海量数据处理之数据库索引
2015-07-12 10:29
176 查看
第一部分,数据库索引及其优化
一,什么是索引
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。例如这样一个查询:select * from table1 where id=44。如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。可见,索引是用来定位的。
索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;显然在一个基本表上最多只能建立一个聚簇索引。建立聚簇索引后,更新该索引列上的数据时,往往导致表中记录的物理顺序的变更,代价较大,因此对于经常更新得列不宜建立聚簇索引,聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。建立一个聚簇索引如:
create cluster index id on Student(id);
二,概述
建立索引的目的是加快对表中记录的查找或排序。为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
精简来说,索引是一种结构.在SQL Server中,索引和表(这里指的是加了聚集索引的表)的存储结构是一样的,都是B树,B树是一种用于查找的平衡多叉树.理解B树的概念如下图:
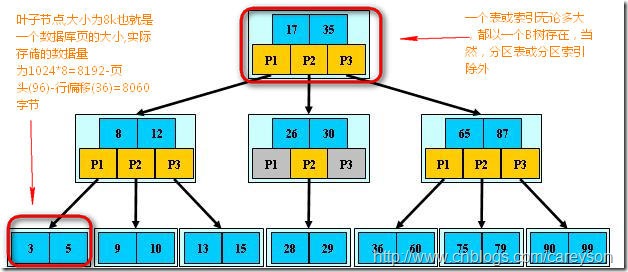
理解为什么使用B树作为索引和表(有聚集索引)的结构,首先需要理解SQL Server存储数据的原理.
在SQL SERVER中,存储的单位最小是页(PAGE),页是不可再分的。就像细胞是生物学中不可再分的,或是原子是化学中不可再分的最小单位一样.这意味着,SQL SERVER对于页的读取,要么整个读取,要么完全不读取,没有折中.
在数据库检索来说,对于磁盘IO扫描是最消耗时间的.因为磁盘扫描涉及很多物理特性,这些是相当消耗时间的。所以B树设计的初衷是为了减少对于磁盘的扫描次数。如果一个表或索引没有使用B树(对于没有聚集索引的表是使用堆heap存储),那么查找一个数据,需要在整个表包含的数据库页中全盘扫描。这无疑会大大加重IO负担.而在SQL SERVER中使用B树进行存储,则仅仅需要将B树的根节点存入内存,经过几次查找后就可以找到存放所需数据的被叶子节点包含的页!进而避免的全盘扫描从而提高了性能.
下面,通过一个例子来证明:
在SQL SERVER中,表上如果没有建立聚集索引,则是按照堆(HEAP)存放的,假设我有这样一张表:

现在这张表上没有任何索引,也就是以堆存放,我通过在其上加上聚集索引(以B树存放)来展现对IO的减少:

三、理解聚集索引和非聚集索引
在SQL SERVER中,最主要的两类索引是聚集索引和非聚集索引。可以看到,这两个分类是围绕聚集这个关键字进行的.那么首先要理解什么是聚集.聚集在索引中的定义:
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚集码)上具有相同值的元组集中存放在连续的物理块称为聚集。
简单来说,聚集索引就是:

在SQL SERVER中,聚集的作用就是将某一列(或是多列)的物理顺序改变为和逻辑顺序相一致,比如,我从adventureworks数据库的employee中抽取5条数据:

当我在ContactID上建立聚集索引时,再次查询:

在SQL SERVER中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:

因为聚集索引改变的是其所在表的物理存储顺序,所以每个表只能有一个聚集索引.
非聚集索引
因为每个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于在聚集索引上的字段。我们又对聚集索引列之外还有索引的要求,那么就需要非聚集索引了.非聚集索引,本质上来说也是聚集索引的一种.非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶子节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号。如果其所在表上已经有了聚集索引,则引用聚集索引的页.
一个简单的非聚集索引概念如下:

可以看到,非聚集索引需要额外的空间进行存储,按照被索引列进行聚集索引,并在B树的叶子节点包含指向非聚集索引所在表的指针.
MSDN中,对于非聚集索引描述图是:

可以看到,非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.
通过非聚集索引的原理可以看出,如果其所在表的物理结构改变后,比如加上或是删除聚集索引,那么所有非聚集索引都需要被重建,这个对于性能的损耗是相当大的。所以最好要先建立聚集索引,再建立对应的非聚集索引.
聚集索引 VS 非聚集索引
前面通过对于聚集索引和非聚集索引的原理解释.我们不难发现,大多数情况下,聚集索引的速度比非聚集索引要略快一些.因为聚集索引的B树叶子节点直接存储数据,而聚集索引还需要额外通过叶子节点的指针找到数据.还有,对于大量连续数据查找,非聚集索引十分乏力,因为非聚集索引需要在非聚集索引的B树中找到每一行的指针,再去其所在表上找数据,性能因此会大打折扣.有时甚至不如不加非聚集索引.
因此,大多数情况下聚集索引都要快于非聚集索引。但聚集索引只能有一个,因此选对聚集索引所施加的列对于查询性能提升至关紧要.

相关文章推荐
- Linux源码安装memcached
- 海量数据处理之数据库索引
- sql使用row_number()查询标记行号
- SQL2008--SQL语句-存储过程-触发器-事务处理-基本语法-函数
- SQL2008-分页显示3种方法
- SQL2008-表对表直接复制数据
- SQL2008-删除时间字段重复的方法
- SQL2008-中不想插入从复记录
- 数据库之事务并发问题与事务的隔离级别
- SQL2008-c:\PROGRA~1\COMMON~1\System\OLEDB~1\oledb32.dll出错找不到指定的模块
- ACCESS-如何多数据库查询(跨库查询)
- django with mysql (part-2)
- Oracle-PLSQL Developer使用笔记
- Oracle-Oracle10 数据空间建立,导入,导出--oracle10g 删除步骤
- Oracle-数据实现竖排打印
- django with mysql (part-1)
- Ubuntu 14.04---Nginx+uWsgi+Django+Python+MongoDB
- MongoDB系列二
- MySQL之alter语句用法总结
- Ubuntu OracleJDK离线安装教程