为什么排版引擎解析 CSS 选择器时一定要从右往左解析?
2015-07-20 16:30
676 查看
用一个哲学来解释:人可以选择2条路,而走的时候,只能走一条。
在任何熟悉或阅读信息的书籍或报纸或代码时,都是一行一行的。
从章节角度看,类似一个treeview....单向树...;
你要从右往左匹配也是可以做到的,但没人那么写算法...
Sunday算法号称急快速字符串匹配,如果把现有的好多规范弄成从右往左,目测,执行效率会快很多。
原理:
首先我们要看一下选择器的「解析」是在何时进行的。
主要参考这篇「 How browsers work」(http://taligarsiel.com/Projects/howbrowserswork1.htm)来看,浏览器渲染的过程以
WebKit 为例大致如下:
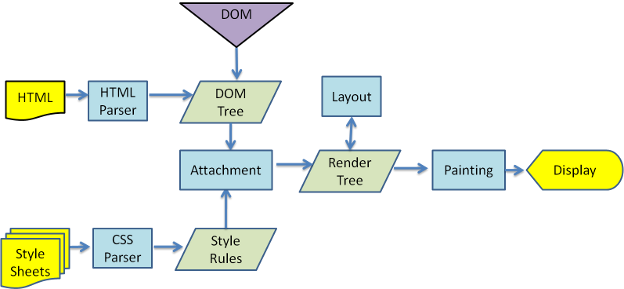
HTML 经过解析生成 DOM Tree(这个我们比较熟悉);而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵
Render Tree,最终用来进行绘图。Render Tree 中的元素(WebKit 中称为「renderers」,Firefox 下为「frames」)与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的「行」会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。
因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断「这个 selector 不匹配当前元素」就是极其重要的。
如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
其它答案:
Keep in mind that when a browser is doing selector matching it has one element (the one it's trying to determine style for) and all your rules and their selectors and it needs to find which rules match the element. This is different from the usual
jQuery thing, say, where you only have one selector and you need to find all the elements that match that selector.
If you only had one selector and only one element to compare against that selector, then left-to-right makes more sense in some cases. But that's decidedly not the browser's situation. The browser is trying to render Gmail or whatever and has the one
it's trying to style and the 10,000+ rules Gmail puts in its stylesheet (I'm not making that number up).
In particular, in the situation the browser is looking at most of the selectors it's considering don't match the element in question. So the problem becomes one of deciding that a selector doesn't match as fast as possible; if that requires a bit of extra work
in the cases that do match you still win due to all the work you save in the cases that don't match.
If you start by just matching the rightmost part of the selector against your element, then chances are it won't match and you're done. If it does match, you have to do more work, but only proportional to your tree depth, which is not that big in most cases.
On the other hand, if you start by matching the leftmost part of the selector... what do you match it against? You have to start walking the DOM, looking for nodes that might match it. Just discovering that there's nothing matching that leftmost part might
take a while.
So browsers match from the right; it gives an obvious starting point and lets you get rid of most of the candidate selectors very quickly. You can see some data at
http://groups.google.com/group/mozilla.dev.tech.layout/browse_thread/thread/b185e455a0b3562a/7db34de545c17665 (though the notation is
confusing), but the upshot is that for Gmail in particular two years ago, for 70% of the (rule, element) pairs you could decide that the rule does not match after just examining the tag/class/id parts of the rightmost selector for the rule. The corresponding
number for Mozilla's pageload performance test suite was 72%. So it's really worth trying to get rid of those 2/3 of all rules as fast as you can and then only worry about matching the remaining 1/3.
Note also that there are other optimizations browsers already do to avoid even trying to match rules that definitely won't match. For example, if the rightmost selector has an id and that id doesn't match the element's id, then there will be no attempt to match
that selector against that element at all in Gecko: the set of "selectors with IDs" that are attempted comes from a hashtable lookup on the element's ID. So this is 70% of the rules which have a pretty good chance of matching that still don't match after considering
just the tag/class/id of the rightmost selector
via Boris Zbarsky(http://stackoverflow.com/questions/5797014/css-selectors-parsed-right-to-left-why/5813672#5813672)
在任何熟悉或阅读信息的书籍或报纸或代码时,都是一行一行的。
从章节角度看,类似一个treeview....单向树...;
你要从右往左匹配也是可以做到的,但没人那么写算法...
Sunday算法号称急快速字符串匹配,如果把现有的好多规范弄成从右往左,目测,执行效率会快很多。
原理:
首先我们要看一下选择器的「解析」是在何时进行的。
主要参考这篇「 How browsers work」(http://taligarsiel.com/Projects/howbrowserswork1.htm)来看,浏览器渲染的过程以
WebKit 为例大致如下:
HTML 经过解析生成 DOM Tree(这个我们比较熟悉);而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵
Render Tree,最终用来进行绘图。Render Tree 中的元素(WebKit 中称为「renderers」,Firefox 下为「frames」)与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的「行」会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。
因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断「这个 selector 不匹配当前元素」就是极其重要的。
如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
其它答案:
Keep in mind that when a browser is doing selector matching it has one element (the one it's trying to determine style for) and all your rules and their selectors and it needs to find which rules match the element. This is different from the usual
jQuery thing, say, where you only have one selector and you need to find all the elements that match that selector.
If you only had one selector and only one element to compare against that selector, then left-to-right makes more sense in some cases. But that's decidedly not the browser's situation. The browser is trying to render Gmail or whatever and has the one
it's trying to style and the 10,000+ rules Gmail puts in its stylesheet (I'm not making that number up).
In particular, in the situation the browser is looking at most of the selectors it's considering don't match the element in question. So the problem becomes one of deciding that a selector doesn't match as fast as possible; if that requires a bit of extra work
in the cases that do match you still win due to all the work you save in the cases that don't match.
If you start by just matching the rightmost part of the selector against your element, then chances are it won't match and you're done. If it does match, you have to do more work, but only proportional to your tree depth, which is not that big in most cases.
On the other hand, if you start by matching the leftmost part of the selector... what do you match it against? You have to start walking the DOM, looking for nodes that might match it. Just discovering that there's nothing matching that leftmost part might
take a while.
So browsers match from the right; it gives an obvious starting point and lets you get rid of most of the candidate selectors very quickly. You can see some data at
http://groups.google.com/group/mozilla.dev.tech.layout/browse_thread/thread/b185e455a0b3562a/7db34de545c17665 (though the notation is
confusing), but the upshot is that for Gmail in particular two years ago, for 70% of the (rule, element) pairs you could decide that the rule does not match after just examining the tag/class/id parts of the rightmost selector for the rule. The corresponding
number for Mozilla's pageload performance test suite was 72%. So it's really worth trying to get rid of those 2/3 of all rules as fast as you can and then only worry about matching the remaining 1/3.
Note also that there are other optimizations browsers already do to avoid even trying to match rules that definitely won't match. For example, if the rightmost selector has an id and that id doesn't match the element's id, then there will be no attempt to match
that selector against that element at all in Gecko: the set of "selectors with IDs" that are attempted comes from a hashtable lookup on the element's ID. So this is 70% of the rules which have a pretty good chance of matching that still don't match after considering
just the tag/class/id of the rightmost selector
via Boris Zbarsky(http://stackoverflow.com/questions/5797014/css-selectors-parsed-right-to-left-why/5813672#5813672)

相关文章推荐
- 初识CSS3
- 陈力:传智播客古代 珍宝币 泡泡龙游戏开发第十四讲:DIV+CSS实例
- DatePicker的一些样式属性设置
- 纯CSS3美化radio和checkbox
- 史上最全的CSS hack方式一览
- 左侧显示信息选项卡的样式控制
- JS+CSS实现幻灯片
- 【HTML+CSS】浅谈:相对定位与绝对定位
- 浏览器加载和渲染html的顺序-css渲染效率的探究
- 终于搞懂了CSS实现三角形图标的原理
- CSS给网页添加背景 铺满屏幕
- CSS的class、id、css文件名的常用命名规则
- 函数 getStyle() 获取元素 CSS 样式
- CSS 基础
- CSS3属性(二)
- Flex 布局语法教程
- 【Web前端】清除浮动&css中文字体
- css选择器
- 截取带有样式的简介方法
- Css样式表和input框