, 为了避免模块名冲突, Python按目录来组织模块的方法, 称为包(Package), 包内必须有__init__.py, 因为__init__.py本身就是一个模块, 它的模块名就是包名(目录名)
27.第三方库都会在 Python 官方的 pypi.python.org 网站注册, 要安装一个第三方库, 必须先知道该库的名称, 可以在官网或者 pypi 上搜索
28.各种包管理工具区别:
distribute是setuptools的取代, pip是easy_install的取代
distribute被创建是因为setuptools包不再维护了
29.Python的实例属性必须在__init__(self) 方法中定义, 直接跟在类名后边定义的属性都默认是类属性(类似于c++的static变量), 类的属性一改, 只要没有覆盖此属性的对象的此属性都会改
main.py
aa_model
bb_model
结果如图:
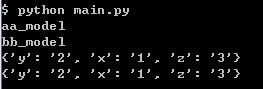
aa_model, bb_model: 由于reload方法中self.model_path = path, 实例重写了类的model_path属性(第一次赋值视为变量的定义), 故输出本实例的model_path
{‘y': 2, 'x': '1', 'z': '3'}, {‘y': 2, 'x': '1', 'z': '3'}: 由于self.model_dict.clear(), 第一次使用此变量非赋值而是直接使用(类似PHP), 类似函数中表示使用已有的值, 根据MRO, 搜索到Model.model_dict, 故两次会覆盖同一个变量
30.类的特殊属性
C.__name__: 类的名字
C.__doc__: 类的文档描述
C.__bases__: 类的基类组成的元组
C.__dict__: 类的属性
C.__module__: 类所在模块
C.__class__: 类的类名
__getattribute__: 不管属性是否存在都会调用
__getattr__: 如果属性不存在则调用, 如果__getattribute__被定义会先被调用, 然后调用此方法, 也可以返回函数
__setattr__
__delattr__
__slots__: 限制实例可以添加到属性
hasattr(), getattr(), setattr(), delattr()
31.实例的特殊属性
i.__class__: 实例的类名
i.__dict__: 实例的属性, __dict__分层存储属性, 每一层的__dict__只存储该层新增的属性, 子类不需要重复存储父类中的属性
32.property()可以即时生成属性
33.类中私有属性__xx, 实现为Python自动为__xx改变变量名
34.当我们定义一个class的时候, 我们实际上就定义了一种数据类型, 我们定义的数据类型和Python自带的数据类型, 比如str、list、dict没什么两样, type(instance), 返回instance对应的Class类型, 比如
type()函数可以查看一个类型或变量的类型, A是一个class(类对象), 它的类型就是type, 而h是一个实例, 它的类型就是class A
class的定义是运行时动态创建的, 而创建class的方法就是使用type()函数, type()函数既可以返回一个对象的类型, 又可以创建出新的类型, 比如, 我们可以通过type()函数创建出A类, 而无需通过class A(object)...的定义,
type() 创建类对象的参数如下:
class的名称
继承的父类集合, 注意Python支持多重继承, 如果只有一个父类, 别忘了tuple的单元素写法
class的方法名称与函数绑定, 这里我们把函数fn绑定到方法名hello上
[b]通过type()函数创建的类和直接写class是完全一样的, 因为Python解释器遇到class定义时, 仅仅是扫描一下class定义的语法, 然后调用type()函数创建出class
除了使用type()动态创建类对象, 还可以使用元类, 即 metaclass, 流程为先定义metaclass, 就可以创建类, 最后创建实例
__new__()方法接收到的参数依次是:当前准备创建的类的对象, 类的名字, 类继承的父类集合, 类的方法集合
35.types模块, 可以查看所有的type, type(abs) == types.BuiltinFunctionType
36.把方法变成属性 @property
37.Linux下用Python实现多进程(此处不是讲线程), Unix/Linux操作系统提供了一个fork()系统调用, 它返回两次, 因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程), 然后, 分别在父进程和子进程内返回, 子进程永远返回0, 而父进程返回子进程的ID, 这样做的理由是, 一个父进程可以fork出很多子进程, 所以, 父进程要记下每个子进程的ID, 而子进程只需要调用getppid()就可以拿到父进程的ID; Windows系统不支持fork()函数; 有了fork调用, 一个进程在接到新任务时就可以复制出一个子进程来处理新任务, 常见的Apache服务器就是由父进程监听端口, 每当有新的http请求时, 就fork出子进程来处理新的http请求
38.multiprocessing模块是跨平台的多进程模块
创建一个进程运行某个函数
结果为:
join()方法可以等待子进程结束后再继续往下运行, 通常用于进程间的同步
39.占位
40.timestamp与时区毫无关系, timestamp一旦确定, 其UTC时间就确定了, 转换到任意时区的时间也是完全确定的, 全球各地的计算机在任意时刻的timestamp都是完全相同的, datetime是有时区的, 会在timestamp与本地时间之间做转换
41.struct模块, 了解c语言的人, 一定会知道struct结构体在c语言中的作用, 它定义了一种结构, 里面包含不同类型的数据(int, char, bool等等), 方便对某一结构对象进行处理, 而在网络通信当中, 大多传递的数据是以二进制流(binary data)存在的, 当传递字符串时, 不必担心太多的问题, 而当传递诸如int、char之类的基本数据的时候, 就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输, 而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据, python中的struct模块就提供了这样的机制, 该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化.
H表示 一个unsigned short的id, 4s表示4字节长的字符串, 2I表示有两个unsigned int类型的数据
struct中支持的格式如下表
另一方面, 打包的后的字节顺序默认上是由操作系统的决定的, 当然struct模块也提供了自定义字节顺序的功能, 可以指定大端存储、小端存储等特定的字节顺序, 对于底层通信的字节顺序是十分重要的, 不同的字节顺序和存储方式也会导致字节大小的不同; 在format字符串前面加上特定的符号即可以表示不同的字节顺序存储方式, 例如采用小端存储 s = struct.Struct(‘<I3sf’)就可以了, 官方api library 也提供了相应的对照列表:
利用struct解析BMP文件头, 首先找一个bmp文件, 没有的话用“画图”画一个, 读入前30个字节来分析:
BMP格式采用小端方式存储数据,文件头的结构按顺序如下: 两个字节:'BM'表示Windows位图,'BA'表示OS/2位图; 一个4字节整数:表示位图大小; 一个4字节整数:保留位,始终为0; 一个4字节整数:实际图像的偏移量; 一个4字节整数:Header的字节数; 一个4字节整数:图像宽度; 一个4字节整数:图像高度; 一个2字节整数:始终为1; 一个2字节整数:颜色数。 所以,组合起来用unpack读取:
结果显示,b'B'、b'M'说明是Windows位图,位图大小为640x360,颜色数为24。
42.快速创建字典
{}.from_keys(list, defaultValue)
dict((key1, value1), (key2, value2), (key3, value3)...)
zip([key1, key2, key3...], [value1, value2, value3...])
dict(name = "John", "age" = 26)
43.判断字典中键名是否存在的两种方法
44.判断对象中属性/方法是否存在
45.动态调用方法
46.False, 0, '', (), [], {}都可以视为假
47.列表内数据唯一(类似PHP中array_unique)
48.根据一个对象创建另一个对象
49.collections模块
collections.namedtuple 创建可命名的tuple
collections.deque 为了高效实现插入和删除操作的双向列表,增删效率高于 list,也可以使用 deque(maxlen = 10) 来限制列表长度,超出时添加会把头尾的元素挤出。
collections.defaultdict 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict,也可以直接创建多维字典。
collections.OrderedDict 创建按key值遍历时有序的dict(普通dict无序排列) 使用
50.禁止创建对象属性字典。每个类都有实例属性,默认用一个字典保存一个对象的实例属性,允许我们设置任意属性,但是可能会浪费很多内存。使用__slots__高速Python不要使用字典,而且只给一个固定集合的属性分配空间。
51.文件遍历
52.打印格式化的json
53.格式化输出字典
54.字典和集合也有列表推导式,都使用{}包围,分别返回字典和集合
55.字面量,即 {}, [] 等直接表示。
56.从标准输入获取数据,除了 input、raw_input 也可以使用如下方式
57.数据库 IN 查询的正确姿势不是如下
而是如下(参考资料:http://ju.outofmemory.cn/entry/51481):
58.
requests urilib的替代品
BeautifulSoup4 解析HTML代码
rq 任务队列
selenium 自动化测试工具,模拟浏览器
1.sys.modules, 根据已加载的模块创建对象, 其中 page 为类名
if hasattr(sys.modules[__name__], page): setattr(self, page, getattr(sys.modules[__name__], page)(self))
2.hasattr, setattr, locals(), globals() 动态创建变量
3.绑定、未绑定
未绑定的类方法: 没有self
通过类来引用方法返回一个未绑定方法对象, 要调用它, 你必须显示地提供一个实例作为第一个参数
绑定的实例方法: 有self
通过实例访问方法返回一个绑定的方法对象, Python自动地给方法绑定一个实例, 所以我们调用它时不用再传一个实例参数
class Test:
def func(self,message):
print message
object1 = Test()
x = object1.func
x('绑定方法对象,实例是隐含的')
t=Test.func
t(object1,'未绑定的方法对象,需要传递一个实例')
#t('未绑定的方法对象,需要传递一个实例') #错误的调用object1 = Test()生成一个实例, object1.func返回一个绑定的方法, 把实例object1和方法func绑定, 而Test.func是用类去引用方法, 我们得到一个未绑定的方法对象, 要调用它就得传一个实例参数, 如t(object1,'未绑定的方法对象,需要传递一个实例')
class A(object): def f(self): print "f" def ff(): print "ff" a = A() a.f() xf = a.f #xf为绑定的方法, 故不用传入第一个值 xf() a.f = ff a.f()
4.MRO(method resolution order, 多继承时判断调的属性的类)
MRO要先确定一个线性序列, 然后查找路径由由序列中类的顺序决定, 所以MRO的算法就是生成一个线性序列
Python先后有三种不同的MRO: 经典方式、Python2.2 新式算法、Python2.3 新式算法(C3), Python 3中只保留了最后一种, 即C3算法
经典方式: 非常简单, 深度优先, 按定义从左到右
新式算法: 还是经典方式, 但出现重复的, 只保留最后一个
C3算法: 最早被提出是用于Lisp的, 应用在Python中是为了解决原来基于深度优先搜索算法不满足本地优先级, 和单调性的问题:
本地优先级: 指声明时父类的顺序, 比如C(A, B), 如果访问C类对象属性时, 应该根据声明顺序, 优先查找A类, 然后再查找B类
单调性: 如果在C的解析顺序中, A排在B的前面, 那么在C的所有子类里, 也必须满足这个顺序
class B(A) 这时B的mro序列为[B,A]
class B(A1,A2,A3 ...) 这时B的mro序列 mro(B) = + merge(mro(A1), mro(A2), mro(A3) ..., [A1,A2,A3])
merge操作就是C3算法的核心, 遍历执行merge操作的序列, 如果一个序列的第一个元素, 是其他序列中的第一个元素, 或不在其他序列出现, 则从所有执行merge操作序列中删除这个元素, 合并到当前的mro中, merge操作后的序列, 继续执行merge操作, 直到merge操作的序列为空, 如果merge操作的序列无法为空, 则说明不合法
class a:pass class b(a):pass class c(a):pass class d(b, c):pass
比如此菱形继承结构
按经典方式, d类MRO为dbaca, 缺点是如果c类重写了a类中得方法, c类的方法将不会被调用到(即本地优先顺序问题)
按新式算法, d类MRO为dbca, 缺点是单调性, 比如d继承b、c, 且b在c的前面, 如果f继承d, 那么f的MRO中也应该和d的一样b在c的前面, 单调性即继承时要保持顺序, 现在e继承c、b, 且c在b的前面, f继承d, e时, bc的顺序就没法决定了, 无论怎样排都违反了单调性
class A(O):pass class B(O):pass class C(O):pass class E(A,B):pass class F(B,C):pass class G(E,F):pass
按C3算法, A、B、C都继承至一个基类, 所以mro序列依次为[A,O]、[B,O]、[C,O]
mro(E) = [E] + merge(mro(A), mro(B), [A,B])
= [E] + merge([A,O], [B,O], [A,B])
此时需要执行merge操作的序列为[A,O]、[B,O]、[A,B]
A是序列[A,O]中的第一个元素, 在序列[B,O]中不出现, 在序列[A,B]中也是第一个元素, 所以从执行merge操作的序列([A,O]、[B,O]、[A,B])中删除A, 合并到当前mro, [E]中
mro(E) = [E,A] + merge([O], [B,O], [B])
再执行merge操作, O是序列[O]中的第一个元素, 但O在序列[B,O]中出现并且不是其中第一个元素, 继续查看[B,O]的第一个元素B, B满足条件, 所以从执行merge操作的序列中删除B, 合并到[E, A]中
mro(E) = [E,A,B] + merge([O], [O])
= [E,A,B,O]
实现C3算法的代码:
#-*- encoding:GBK -*-#
def mro_C3(*cls):
if len(cls)==1:
if not cls[0].__bases__:
return cls
else:
return cls+ mro_C3(*cls[0].__bases__)
else:
seqs = [list(mro_C3(C)) for C in cls ] +[list(cls)]
res = []
while True:
non_empty = list(filter(None, seqs))
if not non_empty:
return tuple(res)
for seq in non_empty:
candidate = seq[0]
not_head = [s for s in non_empty if candidate in s[1:]]
if not_head:
candidate = None
else:
break
if not candidate:
raise TypeError("inconsistent hierarchy, no C3 MRO is possible")
res.append(candidate)
for seq in non_empty:
if seq[0] == candidate:
del seq[0]查看一个类的MRO列表, 可以使用 classname.__mro__
5.super 避免多次调用基类
# -*- coding:utf-8 -*- class D(object): def foo(self): print "class D" class B(D): pass class C(D): def foo(self): print "class C" class A(B, C): pass f = A() f.foo() #A的实例对象f在调用foo函数的时候, 根据广度优先搜索原则, 调用的是C类里面的foo函数, 上面的代码输出class C; 如果定义D类的时候直接class D, 而不是class D(object), 那么上述代码就该输出class D了
1). super并不是一个函数, 是一个类名, 形如super(B, self)事实上调用了super类的初始化函数产生了一个super对象;
2). super类的初始化函数并没有做什么特殊的操作, 只是简单记录了类类型和具体实例;
3). super(B, self).func的调用并不是用于调用当前类的父类的func函数;
4). Python的多继承类是通过mro的方式来保证各个父类的函数被逐一调用, 而且保证每个父类函数只调用一次(如果每个类都使用super);
5). 混用super类和非绑定的函数是一个危险行为, 这可能导致应该调用的父类函数没有调用或者一个父类函数被调用多次
6).super并不是像我们想象中一样直接找到当前类的父类, 而是沿着mro顺藤摸瓜
参考:http://blog.csdn.net/johnsonguo/article/details/585193
6.模块即模块对象
7.利用 __new__ 实现单例
class Singleton(object): def __new__(cls, *args, **kwargs): # 关键在于这,每一次实例化的时候,我们都只会返回这同一个instance对象 if not hasattr(cls, "instance"): cls.instance = super(Singleton, cls).__new__(cls, *args, **kwargs) return cls.instance
8.__new__ 执行顺序
class A(object): def __new__(cls): Object = super(A, cls).__new__(cls) print "in New" return Object #如果把此行注释掉, 则不会执行 __init__ 方法 def __init__(self): print "in init" class B(A): def __init__(self): print "in B's init" B()
9.判断一个变量是否存在
1).
'var' in locals().keys()
2).
try: print var except NameError: print 'var not defined'
3).
'var' in dir()
10.根据类名创建实例, 主要是获得类的 class 对象
1).类名cls为class类型, 直接 cls() 即可
2).类名cls为str类型
m = __import__(clsstr所在模块名) cls = getattr(m, clsstr) cls()
如果myclass并不在mymodule的自动导出列表中(__all__), 则必须显式地导入, __import__('mymodule', globals(), locals(), ['myclass'])
11.获取当前模块名
locals()/globals().get("__name__")
12.import, reload, __import__
del sys.modules[modulename] 即可实现 unimport
import 调用的 __import__, 比如 import sys => sys = __import__("sys")
reload 对已经加载的模块进行重新加载, 一般用于原模块有变化等特殊情况, reload前该模块必须已经import过, 但原来已经使用的实例还是会使用旧的模块, 新生产的实例会使用新的模块
import sys #引用sys模块进来,并不是进行sys的第一次加载
reload(sys) #重新加载sys
sys.setdefaultencoding('utf8') ##调用setdefaultencoding函数
#如果去掉reload(sys), 会执行失败, 因为这里的import语句其实并不是sys的第一次导入语句, 也就是说这里其实可能是第二、三次进行sys模块的import, 这里只是一个对sys的引用, 只能reload才能进行重新加载; 那么为什么要重新加载, 而直接引用过来则不能调用该函数呢?因为setdefaultencoding函数在被系统调用后被删除了, 所以通过import引用进来时其实已经没有了, 所以必须reload一次sys模块, 这样setdefaultencoding才会为可用, 才能在代码里修改解释器当前的字符编码__import__, 返回模块实例
__import__(module_name[, globals[, locals[, fromlist]]]) #可选参数默认为globals(),locals(),[]
__import__('os')
__import__('os',globals(),locals(),['path','pip']) #等价于from os import path, pip13.迭代器
基本原理:
实现了__iter__方法的对象是可迭代的, 实现了next()方法的对象是迭代器(迭代器就是一个有next()方法的对象), 所以iter(实现了__iter__方法的对象)会调用此对象的__iter__方法, 返回一个实现了next()方法的迭代器对象, 不断调用此迭代器对象的next()方法, 实现遍历, 直到遇到StopIteration异常, 使用迭代器一个显而易见的好处就是每次只从对象中读取一条数据, 不会造成内存的过大开销
序列、字典、文件中当使用for x in y的结构时, 其实质就是迭代器, 迭代器是和实际对象绑定在一起的, 所以在使用迭代器时或者上述3者时不能修改可变对象的值, 这会产生错误
迭代器不要求你事先准备好整个迭代过程中所有的元素, 迭代器仅仅在迭代至某个元素时才计算该元素, 而在这之前或之后, 元素可以不存在或者被销毁, 这个特点使得它特别适合用于遍历一些巨大的或是无限的集合, 比如几个G的文件, 或是斐波那契数列等等, 这个特点被称为延迟计算或惰性求值(Lazy evaluation)
创建迭代器的方法: iter(object)和iter(func, sentinel)两种, 一种使用的是序列, 另一种使用类来创建, 迭代器更大的功劳是提供了一个统一的访问集合的接口, 只要是实现了__iter__()方法的对象, 就可以使用迭代器进行访问, 返回一个对象, 这个对象拥有一个next()方法, 这个方法能在恰当的时候抛出StopIteration异常即可
for i in seq: do_something_to(i)
实际为:
fetch = iter(seq) while True: try: i = fetch.next() except StopIteration: break do_something_to(i)
字典中, iterkeys(), itervalues(), iteritems() 比 keys(), values(), items() 更省内存
open("test.txt").readlines() 返回的是列表, open("test.txt") 返回的是迭代器
14.生成器
如果一个函数返回的列表非常大, 仅仅创建这个列表就会用完系统所有内存, 因为在我们的观念中函数只有一次返回结果的机会, 因而必须一次返回所有的结果, 此类问题可以用生成器解决
生成器是特定的函数, 允许你返回一个值, 然后“暂停”代码的执行, 稍后恢复, 生成器使用了“延迟计算”, 所以在内存上面更加有效, 生成器函数不能有返回值, 因为 yield 的值就是返回值, 生成器就是一类特殊的迭代器
1).调用生成器函数将返回一个生成器
>>> generator = get_0_1_2() >>> generator <generator object get_0_1_2 at 0x00B1C7D8>
2).第一次调用生成器的next方法时, 生成器才开始执行生成器函数(而不是构建生成器时), 直到遇到yield时暂停执行(挂起), 并且yield的参数将作为此次next方法的返回值
>>> generator.next() 0
3).之后每次调用生成器的next方法, 生成器将从上次暂停执行的位置恢复执行生成器函数, 直到再次遇到yield时暂停, 并且同样的, yield的参数将作为next方法的返回值
>>> generator.next() 1 >>> generator.next() 2
4).如果当调用next方法时生成器函数结束(遇到空的return语句或是到达函数体末尾), 则这次next方法的调用将抛出StopIteration异常(即for循环的终止条件)
>>> generator.next() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
5).生成器函数在每次暂停执行时, 函数体内的所有变量都将被封存(freeze)在生成器中, 并将在恢复执行时还原, 并且类似于闭包, 即使是同一个生成器函数返回的生成器, 封存的变量也是互相独立的, 我们的小例子中并没有用到变量, 所以这里另外定义一个生成器来展示这个特点
>>> def fibonacci(): ... a = b = 1 ... yield a ... yield b ... while True: ... a, b = b, a+b ... yield b ... >>> for num in fibonacci(): ... if num > 100: break ... print num, ... 1 1 2 3 5 8 13 21 34 55 89
看到while True可别太吃惊, 因为生成器可以挂起, 所以是延迟计算的, 无限循环并没有关系, 这个例子中我们定义了一个生成器用于获取斐波那契数列
如果生成器函数调用了return, 或者执行到函数的末尾, 会出现一个StopIteration异常
有一篇好文章:点击进入
15.列表解析器
也可以直接生成 dict
{x: 1 for x in ["name", "sex"]} #返回 {"name": 1, "sex" 1}列表解析一次生成一个列表, 所占内存较大
(x+1 for x in lst) #生成器表达式,返回迭代器。外部的括号可在用于参数时省略。 [x+1 for x in lst] #列表解析,返回list
由于返回迭代器时, 并不是在一开始就计算所有的元素, 这样能得到更多的灵活性并且可以避开很多不必要的计算, 所以除非你明确希望返回列表, 否则应该始终使用生成器表达式
可以在Python Shell中试一下一下两个语句的执行时间
(for x in range(1000000)) #返回生成器 [for x in range(1000000)] #返回整个列表
或者提供多条for子句进行嵌套循环, 嵌套次序就是for子句的顺序:
((x, y) for x in range(3) for y in range(x))
同样外部也可以使用 if
(x for x in (y.doSomething() for y in lst) if x>0)
16.在Python里, 函数的默认值实在函数定义的时候实例化的, 而不是在调用的时候, 如果在调用函数的时候重写了默认值, 那么这个存储的值就不会被使用, 当你不重写默认值的时候, 那么Python就会让默认值引用存储的值(这个例子里的numbers)
def abc(numbers = []): numbers.append(9) print numbers
abc(): [9] #第一次执行
abc(): [9, 9] #第二次执行
abc([1, 2]): [1, 2, 9] #第三次执行
abc(): [9, 9, 9] #第四次执行
def print_now(now = time.time()): print now #如果不加参数, 则每次都会返回相同的时间
默认参数最好指向不变对象!
17.当def这个声明执行的时候, Python会静态地从函数的局部作用域里获取信息, 当来到 xxx = yyy 这行的时候(不是执行到这行代码, 而是当Python解释器读到这行代码的时候), 它会把xxx这个变量加入到函数的局部变量列表里
18.__builtin__模块, 在Python启动后、且没有执行程序员所写的任何代码前, Python会首先加载该内建模块到内存, 另外, 该内建模块中的功能可以直接使用, 不用在其前添加内建模块前缀, 导入仅仅是让__builitin__标识符在该作用域内可见
19.from __future__ import xxx, 必须是模块或程序的第一个语句, 此外,'__ future__' 模块中存在的特性最终将成为Python语言标准的一部分, 到那时, 将不再需要使用 '__future__' 模块
20.序列解包
a, b, c = 1, 2, 3 #赋值 a, b = b, a #转换a, b的值 a = 1, #声明元组
21.最好了解下二进制文件和文本文件的区别以及编码问题, ASCII(固定一个字节)->Unicode(固定两个字节)->UTF-8(变长), 在计算机内存中, 统一使用Unicode编码, 当需要保存到硬盘或者需要传输的时候, 就转换为UTF-8编码, 用记事本编辑的时候, 从文件读取的UTF-8字符被转换为Unicode字符到内存里, 编辑完成后, 保存的时候再把Unicode转换为UTF-8保存到文件, len()函数计算的是str(Unicode编码)的字符数, 如果换成bytes(UTF-8等编码), len()函数就计算字节数:
参考自:廖雪峰Python
22.dict的key必须是不可变对象
23.Python函数参数顺序
定义: (arg, kwarg = <value>, *args, **kwargs)
调用:
第一, 按顺序把"arg"这种形式的实参给对应的形参
第二, 把"arg=<value>"这种形式的实参赋值给形式kwarg
第三, 把多出来的"arg"这种形式的实参组成一个tuple给带一个星号的形参args
第四, 把多出来的"key=value"这种形式的实参转为一个dictionary给带两个星号的形参kwargs
def test(x, y = 5, *a, **b): print x, y, a, b
test(1) ===> 1 5 () {}
test(1,2) ===> 1 2 () {}
test(1,2,3) ===> 1 2 (3,) {}
test(1,2,3,4) ===> 1 2 (3,4)
test(x=1) ===> 1 5 () {}
test(x=1,y=1) ===> 1 1 () {}
test(x=1,y=1,a=1) ===> 1 1 () {'a':1}
test(x=1,y=1,a=1,b=1) ===> 1 1 () {'a':1,'b':1}
test(1,y=1) ===> 1 1 () {}
test(1,2,y=1) ===> 出错, 说y给赋了多个值
test(1, y = 2, 3, a = 4) ===> 出错, non-keyword arg after keyword arg
test(1,2,3,4,a=1) ===> 1 2 (3,4) {'a':1}24.限制 **kwargs 参数个数
#只接收city和job作为关键字参数 def person(name, age, *, city, job): print(name, age, city, job)
25.functools 模块
wraps: 用来装饰返回func的函数, 以同步func与被装饰的函数的属性, 比如__name__等 @functools.wraps(func)
partial: 变化函数的参数创建偏函数, 固定住原函数的部分参数, 比如 int2 = functools.partial(x, base = 2), 此时 int2 是一个把二进制字符串转为十进制数字的函数, int2('10010')
26.一个.py文件称为一个模块, 为了避免模块名冲突, Python按目录来组织模块的方法, 称为包(Package), 包内必须有__init__.py, 因为__init__.py本身就是一个模块, 它的模块名就是包名(目录名)
27.第三方库都会在 Python 官方的 pypi.python.org 网站注册, 要安装一个第三方库, 必须先知道该库的名称, 可以在官网或者 pypi 上搜索
28.各种包管理工具区别:
distribute是setuptools的取代, pip是easy_install的取代
distribute被创建是因为setuptools包不再维护了
29.Python的实例属性必须在__init__(self) 方法中定义, 直接跟在类名后边定义的属性都默认是类属性(类似于c++的static变量), 类的属性一改, 只要没有覆盖此属性的对象的此属性都会改
main.py
#-*- coding: utf-8 -*-
class Model():
model_path = "online_model"
model_dict = {}
def __init__(self, path = None):
self.reload(path)
def reload(self, path = None):
if not path:
return
self.model_dict.clear()
fp = file(path, "r")
for line in fp:
cols = line.split()
self.model_dict[cols[0]] = cols[1]
self.model_path = path
def main():
m1 = Model()
m2 = Model()
m1.reload("aa_model")
m2.reload("bb_model")
print m1.model_path
print m2.model_path
print m1.model_dict
print m2.model_dict
return 0
if __name__ == "__main__":
main()aa_model
1 a 2 b
bb_model
x 1 y 2 z 3
结果如图:
aa_model, bb_model: 由于reload方法中self.model_path = path, 实例重写了类的model_path属性(第一次赋值视为变量的定义), 故输出本实例的model_path
{‘y': 2, 'x': '1', 'z': '3'}, {‘y': 2, 'x': '1', 'z': '3'}: 由于self.model_dict.clear(), 第一次使用此变量非赋值而是直接使用(类似PHP), 类似函数中表示使用已有的值, 根据MRO, 搜索到Model.model_dict, 故两次会覆盖同一个变量
30.类的特殊属性
C.__name__: 类的名字
C.__doc__: 类的文档描述
C.__bases__: 类的基类组成的元组
C.__dict__: 类的属性
C.__module__: 类所在模块
C.__class__: 类的类名
__getattribute__: 不管属性是否存在都会调用
__getattr__: 如果属性不存在则调用, 如果__getattribute__被定义会先被调用, 然后调用此方法, 也可以返回函数
class A(object): def __getattr__(self, attr): if attr == "age": return lambda : 25 a = A() a.age()
__setattr__
__delattr__
__slots__: 限制实例可以添加到属性
hasattr(), getattr(), setattr(), delattr()
31.实例的特殊属性
i.__class__: 实例的类名
i.__dict__: 实例的属性, __dict__分层存储属性, 每一层的__dict__只存储该层新增的属性, 子类不需要重复存储父类中的属性
32.property()可以即时生成属性
33.类中私有属性__xx, 实现为Python自动为__xx改变变量名
34.当我们定义一个class的时候, 我们实际上就定义了一种数据类型, 我们定义的数据类型和Python自带的数据类型, 比如str、list、dict没什么两样, type(instance), 返回instance对应的Class类型, 比如
class A(object): pass a = A() b = type(a)() #此时b为A的实例 print type(A) #<type 'type'> print type(a) #<class '__main__.A'> print isinstance(b, A) #True
type()函数可以查看一个类型或变量的类型, A是一个class(类对象), 它的类型就是type, 而h是一个实例, 它的类型就是class A
class的定义是运行时动态创建的, 而创建class的方法就是使用type()函数, type()函数既可以返回一个对象的类型, 又可以创建出新的类型, 比如, 我们可以通过type()函数创建出A类, 而无需通过class A(object)...的定义,
def fn(self, name = "John"):
self.name = name
A = type('A', (object,), dict(hello=fn))
a = A()
print type(A) #<type 'type'>
print type(a) #<class '__main__.A'>type() 创建类对象的参数如下:
class的名称
继承的父类集合, 注意Python支持多重继承, 如果只有一个父类, 别忘了tuple的单元素写法
class的方法名称与函数绑定, 这里我们把函数fn绑定到方法名hello上
[b]通过type()函数创建的类和直接写class是完全一样的, 因为Python解释器遇到class定义时, 仅仅是扫描一下class定义的语法, 然后调用type()函数创建出class
除了使用type()动态创建类对象, 还可以使用元类, 即 metaclass, 流程为先定义metaclass, 就可以创建类, 最后创建实例
# metaclass是创建类,所以必须从`type`类型派生: class ListMetaclass(type): def __new__(cls, name, bases, attrs): attrs['add'] = lambda self, value: self.append(value) return type.__new__(cls, name, bases, attrs) class MyList(list): __metaclass__ = ListMetaclass # 指示使用ListMetaclass来定制类, 表示创建MyList时要通过ListMetaclass.__new__()来创建, 在此, 我们可以修改类的定义, 比如, 加上新的方法, 然后, 返回修改后的定义
__new__()方法接收到的参数依次是:当前准备创建的类的对象, 类的名字, 类继承的父类集合, 类的方法集合
35.types模块, 可以查看所有的type, type(abs) == types.BuiltinFunctionType
36.把方法变成属性 @property
class Student(object):
#@property 会创建一个另外一个装饰器 @score.setter, 负责把一个方法编程属性赋值
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
s = Student()
s.score = 60
s.score = 101 #ValueError: Score must between 0 ~ 100!37.Linux下用Python实现多进程(此处不是讲线程), Unix/Linux操作系统提供了一个fork()系统调用, 它返回两次, 因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程), 然后, 分别在父进程和子进程内返回, 子进程永远返回0, 而父进程返回子进程的ID, 这样做的理由是, 一个父进程可以fork出很多子进程, 所以, 父进程要记下每个子进程的ID, 而子进程只需要调用getppid()就可以拿到父进程的ID; Windows系统不支持fork()函数; 有了fork调用, 一个进程在接到新任务时就可以复制出一个子进程来处理新任务, 常见的Apache服务器就是由父进程监听端口, 每当有新的http请求时, 就fork出子进程来处理新的http请求
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))38.multiprocessing模块是跨平台的多进程模块
创建一个进程运行某个函数
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')结果为:
Parent process 67416. Child process will start. Run child process test (70388)... Child process end.
join()方法可以等待子进程结束后再继续往下运行, 通常用于进程间的同步
39.占位
40.timestamp与时区毫无关系, timestamp一旦确定, 其UTC时间就确定了, 转换到任意时区的时间也是完全确定的, 全球各地的计算机在任意时刻的timestamp都是完全相同的, datetime是有时区的, 会在timestamp与本地时间之间做转换
>>> from datetime import datetime >>> t = 1429417200.0 >>> print(datetime.fromtimestamp(t)) # 本地时间 2015-04-19 12:20:00 >>> print(datetime.utcfromtimestamp(t)) # UTC时间 2015-04-19 04:20:00
41.struct模块, 了解c语言的人, 一定会知道struct结构体在c语言中的作用, 它定义了一种结构, 里面包含不同类型的数据(int, char, bool等等), 方便对某一结构对象进行处理, 而在网络通信当中, 大多传递的数据是以二进制流(binary data)存在的, 当传递字符串时, 不必担心太多的问题, 而当传递诸如int、char之类的基本数据的时候, 就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输, 而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据, python中的struct模块就提供了这样的机制, 该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化.
>>>import struct
>>>ss = struct.pack("!H4s2I", 20, "abcd", 6, 7)
>>>ss
"\x00\x14abcd\x00\x00\x00\x06\x00\x00\x00\x07" #ss是一个字符串 类似c结构体的字节流(二进制)的字符串表示
>>>struct.unpack("!H4s2I", ss)
(20, 'abcd', 6, 7)H表示 一个unsigned short的id, 4s表示4字节长的字符串, 2I表示有两个unsigned int类型的数据
struct中支持的格式如下表
| Format | C Type | Python | 字节数 |
|---|---|---|---|
| x | pad byte | no value | 1 |
| c | char | string of length 1 | 1 |
| b | signed char | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I | unsigned int | integer or long | 4 |
| l | long | integer | 4 |
| L | unsigned long | long | 4 |
| q | long long | long | 8 |
| Q | unsigned long long | long | 8 |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char[] | string | 1 |
| p | char[] | string | 1 |
| P | void * | long |
| Character | Byte order | Size and alignment |
|---|---|---|
| @ | native | native 凑够4个字节 |
| = | native | standard 按原字节数 |
| < | little-endian | standard 按原字节数 |
| > | big-endian | standard 按原字节数 |
| ! | network (= big-endian) | standard 按原字节数 |
>>> s = b'\x42\x4d\x38\x8c\x0a\x00\x00\x00\x00\x00\x36\x00\x00\x00\x28\x00\x00\x00\x80\x02\x00\x00\x68\x01\x00\x00\x01\x00\x18\x00'
BMP格式采用小端方式存储数据,文件头的结构按顺序如下: 两个字节:'BM'表示Windows位图,'BA'表示OS/2位图; 一个4字节整数:表示位图大小; 一个4字节整数:保留位,始终为0; 一个4字节整数:实际图像的偏移量; 一个4字节整数:Header的字节数; 一个4字节整数:图像宽度; 一个4字节整数:图像高度; 一个2字节整数:始终为1; 一个2字节整数:颜色数。 所以,组合起来用unpack读取:
>>> struct.unpack('<ccIIIIIIHH', s)
(b'B', b'M', 691256, 0, 54, 40, 640, 360, 1, 24)结果显示,b'B'、b'M'说明是Windows位图,位图大小为640x360,颜色数为24。
42.快速创建字典
{}.from_keys(list, defaultValue)
dict((key1, value1), (key2, value2), (key3, value3)...)
zip([key1, key2, key3...], [value1, value2, value3...])
dict(name = "John", "age" = 26)
43.判断字典中键名是否存在的两种方法
#第一种 d.has_key() #第二种 "" in d.keys()
44.判断对象中属性/方法是否存在
hasattr(object, attr) attr in dir(object)
45.动态调用方法
def _execute(self, sql, params, isMany): func = "executemany" if isMany else "execute" func = getattr(self._db["cur"], func) return func(sql, params)
46.False, 0, '', (), [], {}都可以视为假
47.列表内数据唯一(类似PHP中array_unique)
set([1, 2, 1]) -- set([1, 2])
48.根据一个对象创建另一个对象
obj.__class__(...)
49.collections模块
collections.namedtuple 创建可命名的tuple
import collections as cs
Point = cs.namedtuple("Point", ["x", "y", "z"])
p = Point(1, 2, 3)
print p.x, p.y, p.zcollections.deque 为了高效实现插入和删除操作的双向列表,增删效率高于 list,也可以使用 deque(maxlen = 10) 来限制列表长度,超出时添加会把头尾的元素挤出。
import collections as cs
q = cs.deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
print q
>>>deque(['y', 'a', 'b', 'c', 'x'])collections.defaultdict 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict,也可以直接创建多维字典。
import collections as cs tree = lambda: collections.defaultdict(tree) d = tree() d["names"]["John"] = "ABC"
collections.OrderedDict 创建按key值遍历时有序的dict(普通dict无序排列) 使用
50.禁止创建对象属性字典。每个类都有实例属性,默认用一个字典保存一个对象的实例属性,允许我们设置任意属性,但是可能会浪费很多内存。使用__slots__高速Python不要使用字典,而且只给一个固定集合的属性分配空间。
class MyClass(obj ect) : __slots__ = [ ' name' , ' identifier' ] def __init__(self, name, identifier) : self. name = name self. identifier = identifier self. set_up()
51.文件遍历
with open("foo.txt", "r") as f:
for line in f:
# do_something(line)
for line in open("foo.txt", "r"):
# do_something(line)52.打印格式化的json
import json
print json.dumps({"name": "John"}, indent = 2)53.格式化输出字典
print("I'm %(name)s. I'm %(age)d year old" % {'name':'Vamei', 'age':99})
print("I'm {name}.I'm {age} year old").format(name = "John", age = 26)54.字典和集合也有列表推导式,都使用{}包围,分别返回字典和集合
#快速兑换字典键—值
mca={"a":1, "b":2, "c":3, "d":4}
dicts={v:k for k,v in mca.items()}
#{1: 'a', 2: 'b', 3: 'c', 4: 'd'}55.字面量,即 {}, [] 等直接表示。
56.从标准输入获取数据,除了 input、raw_input 也可以使用如下方式
import sys sys.stdin.readline().strip()
57.数据库 IN 查询的正确姿势不是如下
id_list = [1, 2, 3]
arg_list = ','.join(['%s'] * len(id_list))
cursor.execute('SELECT col1, col2 FROM table1 WHERE id IN (%s)' % arg_list, id_list)而是如下(参考资料:http://ju.outofmemory.cn/entry/51481):
id_list = [1, 2, 3]
cursor.execute('SELECT col1, col2 FROM table1 WHERE id IN %s', (id_list,))58.

相关文章推荐
- 3. Python 简介
- Windows python实现截屏功能
- python之禅
- python datetime模块详解
- scrapy 简单教程
- python 安装pip
- python 黑名单过滤
- python-__init__.py 与模块对象的关系
- Python正则表达式指南
- python MySQL数据库连接
- Python计算图形中三角形数量
- Python 目录操作
- Python爬虫学习開篇
- python academy
- 将Python的Django框架与认证系统整合的方法
- 第一个Python程序——执行cmd命令
- Python字符串转换成浮点数函数分享
- python:undefined symbol: PyUnicodeUCS*问题
- Python下opencv使用笔记(十二)(k均值算法之图像分割)
- 小白学python(一) 最简单的代码片段