暴力拆解hupu球员信息
2015-07-11 00:44
211 查看
之前写了一个拉取nba球员的脚本,是针对hupu网站上的数据进行拉取。由于水平一般,代码写的简单粗暴
hupu球队\球员信息的链接可以看到球员球队信息。爬出所有球队的链接
teamList = []
response = urllib2.urlopen("http://g.hupu.com/nba/players/")
html = response.read()
def getTeams():
Items = re.findall('<span class="team_name"><a href=".*?</a></span>',html,re.S)
for item in Items:
link = item.replace('<span class="team_name"><a href="','')
team = re.findall('">.*?</a></span>',link,re.S)[0]
link = 'http://g.hupu.com/'+link.replace(team,'')
team = team.replace('">','').replace('</a></span>','')
teamList.append(teamLink(team,link))然后再爬出每个球员的详细页面
for team in teamList: getPlayers(team)
并且获得数据,存入数据库
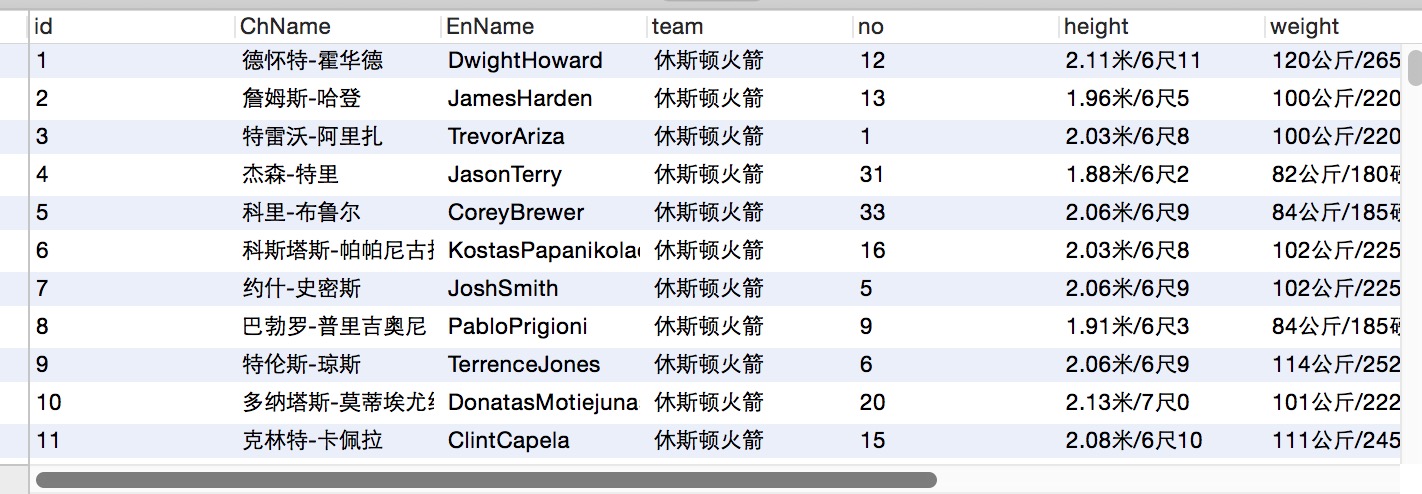
github链接https://github.com/Leon1Sun/TestPython

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- NodeJS制作爬虫全过程(续)
- 一个PHP实现的轻量级简单爬虫
- nodejs爬虫抓取数据乱码问题总结
- nodejs爬虫抓取数据之编码问题
- 零基础写Java知乎爬虫之抓取知乎答案
- 零基础写Java知乎爬虫之先拿百度首页练练手
- 零基础写Java知乎爬虫之获取知乎编辑推荐内容
- Python编写百度贴吧的简单爬虫
- 零基础写python爬虫之使用urllib2组件抓取网页内容
- 零基础写python爬虫之抓取百度贴吧代码分享
- 零基础写python爬虫之urllib2使用指南
- python利用beautifulSoup实现爬虫
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- 零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers
- 在Python3中使用asyncio库进行快速数据抓取的教程
- 零基础写python爬虫之抓取糗事百科代码分享
- 零基础写Java知乎爬虫之进阶篇
- 简单的Python抓taobao图片爬虫