Python正则表达式-2
2015-07-08 13:37
766 查看
本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例。本文的内容不包括如何编写高效的正则表达式、如何优化正则表达式,这些主题请查看其他教程。
注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
尊重作者的劳动,转载请注明作者及原文地址 >.<html
最短匹
下图展示了使用正则表达式进行匹配的流程:
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:

Jeffrey: 我加一点自己做项目过程中遇到的这种匹配方式的理解:
最短匹配:.*? http://deerchao.net/tutorials/regex/regex.htm
假如,我们有以下的代码存放在Test_1.xml中(注意:这里不仅限于xml文件,同样的也适应于其它的任何的文件):我们的
源文件:
<Request Action="LOGIN" RequestId="100000"><Authentication><ClientName>Administrator</ClientName><Password>5420!Cts</Password></Authentication></Request><?xml version="1.0" encoding="UTF-8"?><Response Status="OKAY" RequestId="100000"><Authentication MajorVersion="28"
MinorVersion="0"><ClientName>Administrator</ClientName><Role>ADMINISTRATOR</Role></Authentication></Response><Request Action="UPDATE" RequestId="100000"><CapacityLimit><Category>RESIDENTIALSUBSCRIBER_R2</Category><LockKey>17ylvJrPbcGgHEUPF001n//k/v/n//Xu0P//AAb3rb8H=0000050010</LockKey><SignKey>QDA9s+3HukQn3DyX15otQNaOvEQaEU5skCx0JDPQHJ77/jwYQl0uLQUYlKHZWmwKIhGCGWIuz8nADDtXlJK9VA==</SignKey></CapacityLimit></Request><?xml
version="1.0" encoding="UTF-8"?><span style="color:#FF0000;"><Response Status="OKAY" CongLvl="LEVEL0" OverallProvTime="4026852" TimeInReqQueue="228" DbCommitTime="6371" RequestId="100000"> <CapacityParms><Category>RESIDENTIALSUBSCRIBER_R2</Category><FeatureSetName>R1
FEATURE SET</FeatureSetName><OfficeId>ylvJrPbcGgHE</OfficeId><CurrentCnt>0</CurrentCnt><LimitCnt>0000050</LimitCnt><SpareCapacity>0</SpareCapacity><TasUnequalDistribution>0</TasUnequalDistribution> </CapacityParms></Response></span><Request Action="LOGOFF"
RequestId="tll-logoff"><Authentication><ClientName>Administrator</ClientName></Authentication></Request><?xml version="1.0" encoding="UTF-8"?><Response Status="OKAY" RequestId="tll-logoff"><Authentication><ClientName>Administrator</ClientName></Authentication></Response>
上面的代码可以在我的github上找到:https://github.com/double12gzh/PythonLearning
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
注意:本文基于Python2.4完成;如果看到不明白的词汇请记得百度谷歌或维基,whatever。
尊重作者的劳动,转载请注明作者及原文地址 >.<html
最短匹
1. 正则表达式基础
1.1. 简单介绍
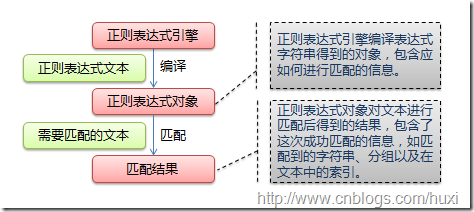
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。下图展示了使用正则表达式进行匹配的流程:
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。Jeffrey: 我加一点自己做项目过程中遇到的这种匹配方式的理解:
最短匹配:.*? http://deerchao.net/tutorials/regex/regex.htm
假如,我们有以下的代码存放在Test_1.xml中(注意:这里不仅限于xml文件,同样的也适应于其它的任何的文件):我们的
要匹配到原文件中的下列内容 <pre name="code" class="html"><span style="color:#FF0000;"><Response Status="OKAY" CongLvl="LEVEL0" OverallProvTime="4026852" TimeInReqQueue="228" DbCommitTime="6371" RequestId="100000"> <CapacityParms> <Category>RESIDENTIALSUBSCRIBER_R2</Category> <FeatureSetName>R1 FEATURE SET</FeatureSetName> <OfficeId>ylvJrPbcGgHE</OfficeId> <CurrentCnt>0</CurrentCnt> <LimitCnt>0000050</LimitCnt> <SpareCapacity>0</SpareCapacity> <TasUnequalDistribution>0</TasUnequalDistribution> </CapacityParms> </Response></span>
源文件:
<Request Action="LOGIN" RequestId="100000"><Authentication><ClientName>Administrator</ClientName><Password>5420!Cts</Password></Authentication></Request><?xml version="1.0" encoding="UTF-8"?><Response Status="OKAY" RequestId="100000"><Authentication MajorVersion="28"
MinorVersion="0"><ClientName>Administrator</ClientName><Role>ADMINISTRATOR</Role></Authentication></Response><Request Action="UPDATE" RequestId="100000"><CapacityLimit><Category>RESIDENTIALSUBSCRIBER_R2</Category><LockKey>17ylvJrPbcGgHEUPF001n//k/v/n//Xu0P//AAb3rb8H=0000050010</LockKey><SignKey>QDA9s+3HukQn3DyX15otQNaOvEQaEU5skCx0JDPQHJ77/jwYQl0uLQUYlKHZWmwKIhGCGWIuz8nADDtXlJK9VA==</SignKey></CapacityLimit></Request><?xml
version="1.0" encoding="UTF-8"?><span style="color:#FF0000;"><Response Status="OKAY" CongLvl="LEVEL0" OverallProvTime="4026852" TimeInReqQueue="228" DbCommitTime="6371" RequestId="100000"> <CapacityParms><Category>RESIDENTIALSUBSCRIBER_R2</Category><FeatureSetName>R1
FEATURE SET</FeatureSetName><OfficeId>ylvJrPbcGgHE</OfficeId><CurrentCnt>0</CurrentCnt><LimitCnt>0000050</LimitCnt><SpareCapacity>0</SpareCapacity><TasUnequalDistribution>0</TasUnequalDistribution> </CapacityParms></Response></span><Request Action="LOGOFF"
RequestId="tll-logoff"><Authentication><ClientName>Administrator</ClientName></Authentication></Request><?xml version="1.0" encoding="UTF-8"?><Response Status="OKAY" RequestId="tll-logoff"><Authentication><ClientName>Administrator</ClientName></Authentication></Response>
这个是我的re_test.py代码文件,这个文件中到了两种匹配方式,当然,只有def re_testsearch()才可以满足我们的要求,因为它是实现的是段落匹配(因为这个里面用了 re.S) #-*- coding:utf-8 -*- #最上一句如果不加上的话不能输入汉字,不然编译不过 #/usr/bin/python import os import sys import re #################################################### # 一行一行的匹配 # 比如Test_2.xml中的内容如下: # <Response Staus="OKAY" CongLvl="jeffrey"> # <a>test1</a> # <b>test2</b> # </Response> # <Response Staus="OKAY" CongLvl="guan"> # <a>test1</a> # <b>test2</b> # </Response> # <Response Staus="OKAY" CongLvl="zenghui"> # <a>test1</a> # <b>test2</b> # </Response> # <Response Staus="OKAY" CongLvl="jeguan"> # <a>test1</a> # <b>test2</b> # </Response> # 那么匹配后的得到结果为 # <Response Staus="OKAY" CongLvl="jeffrey"> # <Response Staus="OKAY" CongLvl="guan"> # <Response Staus="OKAY" CongLvl="zenghui"> # <Response Staus="OKAY" CongLvl="jeguan"> # #################################################### def re_test(): # 原文件 filename = r'C:\Users\jeguan\Desktop\Test_2.xml' # 匹配得到的内容存储在Test_2_bk.xml中 new_file = r'C:\Users\jeguan\Desktop\Test_2_bk.xml' # 打开原文件 open_file = open(filename, 'r') read_file = open_file.readlines() # 打开目标文件,即:存放匹配结果的文件 newfile = open(new_file, 'wb') # 匹配以<Response开头并且有CongLvl字符串的行,注意, # 这里是非lazzy匹配,并且是一行一行匹配,即,遇到 # '\n'就会结束 patt = re.compile(r'^<Response.*CongLvl.*') # 遍历原文件的所有行,如果找到就会存盘 for line in read_file: match = patt.search(line) if match: m = match.group(0) newfile.write(m) open_file.close() newfile.close() ################################################################################# # 多行匹配,即:可以匹配一个文本中的特定段落。这里主要是要用到re模块中的re.S # 它表示当用'.'来进行匹配的时候,可以忽略掉'\n',这一点与'.'正常的规则是不一样的 # # 另外一个要注意的地方是这里使用了Lazzy匹配的方式。当有多个Response>出现的时候, # 它只会匹配第一次出现的地方。比如: # <Response Staus="OKAY" CongLvl="jeguan"> # <a>test1</a> # <b>test2</b> # </Response> # <Response Staus="OKAY" CongLvl="zenghuiguan"> # <a>test3</a> # <b>test4</b> # </Response> # 当用lazzy方式的时候,只会匹配到第一次出现Response>的地方 # 本文中匹配得到的结果为: # <Response Staus="OKAY" CongLvl="jeguan"> # <a>test1</a> # <b>test2</b> # </Response> # ################################################################################ def re_testsearch(): # filename = r'C:\Users\jeguan\Desktop\Test_2.xml' new_file = r'C:\Users\jeguan\Desktop\Test_2_bk.xml' open_file = open(filename, 'r') read_file = open_file.readlines() newfile = open(new_file, 'wb') # re.S means: Make the '.' special character match any character at all, # including a newline; without this flag, '.' will match anything except a newline. # '(.+?)' means: this is a greedy match. When the fist 'Response>' is found, then # it will not try to match the next 'Response>' <span style="color:#CC0000;">patt = re.compile(r'<Response Status="OKAY" CongLvl="LEVEL0"*(.+?)Response>', <strong>re.S</strong>)</span> str1 = "" # 把读出的行放在str1中 for line in read_file: str1 = str1 + line match1 = patt.search(str1) newfile.write(match1.group(0)) print(match1.group()) if __name__ == "__main__": re_testsearch()我们用re_testsearch()这个函数来匹配最终的结果如下所示,得到了我们的要求:
<Response Status="OKAY" CongLvl="LEVEL0" OverallProvTime="4026852" TimeInReqQueue="228" DbCommitTime="6371" RequestId="100 <CapacityParms> <Category>RESIDENTIALSUBSCRIBER_R2</Category> <FeatureSetName>R1 FEATURE SET</FeatureSetName> <OfficeId>ylvJrPbcGgHE</OfficeId> <CurrentCnt>0</CurrentCnt> <LimitCnt>0000050</LimitCnt> <SpareCapacity>0</SpareCapacity> <TasUnequalDistribution>0</TasUnequalDistribution> </CapacityParms> </Response>但是,如果我们使用re_test()来试图匹配的话,不会得到上面的这个结果,相反,只会找到
<Response Status="OKAY" CongLvl="LEVEL0" OverallProvTime="4026852" TimeInReqQueue="228" DbCommitTime="6371" RequestId="100000">
上面的代码可以在我的github上找到:https://github.com/double12gzh/PythonLearning
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。
flags: 编译时用的匹配模式。数字形式。
groups: 表达式中分组的数量。
groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
搜索string,以列表形式返回全部能匹配的子串。
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
返回 (sub(repl, string[, count]), 替换次数)。
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束

相关文章推荐
- Python正则表达式-1
- Python第三方常用工具、库、框架等
- 创业公司都在使用的3款Python库
- python matplotlib绘图
- Win7下使用Sublime Text 3开发及调试Maya Mel和Python
- python中偏函数partial用法实例分析
- Python使用bs4获取58同城城市分类的方法
- Python实现批量修改文件名实例
- Python查询阿里巴巴关键字排名的方法
- python 中xrange 和range的用法区别 以及yield的用法
- 浅谈Python中的闭包
- Python中atexit模块的基本使用示例
- python登录豆瓣并发帖的方法
- python格式化输出(转自White Pillow's Blog)
- python版trace命令显示归属地
- Python下opencv使用笔记(三)(图像的几何变换)
- python友情链接检查方法
- 使用python发送html邮件
- eclipse中python文本字体大小设置
- python:使用OpenSSL