IntelliJ IDEA开发Spark1.4.0环境部署
2015-07-09 10:09
375 查看
1:IDEA的安装
官网jetbrains.com下载IntelliJ IDEA,有Community Editions 和& Ultimate Editions,前者免费,用户可以选择合适的版本使用。
根据安装指导安装IDEA后,需要安装scala插件,有两种途径可以安装scala插件:
启动IDEA -> Welcome to IntelliJ IDEA -> Configure -> Plugins -> Install JetBrains plugin... -> 找到scala后安装。
启动IDEA -> Welcome to IntelliJ IDEA -> Open Project -> File -> Settings -> plugins -> Install JetBrains plugin... -> 找到scala后安装。
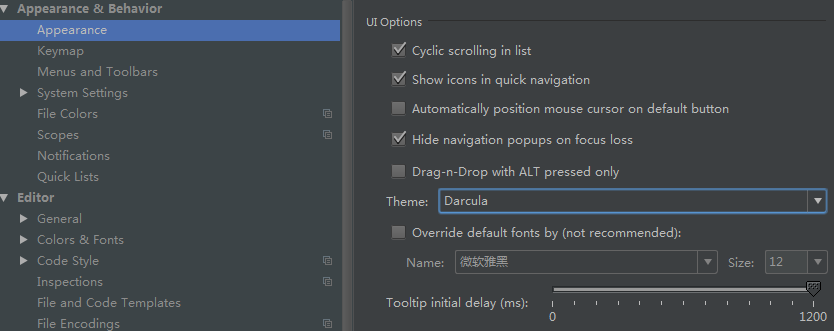
如果你想使用那种酷酷的黑底界面,在File -> Settings -> Appearance -> Theme选择Darcula,同时需要修改默认字体,不然菜单中的中文字体不能正常显示。
2:建立Spark应用程序
下面讲述如何建立一个Spark项目week2,该项目包含3个object:
取自spark examples源码中的SparkPi
计词程序WordCount1
计词排序程序WordCount2
A:建立新项目
创建名为dataguru的project:启动IDEA -> Welcome to IntelliJ IDEA -> Create New Project -> Scala -> Non-SBT -> 创建一个名为week2的project(注意这里选择自己安装的JDK和scala编译器) -> Finish。
设置week2的project structure
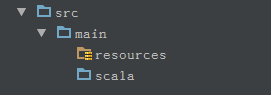
增加源码目录:File -> Project Structure -> Medules -> week2,给week2创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。
增加开发包:File -> Project Structure -> Libraries -> + -> java -> 选择
/app/hadoop/spark100/lib/spark-assembly-1.4.0-hadoop2.6.0.jar
/app/scala2104/lib/scala-library.jar可能会提示错误,可以根据fix提示进行处理
B:编写代码
在源代码scala目录下创建1个名为week2的package,并增加3个object(SparkPi、WordCoun1、WordCount2):
C:生成程序包
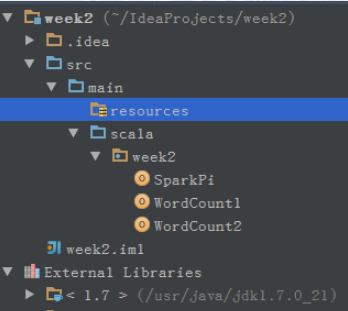
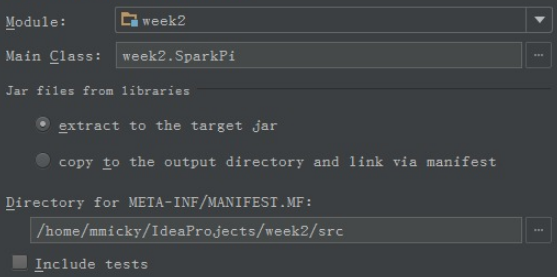
生成程序包之前要先建立一个artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然后随便选一个class作为主class。
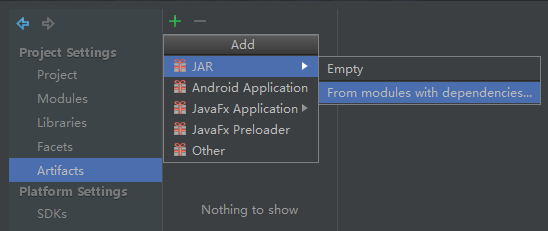
对artifacts进行配置,修改Name为week2,删除Output
Layout中week2.jar中的几个依赖包,只剩week2项目本身。
Build
-> Build Artifacts -> week2 -> rebuild进行打包,经过编译后,程序包放置在out/artifacts/week2目录下,文件名为week2.jar。
官网jetbrains.com下载IntelliJ IDEA,有Community Editions 和& Ultimate Editions,前者免费,用户可以选择合适的版本使用。
根据安装指导安装IDEA后,需要安装scala插件,有两种途径可以安装scala插件:
启动IDEA -> Welcome to IntelliJ IDEA -> Configure -> Plugins -> Install JetBrains plugin... -> 找到scala后安装。
启动IDEA -> Welcome to IntelliJ IDEA -> Open Project -> File -> Settings -> plugins -> Install JetBrains plugin... -> 找到scala后安装。
如果你想使用那种酷酷的黑底界面,在File -> Settings -> Appearance -> Theme选择Darcula,同时需要修改默认字体,不然菜单中的中文字体不能正常显示。
2:建立Spark应用程序
下面讲述如何建立一个Spark项目week2,该项目包含3个object:
取自spark examples源码中的SparkPi
计词程序WordCount1
计词排序程序WordCount2
A:建立新项目
创建名为dataguru的project:启动IDEA -> Welcome to IntelliJ IDEA -> Create New Project -> Scala -> Non-SBT -> 创建一个名为week2的project(注意这里选择自己安装的JDK和scala编译器) -> Finish。
设置week2的project structure
增加源码目录:File -> Project Structure -> Medules -> week2,给week2创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。
增加开发包:File -> Project Structure -> Libraries -> + -> java -> 选择
/app/hadoop/spark100/lib/spark-assembly-1.4.0-hadoop2.6.0.jar
/app/scala2104/lib/scala-library.jar可能会提示错误,可以根据fix提示进行处理
B:编写代码
在源代码scala目录下创建1个名为week2的package,并增加3个object(SparkPi、WordCoun1、WordCount2):
C:生成程序包
生成程序包之前要先建立一个artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然后随便选一个class作为主class。
对artifacts进行配置,修改Name为week2,删除Output
Layout中week2.jar中的几个依赖包,只剩week2项目本身。
Build
-> Build Artifacts -> week2 -> rebuild进行打包,经过编译后,程序包放置在out/artifacts/week2目录下,文件名为week2.jar。

相关文章推荐
- Deep Belief Networks
- 搭建Nginx+Tomcat 负载均衡集群
- Uva11300 - Spreading the Wealth
- 疯狂java讲义之泛型
- git基本命令
- Linux 2>&1
- json使用小结
- java数据结构之选择排序
- C 字符数组 字符指针
- 7月5日28家中国域名商六类国际域名注册保有量统计
- SSMA 数据库迁移工具
- SQL server SQL 语句收集--持续更新
- uva--10163(dp,01背包,双肩包)
- VS2008 将资源释放到文件
- 【python】命令参执行程序的开发利器--getopt模块
- 编码风格一:如何取好变量名
- day5 -指针
- Extjs.panel.Panel赋值的问题
- 欢迎使用CSDN-markdown编辑器
- python简单猜数游戏实例