flask_sqlalchemy笔记1
2015-07-12 10:38
561 查看
flask就不多介绍了,是python写的一个拓展性极强的微框架,目前正在学习,
sqlalchemy一个数据库的抽象层,它在上层可以提供统一的接口,在底层则可以对不同的数据库进行操作,所以是个很棒的中间人。
目前使用的1.06版本,以下是它的整体框架图:
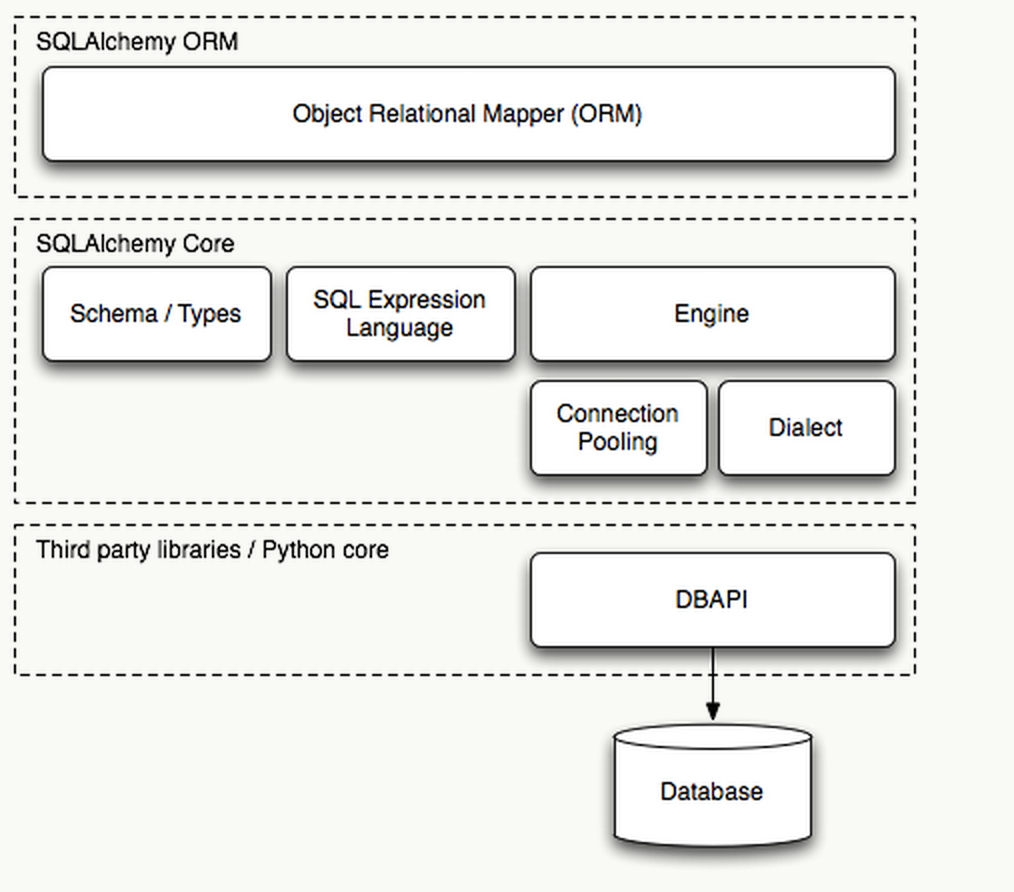
正常情况下,我们都是在ORM层面进行数据库的操作,但是如果访问量太大,并且还要追求访问效率的话,可以进入sqlalchemy核心操作数据库,这样,在拥有sqlalchemy的诸多优点的同时,你还可以提高效率。当然,从图中可以看出sqlalchemy就是充当开发者和数据库之间的中间人的角色,Database可以随意,但是上层的操作逻辑是一致的。这里我们只谈ORM层面对数据库的操作,因为core层面我没看。
建立数据库:
表间关系:
多对一:
在插入数据时,首先应该插入son的数据,然后通过会话add(),然后flush(),只有这样,son的数据才会产生id,这样才能把son_id传入Person中。最后统一commit()
一对多:
一对一[b](以下都不再详细举例了):[/b]
只要在relationship函数中加上uselist=False属性即可,系统会自动判断
多对多(通过第三张表连接):
查询操作:
k=db_session.query(Person).filter(Person.name=='wu').first()
a=db_session.query(Son).filter(Son.age==32).all()
k是一个对象,a则是一个迭代器,
关联表的查询:a=db_session.query(Person).join(Son).filter(Son.age==32).all()。
query()中的对象就是想要查询的对象
如:query(Person)---->返回Person对象
query(Person.name)----->返回Person.name的数据
sqlalchemy一个数据库的抽象层,它在上层可以提供统一的接口,在底层则可以对不同的数据库进行操作,所以是个很棒的中间人。
目前使用的1.06版本,以下是它的整体框架图:
正常情况下,我们都是在ORM层面进行数据库的操作,但是如果访问量太大,并且还要追求访问效率的话,可以进入sqlalchemy核心操作数据库,这样,在拥有sqlalchemy的诸多优点的同时,你还可以提高效率。当然,从图中可以看出sqlalchemy就是充当开发者和数据库之间的中间人的角色,Database可以随意,但是上层的操作逻辑是一致的。这里我们只谈ORM层面对数据库的操作,因为core层面我没看。
建立数据库:
from sqlalchemy import Column,Integer,String
#from database import Base
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session,sessionmaker
#engine是application数据库操作的起点
engine=create_engine('sqlite:///yedan.db',echo=True)
#db_session通过scope_session()d的调用,变成一个类似的全局变量(通过db_session实例化的对象是同一个对象),访问数据库只需要调用它即可
#通过scope_session()可以无需担心多线程操作数据库,只需要在request访问结束的时候remove这个全局db_session即可
db_session=scoped_session(sessionmaker(autocommit=False,autoflush=False,bind=engine))
#一个创建一个表的元类,给新创建的表提供恰当的映射,新创建的表都需要继承它
Base=declarative_base()
#通过base_query可以查询数据库
Base.query=db_session.query_property()
#Session=sessionmaker()
class Person(Base):
#命名表
__tablename__='pers'
id =Column(Integer,primary_key=True)
name=Column(String(80),unique=True)
email=Column(String(100),unique=True)def __repr__(self):
return '<Person %r>'%(self.name)
#创建表,
Base.metadata.create_all(bind=engine)表间关系:
多对一:
from sqlalchemy import Column,Integer,String,ForeignKey
#from database import Base
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session,sessionmaker,relationship
engine=create_engine('sqlite:///dan.db',echo=True)
db_session=scoped_session(sessionmaker(autocommit=False,autoflush=False,bind=engine))
Base=declarative_base()
Base.query=db_session.query_property()
Session=sessionmaker()
#多对一
14 class Person(Base):
15 __tablename__='pe'
16 id =Column(Integer,primary_key=True)
17 name=Column(String(80),unique=True)
18 email=Column(String(100),unique=True)
19 son=relationship("Son",backref="persons")
20 son_id=Column(Integer,ForeignKey('son.id'))
def __repr__(self):
return '<Person %r>'%(self.name)
class Son(Base):
30
31 __tablename__='son'
32 id =Column(Integer,primary_key=True)
33 #per_id=Column(Integer,ForeignKey('Person.id'))
34 age=Column(Integer,unique=True)
def __init__(self,age):
self.age=age
def __repr__(self):
return "<Son %r>" %self.age
Base.metadata.create_all(bind=engine)在插入数据时,首先应该插入son的数据,然后通过会话add(),然后flush(),只有这样,son的数据才会产生id,这样才能把son_id传入Person中。最后统一commit()
一对多:
from sqlalchemy import Column,Integer,String,ForeignKey
#from database import Base
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session,sessionmaker,relationship
engine=create_engine('sqlite:///ye.db',echo=True)
db_session=scoped_session(sessionmaker(autocommit=False,autoflush=False,bind=engine))
Base=declarative_base()
Base.query=db_session.query_property()
Session=sessionmaker()
#多对一
class Person(Base):
__tablename__='pe'
id =Column(Integer,primary_key=True)
name=Column(String(80),unique=True)
email=Column(String(100),unique=True)
son=relationship("Son",backref="person")
def __init__(self,name,email):
self.name=name
self.email=email
#self.son_id=son_id
def __repr__(self):
return '<Person %r>'%(self.name)
class Son(Base):
__tablename__='son'
id =Column(Integer,primary_key=True)
age=Column(Integer,unique=False)
#外键需要关联其他表的id
person_id=Column(Integer,ForeignKey('pe.id'))
def __init__(self,age,person_id):
self.age=age
self.person_id=person_id
def __repr__(self):
return "<Son %r>" %self.age
Base.metadata.create_all(bind=engine)一对一[b](以下都不再详细举例了):[/b]
只要在relationship函数中加上uselist=False属性即可,系统会自动判断
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
child_id = Column(Integer, ForeignKey('child.id'))
child = relationship("Child", backref=backref("parent", uselist=False))
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)多对多(通过第三张表连接):
association_table = Table('association', Base.metadata,
Column('left_id', Integer, ForeignKey('left.id')),
Column('right_id', Integer, ForeignKey('right.id'))
)
class Parent(Base):
__tablename__ = 'left'
id = Column(Integer, primary_key=True)
children = relationship("Child",
secondary=association_table,
backref="parents")
class Child(Base):
__tablename__ = 'right'
id = Column(Integer, primary_key=True)查询操作:
k=db_session.query(Person).filter(Person.name=='wu').first()
a=db_session.query(Son).filter(Son.age==32).all()
k是一个对象,a则是一个迭代器,
关联表的查询:a=db_session.query(Person).join(Son).filter(Son.age==32).all()。
query()中的对象就是想要查询的对象
如:query(Person)---->返回Person对象
query(Person.name)----->返回Person.name的数据

相关文章推荐
- 数据库连接工具-Navicat
- 海量数据处理之数据库索引
- Linux源码安装memcached
- 海量数据处理之数据库索引
- sql使用row_number()查询标记行号
- SQL2008--SQL语句-存储过程-触发器-事务处理-基本语法-函数
- SQL2008-分页显示3种方法
- SQL2008-表对表直接复制数据
- SQL2008-删除时间字段重复的方法
- SQL2008-中不想插入从复记录
- 数据库之事务并发问题与事务的隔离级别
- SQL2008-c:\PROGRA~1\COMMON~1\System\OLEDB~1\oledb32.dll出错找不到指定的模块
- ACCESS-如何多数据库查询(跨库查询)
- django with mysql (part-2)
- Oracle-PLSQL Developer使用笔记
- Oracle-Oracle10 数据空间建立,导入,导出--oracle10g 删除步骤
- Oracle-数据实现竖排打印
- django with mysql (part-1)
- Ubuntu 14.04---Nginx+uWsgi+Django+Python+MongoDB
- MongoDB系列二