Kinect v2.0原理介绍之三:骨骼跟踪的原理
2015-07-12 12:11
295 查看
~~有兴趣的小伙伴,加kinect算法交流群:462964980。
生成3D深度的图像的原理
4、Kinect骨骼跟踪的原理
下面更加详细的来探讨一下骨骼跟踪的原理:
Kinect骨骼跟踪不受周围光照的影响,主要是因为红外信息,产生3D深度图像,上文已经介绍。
另外,Kinect采用分隔策略将人体从复杂的背景中区分出来,在这个阶段,为每个跟踪的人在深度图像中创建所谓的分割遮罩(分割遮罩为了排除人体以外背景图像,采取的图像分割的方法),如图1这是一个将背景图像(比如椅子和宠物等)剔除后的景深图像。在后面的处理流程中仅仅转送人体图像即可,以减轻体感计算量。

Kinect需做的下一件事情就是寻找图像中较可能是人体的物体,接下来kinect会对景深图像(机器学习)进行评估,来判别人体的不同部位。
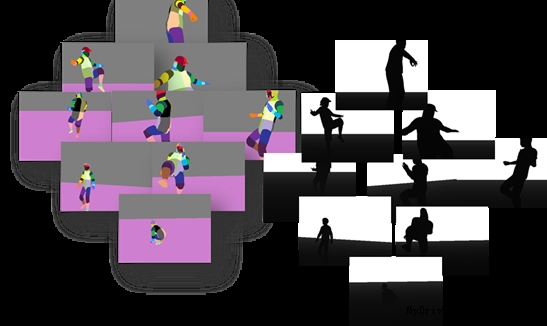
在识别人体的各部位之前,微软是通过开发的一个人工智能(被称为Exemplar(模型)系统),数以TB计的数据输入到集群系统训练模型,图2就是用来训练和测试Exemplar的数据之一。
训练分类器的分方法,提出的是一种含有许多深度特征的分类器,来识别物体,该特征虽然简单却包含必要的信息,来确定身体的部位,其公式如(1)所示:
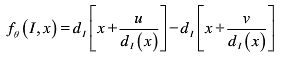
···········(1)
其中x是像素值,d1(x)是像素值在图像I中的深度值,参数θ=(u,v),u和v是一对偏移向量(怎么理解?),1/d1(x)是偏移正规化,用来处理人体尺寸的缩放,这是一个非常简单的特征,也就是简化目标像素u和v值这两个像素深度偏移的不同。很显然,这些特征测量与像素周围的区域的3D外形相关,这足以说明手臂和腿之间的区别。如图3所示,其中十字架代表被像素被分的类别,而圆圈表示公式(1)计算出的偏移像素。若偏移像素是背景,d1(x)深度值将会是正无穷大。
a、两个具有较大响应的特征
b、两个具有较小响应值的特征
图3 深度图像特征
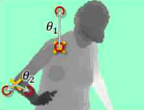
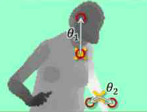
接下来训练一个决策树分类器。决策树森林即众多决策树的集合,每棵树用一组预先标签的身体部位的深度图像来训练,决策树被修改更新,知道决策树为特定的身体部位上的测试集的图像给出了正确的分类。用100w幅图像训练3颗数,利用GPU加速,在1000个核的集群去分析。根据微软实验,大概耗时一天。这些训练过的分类器指定每一个像素在每一个身体部分的可能性。下一个阶段的算法简单的为每一个身体部位挑选最大几率的区域。因此,如果“手臂”分类器是最大的几率,这个区域则被分配到“手臂”类别。最后一个阶段是计算分类器建议的关节位置(节点)相对位置作为特别的身体部位,如图4所示。
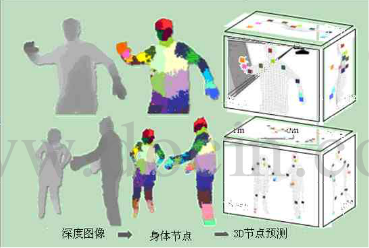
图4 Kinect 人体节点识别过程

图5 骨骼跟踪结果
模型匹配:生成骨架的系统
处理流程的最后一步是使用之前阶段输出的结果,根据追踪到的20个关节点来生成一幅骨架系统。Kinect会评估Exemplar输出的每一个可能的像素来确定关节点。通过这种方式Kinect能够基于充分的信息最准确地评估人体实际所处位置。另外模型匹配阶段还做了一些附加输出滤镜来平滑输出以及处理闭塞关节等特殊事件。
参考资料:
Shotton J, Sharp T, Kipman A, et al. Real-time human pose recognition in parts from single depth images[J]. Communications of the ACM, 2013, 56(1): 116-124.
如果帮到你了,请赞赏支持:

生成3D深度的图像的原理
采用的是PrimeSence公司Light Coding技术。Light Coding技术理论是利用连续光(近红外线)对测量空间进行编码,经感应器读取编码的光线,交由晶片运算进行解码后,产生成一张具有深度的图像。 Light Coding技术的关键是Laser Speckle雷射光散斑,当雷射光照射到粗糙物体、或是穿透毛玻璃后,会形成随机的反射斑点,称之为散斑。散斑具有高度随机性,也会随着距离而变换图案,空间中任何两处的散斑都会是不同的图案,等于是将整个空间加上了标记,所以任何物体进入该空间、以及移动时,都可确切纪录物体的位置。Light Coding发出雷射光对测量空间进行编码,就是指产生散斑。Kinect就是以红外线发出人眼看不见的class 1雷射光,透过镜头前的diffuser(光栅、扩散片)将雷射光均匀分布投射在测量空间中,再透过红外线摄影机记录下空间中的每个散斑,撷取原始资料后,再透过晶片计算成具有3D深度的图像。
4、Kinect骨骼跟踪的原理
了解Kinect如何获得影像后,接下来就是进行辨识的工作。透过Light Coding技术所获得的只是基本的影像资料,重点还是要辨识影像,转换为动作指令。 微软将侦测到的3D深度图像,转换到骨架追踪系统。该系统最多可同时侦测到6个人,包含同时辨识2个人的动作;每个人共可记录20组细节,包含躯干、四肢以及手指等都是追踪的范围,达成全身体感操作。为了看懂使用者的动作,微软也用上机器学习技术(machine learning),建立出庞大的图像资料库,形成智慧辨识能力,尽可能理解使用者的肢体动作所代表的涵义。
下面更加详细的来探讨一下骨骼跟踪的原理:
Kinect骨骼跟踪不受周围光照的影响,主要是因为红外信息,产生3D深度图像,上文已经介绍。
另外,Kinect采用分隔策略将人体从复杂的背景中区分出来,在这个阶段,为每个跟踪的人在深度图像中创建所谓的分割遮罩(分割遮罩为了排除人体以外背景图像,采取的图像分割的方法),如图1这是一个将背景图像(比如椅子和宠物等)剔除后的景深图像。在后面的处理流程中仅仅转送人体图像即可,以减轻体感计算量。
图1 剔除背景后的景深图像
Kinect需做的下一件事情就是寻找图像中较可能是人体的物体,接下来kinect会对景深图像(机器学习)进行评估,来判别人体的不同部位。
在识别人体的各部位之前,微软是通过开发的一个人工智能(被称为Exemplar(模型)系统),数以TB计的数据输入到集群系统训练模型,图2就是用来训练和测试Exemplar的数据之一。
图2 测试和训练数据
训练分类器的分方法,提出的是一种含有许多深度特征的分类器,来识别物体,该特征虽然简单却包含必要的信息,来确定身体的部位,其公式如(1)所示:
···········(1)
其中x是像素值,d1(x)是像素值在图像I中的深度值,参数θ=(u,v),u和v是一对偏移向量(怎么理解?),1/d1(x)是偏移正规化,用来处理人体尺寸的缩放,这是一个非常简单的特征,也就是简化目标像素u和v值这两个像素深度偏移的不同。很显然,这些特征测量与像素周围的区域的3D外形相关,这足以说明手臂和腿之间的区别。如图3所示,其中十字架代表被像素被分的类别,而圆圈表示公式(1)计算出的偏移像素。若偏移像素是背景,d1(x)深度值将会是正无穷大。
a、两个具有较大响应的特征
b、两个具有较小响应值的特征
图3 深度图像特征
接下来训练一个决策树分类器。决策树森林即众多决策树的集合,每棵树用一组预先标签的身体部位的深度图像来训练,决策树被修改更新,知道决策树为特定的身体部位上的测试集的图像给出了正确的分类。用100w幅图像训练3颗数,利用GPU加速,在1000个核的集群去分析。根据微软实验,大概耗时一天。这些训练过的分类器指定每一个像素在每一个身体部分的可能性。下一个阶段的算法简单的为每一个身体部位挑选最大几率的区域。因此,如果“手臂”分类器是最大的几率,这个区域则被分配到“手臂”类别。最后一个阶段是计算分类器建议的关节位置(节点)相对位置作为特别的身体部位,如图4所示。
图4 Kinect 人体节点识别过程
另外,只要有大字形的物体,Kinect都会努力去追踪,如图5所示。当然,这个物体也必须是接近人体的大小比例,尺寸小的玩具是无法识别的。
图5 骨骼跟踪结果
在Kinect前放一个没有体温的塑料人体模特,或者一件挂着衬衣的衣架,Kinect会认为那是一个静止的人。红外传感器所能捕捉的只是一个人体轮廓。
模型匹配:生成骨架的系统
处理流程的最后一步是使用之前阶段输出的结果,根据追踪到的20个关节点来生成一幅骨架系统。Kinect会评估Exemplar输出的每一个可能的像素来确定关节点。通过这种方式Kinect能够基于充分的信息最准确地评估人体实际所处位置。另外模型匹配阶段还做了一些附加输出滤镜来平滑输出以及处理闭塞关节等特殊事件。
参考资料:
Shotton J, Sharp T, Kipman A, et al. Real-time human pose recognition in parts from single depth images[J]. Communications of the ACM, 2013, 56(1): 116-124.
如果帮到你了,请赞赏支持:

相关文章推荐
- Kinect v2.0原理介绍之二:6种数据源
- Kinect for Windows V2和V1对比开发___骨骼数据获取并用OpenCV2.4.10显示
- Kinect for Windows V2和V1对比开发___彩色数据获取并用OpenCV2.4.10显示
- Kinect v2.0原理介绍之十:获取高清面部帧的AU单元特征保存到文件
- Kinect v2.0原理介绍之四:人脸跟踪探讨
- MVC两个必懂核心
- "Permission denied: '/usr/local/man/man1/nosetests.1'"解决方法
- C++ Primer 学习笔记_98_特殊的工具和技术 --优化内存分配
- 学习笔记-NoSQL
- EFM8单片机与I2C外设通信
- Spring笔记之配置数据源
- Ubuntu安装JDK
- 效率较高的Oracle数据库之间数据同步(非dblink)
- Visual Studio技巧集锦
- POJ 3169 Layout(差分约束-Bellman-Ford)
- 世界头号黑客“米特尼克”对生活的见解自述
- CUDA学习笔记(二)【转】
- C语言+二维数组+非递归实现扫雷游戏(代码贴过来后无缩进,尽请谅解,工程完成度:85%)
- java dos
- 【SSH 基金会】SSH框架--struts进一步的详细解释(两)