第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(2)
2015-07-16 17:27
495 查看
Spark-shell启动后我们可以在控制台看到起运行信息:
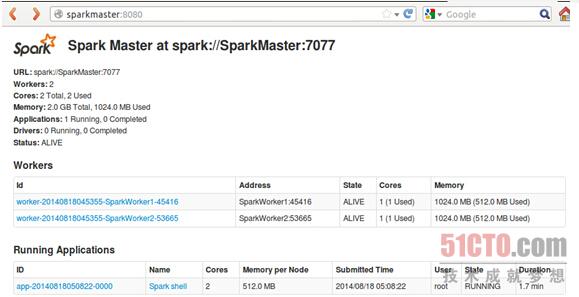
点击作业ID即可查看Spark shell运行信息:
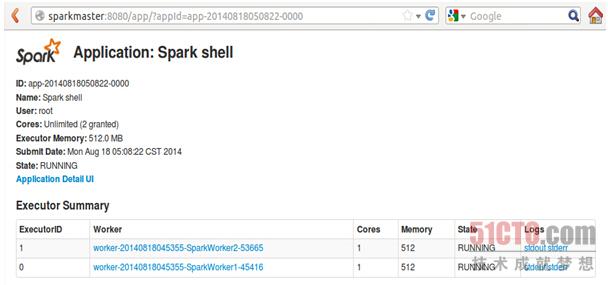
下面我们就开始在集群上通过读取hdfs文件的方式来构建graph对象,首先要做的就是引入相关的包,如下所示:
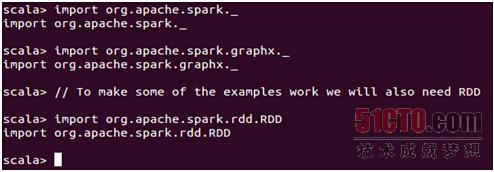
然后通过加载hdfs中的web-Google.txt来构建graph,如下所示:
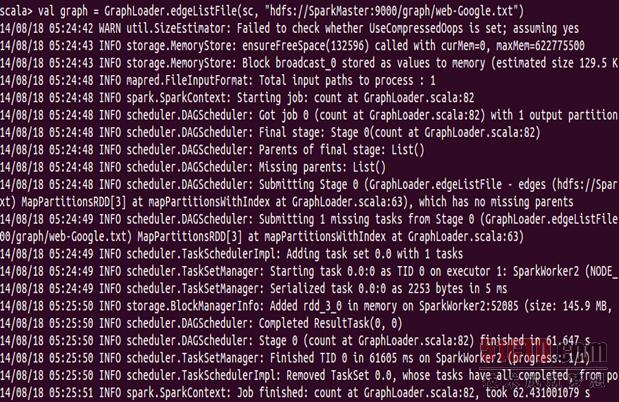
在load的过程中,我们可以看一下Spark shell的web控制台:
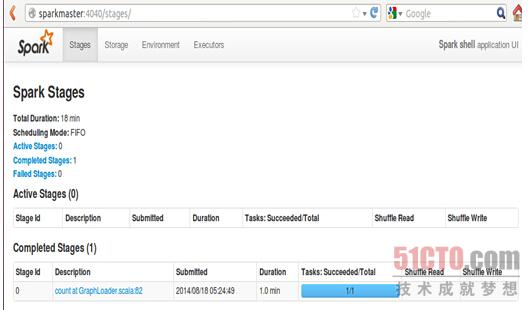
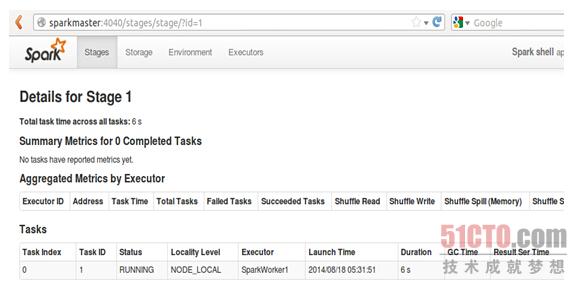
此时我们发现只有一个partition在运行:
本文转自http://book.51cto.com/art/201409/451608.htm,所有权力归原作者所有。
点击作业ID即可查看Spark shell运行信息:
下面我们就开始在集群上通过读取hdfs文件的方式来构建graph对象,首先要做的就是引入相关的包,如下所示:
然后通过加载hdfs中的web-Google.txt来构建graph,如下所示:
在load的过程中,我们可以看一下Spark shell的web控制台:
此时我们发现只有一个partition在运行:
本文转自http://book.51cto.com/art/201409/451608.htm,所有权力归原作者所有。

相关文章推荐
- 序列化那点事
- SharedPreferences的基本用法
- 升级改造项目实施步骤及注意事项
- 买了阿里云之后:挂载新硬盘
- learning sql (second edition) script
- javascript高级程序设计---事件类eventUntil
- Android NDK HelloWorld
- moc简介
- c语言链表《学习记录》
- AIX系统中使用bsdlog函数输出内核信息
- jquery.lazyload.js图片延迟加载
- API--Object,String,Scanner--1
- extern "C"的用法解析
- 利用阿里云提供的镜像快速更换本地的yum源
- RIP协议的配置
- WebView关键点
- Linux下的两个经典宏定义
- 静态分析android代码, 循环与trycatch
- strip_tags() 函数剥去 HTML、XML 以及 PHP 的标签
- 面试都问了些什么及解答