音频信号处理——基音周期
2015-07-02 16:23
381 查看
音频信号处理——基音周期
标签(空格分隔): 音频处理
一、简介
1.1 什么是基音?什么是基音周期
基音顾名思义就是声音的基础。这里我们主要讨论人的发声,根据声带震动的方式的不同,将声音信号分为清音和浊音。其中浊音需要声带周期性震动,所以具有明显的周期性,这种声带振动的频率称为基音频率,相应的周期就成为基音周期。但清音没有明显的周期性。通常,基音频率与个人的声带的结构有很大的关系,所以基因频率也能用于识别发音源。一般来说,男性说话者的基音频率较低,而女性说话者和小孩的基音频率相对较高,就是通常说的“男的声音高,女的声音低”。基音周期的估计称谓基音检测,基音检测的最终目的是为了找出和声带振动频率完全一致或尽可能相吻合的轨迹曲线。
基因周期作为语音信号处理中描述激励源的重要参数之一,在语音合成、语音压缩编码、语音识别和说话人确认等领域都有着广泛而重要的问题,尤其对汉语更是如此。此处省略对汉语识别的突出贡献。
1.2 主要方法
到目前为止,基音检测的方法大致上可以分为三类:1)时域法,直接由语音波形来估计基音周期,常见的有:自相关法、并行处理法、平均幅度差法、数据减少法等;
2)频域法,它是一种将语音信号变换到频域来估计基音周期的方法,首先利用同态分析方法将声道的影响消除,得到属于激励部分的信息,然后求取基音周期,最常用的就是倒谱法,这种方法的缺点就是算法比较复杂,但是基音估计的效果却很好;
3)混合法,先提取信号声道模型参数,然后利用它对信号进行滤波,得到音源序列,最后再利用自相关法或者平均幅度差法求得基因音周期。
下面我们介绍三种基音周期监测方法:基于自相关的基音周期检测,基于倒谱的基音周期监测,基于线性预测编码的基音周期检测。
二、基于自相关的基音周期检测
2.1 自相关函数
能量有限的语音信号x(n)的短时自相关函数定义为:R(m)=∑n=−∞n=+∞x(n)x(n+m)
此公式表示一个信号n和延迟m的相似性。如果信号x(n)具有周期性,那么它的自相关函数也具有周期性,且周期与信号x(n)的周期相同。一般算法都是通过其自相关函数来获得信号周期。因为在周期的整数倍上,自相关函数能获得最大值。这种计算方式不需要考虑语音信号的起始时间,而从自相关函数的最大值就能获得。
2.2 短时自相关函数法
语音信号虽然具有一定的周期性,但是语音信号还是一种非稳态的信号,他的特性还是随时间变化而变化。所以我们将取一段声音片段,这个片段很短,我们可以假设,一个很短的时间段内,信号具有相对稳定的特征即短时平稳性。一般来说,这段时间取,5ms-50ms。应注意的是这里的统计特性和频谱特性都是对短时段而言的。
能量有限的语音信号s(n)的短时自相关函数定义为:
Rn(τ)=∑m=0N−1−τ[s(n+m)w(m)][s(n+m+τ)w(m+τ)]
因为香农定理,一般要求一帧至少包含2个以上周期的信号。一般,基频最低50Hz,故周期最长为20ms。而且相邻帧之间要有足够的重叠。具体应用时,窗口长度根据采样率确定帧长。
三、基于倒谱的基音周期监测
倒谱法是基音周期检测算法之一,它利用语音信号的倒频谱特征,检测出声音的基音信息。传统的倒谱基音检测方法 (Cepstrum based PDA,简称CEP)对于纯净的典型浊音语音 ,可以得到较为精确可靠的结果,但在浊音语音段的边界处及其对被噪声污染的语音,其检测误差大大增加,甚至无法检测。语音基音检测都是基于分帧语音 来实现的 ,但传统的倒谱模型是建立在无限长语音 上的 ,这与实际的分帧语音的倒谱分析显然不符 。 语音加窗分帧后 ,在倒谱域中声门激励倒谱和声道 脉冲响应倒谱不能再简单地认为是基本分离的 ,它 们
1c6ab
之间有明显的混叠 ,二者间的混叠限制了倒谱法 基音检测的精度 。
如果我们假设声音序列是声门激励序列e[n]与声音的离散脉冲序列θ[n]。
s[n]=e[n]∗θ[n]
在频域中,这种卷积关系就变成了相乘的关系。再通过使用AB=logA+logB,使相乘的关系变成相加的关系。最后,
c[n]=12π∫π−πlog∣∣S(ω)∣∣ejnωdω
其中
S(ω)=∑n=−∞∞s[n]e−jωn
倒谱是信号的对数振幅谱的傅里叶分析。如果对数振幅谱包含许多规律的谐波连续序列,声谱的傅里叶分析可以看出在两个谐波的峰值间有间隔。假设我们把信号谱看成一个信号,我们就能从中看出信号谱的周期性。
之所以这个过程叫做倒谱是因为它们将信号谱的内在信息表现出来(inside-out)。倒谱的X轴表示的频率,倒谱的峰值(声谱具有周期性)叫做谐波。为了从倒谱获得基础频率,我们可以通过计算拟频率(quefrency)的峰值来获得声波频域频域(1/quefrency)。
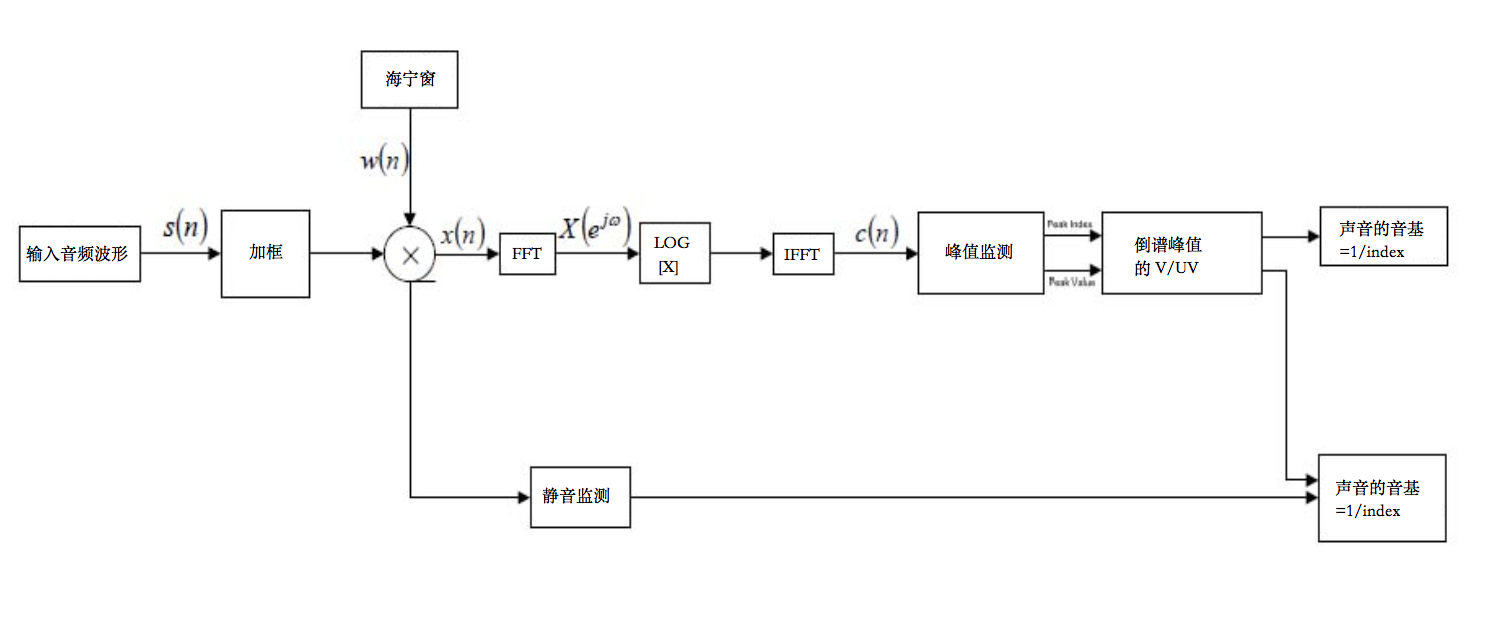
倒谱分析能分离发生声源和声道滤波器。声音信号可以看成声源和声道滤波器的结合。倒谱分析就是对这两个信号的反卷积。倒谱的高频部分包含了基音周期的峰值信息。上图显示了倒谱基音检测算法的流程图。倒谱的峰值和他对应的频率(在60Hz-500Hz)应和自相关算法一样。如果峰值超出了阈值,那么这部分声音被认为是声音,基音周期就是峰值的对应值。如果峰值没有超过阈值,那么就是有交叉零点( a zero-crossing count)。如果这个交叉零点超出了一个给定阈值,那么这个窗口内就不是声音。不同于自相关基音监测算法只能用低频声音频率,倒谱基音检测计算全谱音频。
四、基于线性预测编码的共振峰检测
pitch是人的喉部发出浊音的时候的震动频率,反映在时域信号中是浊音部分最小周期的倒数。因此,可以这么求:
1)one frame of waveform in voiced segment->windowing,pre-emphasize->FFT->功
率谱这时候如果你看这个功率谱的话,它就是跟Cooledit里面可以显示的一样的语谱图。它包括两个部分,一部分是变化非常快的(在语谱图上是横的均匀条纹),另外一部
分是比较缓慢的。变化快的部分的周期就是pitch。如果把这个功率普看作是时域信
号(事实上横轴是频率,纵轴是功率),再做FFT,那么这个功率普高频部分有一个
明显尖峰,其对应的就是pitch。
2)在时域上把波形图扩展开,然后手工计算浊音的最小周期,取倒数也是pitch。两种
方法计算结果一致
3)F1,是第一共振峰。回头看语谱图,变化缓慢的,但是有几条东西的能量特别大。从低频到高频,这几条能量大的东西分别是F1F2F3(有些浊音有F4)。这些能量大的位置与语谱图的包络有关。因此,依然跟上面的方法相同,把功率谱看作时域信号,做FFT,然后为了提出低频部分,做低通滤波(事实上是为了滤pitch);再反FFT,回到频域。这时看其语谱图,就可以看到这是带有3个尖峰(或者4个尖峰)的缓慢变化的信号。把尖峰找出来,就是F1F2F3了。
基于线性预测(LPC)的共振峰提取方法。一种有效的频谱包络估计方法是从线性预测分析角度推导出声道滤波器,根据这个声道滤波器找出共振峰。虽然线性预测法也有一定的缺点,如其频谱林灵敏度于人耳不想匹配。但对于许多应用来说,它仍然是一种行之有效的方法。线性预测共振峰通常有两种途径可供选择:一种途径是利用一种标准的寻找复根的程序计算预测误差滤波器的根,称为求根法;另一种途径是找出由预测其导出的频谱包络中的局部极大值,称为选峰法。
从线性预测导出的声道滤波器是频谱包络估计器的最新形式。在语音不含噪声时,线性预测提供了一个优良的声道模型。尽管线性预测法的频率林敏度和人耳不相匹配,但它仍是最易于实现的。
用线性预测可对语音信号进行反解卷(反卷积?):把激励分量归入预测残差中,得到预测系数ai,得到声音响应的模型H(z)
ε(n)=s(n)−∑i=1pais(n−i)H(z)=S(z)E(z)=G1−∑i=1Paiz−i=GA(z)
五、基音周期检测算法实现
5.1 基于自相关的基音周期检测程序% 名称
% spCorrelum - 信号的自相关系数
% 用法
% [r] = spCorrelum(x, fs, maxlag, show)
% 面述
% 获得信号的自相关系数
% 输入
% x N*1的向量用于容纳声音信号
% fs 采样频率
% [maxlag] 在一定滞后范围内,求相关序列,范围是[-maxlag:maxlag]。输出 r 的长度是2*maxlag+1。默认20ms
% 延时,即50Hz,这是人声的最小频率。
% 输出
% r 相关系数,长度2*maxlag+1。
% 使用
% xcorr.m (Signal Processing toolbox)
function [r] = spCorrelum(x, fs, maxlag, show)
%% 初始化
if ~exist('maxlag', 'var') || isempty(maxlag)
maxlag = fs/50; % F0 is greater than 50Hz => 20ms maxlag
end
if ~exist('show', 'var') || isempty(show)
show = 0;
end
%% 自相关
r = xcorr(x, maxlag, 'coeff');
if show
%% 画波形图
t=(0:length(x)-1)/fs; % 声音片段时间
subplot(2,1,1);
plot(t,x);
legend('Waveform');
xlabel('Time (s)');
ylabel('Amplitude');
xlim([t(1) t(end)]);
%% 画自相关
d=(-maxlag:maxlag)/fs;
subplot(2,1,2);
plot(d,r);
legend('Auto-correlation');
xlabel('Lag (s)');
ylabel('Correlation coef');
end
end% 名称 % spPitchCorr - Pitch Estimation via Auto-correlation Method % 用法 % [f0] = spPitchCorr(r, fs) % 面述 % 基于自相关的基音周期检测 % 输入 % r 自相关系数,长度(maxlag*2+1)x1 % fs 原始信号的采样频率 % OUTPUTS % f0 估计的基音 function [f0] = spPitchCorr(r, fs) % 搜2ms (=500Hz)到20ms (=50Hz)内的最大值 ms2=floor(fs/500); % 2ms ms20=floor(fs/50); % 20ms % 反应真实信号 r = r(floor(length(r)/2):end); [maxi,idx]=max(r(ms2:ms20)); f0 = fs/(ms2+idx-1); end
% 名称
% spPitchTrackCorr:基于自相关的基音周期检测
% 使用
% [F0, T, R] =
% spPitchTrackCorr(x, fs, frame_length, frame_overlap, maxlag, show)
% 面述
% 在时域跟踪 F0变化
% 输入
% x 大小Nx1.
% fs 采样率,单位Hz.
% [frame_length] 声音片段长度,默认30(ms)
% [frame_overlap] 声音片段重叠部分,默认重叠长度的一半。
% [maxlag] 求滞后区间[-maxlag:maxlag]. 默认20ms(Hz)延后,(最小人声).
% [show] 是否绘画,默认为0.
% 输出
% F0 1*k 包含基本频率,K 是声音片段数量。
% T 1*k,每个声音片段中间的值
% [R] M*K包含相关信息
function [F0, T, R] = spPitchTrackCorr(x, fs, frame_length, frame_overlap, maxlag, show)
%% 初始化
N = length(x);
if ~exist('frame_length', 'var') || isempty(frame_length)
frame_length = 30;
end
if ~exist('frame_overlap', 'var') || isempty(frame_overlap)
frame_overlap = 20;
end
if ~exist('maxlag', 'var')
maxlag = [];
end
if ~exist('show', 'var') || isempty(show)
show = 0;
end
nsample = round(frame_length * fs / 1000); % 转换 ms 到 point
noverlap = round(frame_overlap * fs / 1000); % 转换 ms 到 point
%% 基音监测
pos = 1; i = 1;
while (pos+nsample < N)
frame = x(pos:pos+nsample-1);
frame = frame - mean(frame); % 去除中值
R(:,i) = spCorrelum(frame, fs);
F0(i) = spPitchCorr(R(:,i), fs);
pos = pos + (nsample - noverlap);
i = i + 1;
end
T = (round(nsample/2):(nsample-noverlap):N-1-round(nsample/2))/fs;
if show
% 画出波形
subplot(2,1,1);
t = (0:N-1)/fs;
plot(t, x);
legend('Waveform');
xlabel('Time (s)');
ylabel('Amplitude');
xlim([t(1) t(end)]);
% 画出 F0跟踪
subplot(2,1,2);
plot(T,F0);
legend('pitch track');
xlabel('Time (s)');
ylabel('Frequency (Hz)');
xlim([t(1) t(end)]);
end
例子:
[x, fs] = wavread('pen.wav');
[F0, T, C] = spPitchTrackCepstrum(x, fs, 30, 20, 'hamming', 'plot');
上图就是我们所说的原始声波图,下面就是自相关系数图。
最后得到的基音频率是341.8605Hz。
5.2 基于倒谱的基音周期监测的程序
% 名称
% spCepstrum
% 用法
% [c, y] = spCepstrum(x, fs, window, show)
% 面述
% 一个信号的倒谱
% 输入
% x N*1的向量用于容纳声音信号
% fs 采样频率
% [window] (字符型)窗型'rectwin'(默认)或者'hamming'
% [show] 是否画出来,默认 false
% OUTPUTS
% c N*1的倒谱信息。
% [y] N*1的傅里叶响应。
function [c, y] = spCepstrum(x, fs, window, show)
%% 初始化
N = length(x);
x = x(:); % 确保一下是纵向量
if ~exist('show', 'var') || isempty(show)
show = 0;
end
if ~exist('window', 'var') || isempty(window)
window = 'rectwin';
end
if ischar(window);
window = eval(sprintf('%s(N)', window)); % hamming(N)
end
%% 窗形信号的傅里叶变换
x = x(:) .* window(:);
y = fft(x, N);
%% 倒谱是log谱的 IDFT(或者 DFT)
c = ifft(log(abs(y)+eps));
if show
ms1=fs/1000; % 1ms. 声音的最大 FX(1000Hz)
ms20=fs/50; % 20ms. 50Hzs声音最小 FX(50Hz)
%% 画出波形
t=(0:N-1)/fs; % 采样次数
subplot(2,1,1);
plot(t,x);
legend('Waveform');
xlabel('Time (s)');
ylabel('Amplitude');
%% 画出1ms (=1000Hz)到20ms (=50Hz)的倒谱
%% DC 部分 c(0) 太大
q=(ms1:ms20)/fs;
subplot(2,1,2);
plot(q,abs(c(ms1:ms20)));
legend('Cepstrum');
xlabel('Quefrency (s) 1ms (1000Hz) to 20ms (50Hz)');
ylabel('Amplitude');
end
end% 名称 % spPitchCepstrum - Pitch Estimation via Cepstral Method % 用法 % [f0] = spPitchCepstrum(c, fs) % 面述 % 基于倒谱的基音周期检测 % 输入 % r 自相关系数,长度(maxlag*2+1)x1 % fs 原始信号的采样频率 % OUTPUTS % f0 估计的基音
% 名称
% spPitchTrackCepstrum: Pitch Tracking via the Cepstral Method
% 使用
% [F0, T, C] =
% spPitchTrackCepstrum(x, fs, frame_length, frame_overlap, window, show)
% 描述
% 在时域跟踪 F0变化
% 输入
% x 大小Nx1.
% fs 采样率,单位Hz.
% [frame_length] 声音片段长度,默认30(ms)
% [frame_overlap] 声音片段重叠部分,默认重叠长度的一半。
% [window] (字符型)窗型'rectwin'(默认)或者'hamming'
% [show] 是否画出来,默认 false
% 输出
% F0 1*k 包含基本频率,K 是声音片段数量。
% T 1*k,每个声音片段中间的值
% [C] M*K 包含cepstrogram
function [F0, T, C] = spPitchTrackCepstrum(x, fs, frame_length, frame_overlap, window, show)
%% 初始化
N = length(x);
if ~exist('frame_length', 'var') || isempty(frame_length)
frame_length = 30;
end
if ~exist('frame_overlap', 'var') || isempty(frame_overlap)
frame_overlap = 20;
end
if ~exist('window', 'var') || isempty(window)
window = 'hamming';
end
if ~exist('show', 'var') || isempty(show)
show = 0;
end
nsample = round(frame_length * fs / 1000);
noverlap = round(frame_overlap * fs / 1000);
if ischar(window)
window = eval(sprintf('%s(nsample)', window)); % e.g., hamming(nfft)
end
%% 基音监测
pos = 1; i = 1;
while (pos+nsample < N)
frame = x(pos:pos+nsample-1);
C(:,i) = spCepstrum(frame, fs, window);
F0(i) = spPitchCepstrum(C(:,i), fs);
pos = pos + (nsample - noverlap);
i = i + 1;
end
T = (round(nsample/2):(nsample-noverlap):N-1-round(nsample/2))/fs;
if show
% 画出波形
subplot(2,1,1);
t = (0:N-1)/fs;
plot(t, x);
legend('Waveform');
xlabel('Time (s)');
ylabel('Amplitude');
xlim([t(1) t(end)]);
% 画出 F0跟踪
subplot(2,1,2);
plot(T,F0);
legend('pitch track');
xlabel('Time (s)');
ylabel('Frequency (Hz)');
xlim([t(1) t(end)]);
end[x, fs] = wavread('pen1.wav');
[F0, T, R] = spPitchTrackCorr(x, fs, 30, 20, [], 'plot');
5.3 基于线性预测编码的共振峰检测实现
% 名称
% spLpc - 线性预测,维纳滤波的一步有限观测
% 用法
% [a P e] = spLpc(x, fs, ncoef, show)
% 描述
% LPC 系数 (AR model)
% 输入
% x Nx1信号
% fs 采样频率
% [ncoef] 系数数量,默认ncoef = 2 + fs / 1000;(人声的经验值)
% 输出
% a ncoefx1LPC系数
% P 预测误差的方差
% e N*1,残差信号
function [a P e] = spLpc(x, fs, ncoef)
if ~exist('ncoef', 'var') || isempty(ncoef)
ncoef = 2 + round(fs / 1000); %
end
[a P] = lpc(x, ncoef);
if nargout > 2,
est_x = filter([0 -a(2:end)],1,x); %估计信号
e = x - est_x; % 残余信号
end
end% 名称 % spFormantsLpc - 通过 LPC 进行共振峰估计 % 用法 % [F] = spFormantsLpc(a, fs) % 描述 % 共振峰频率估计 % 输入 % a 大小 ncoefx1*1,原始信号的 LPC 系数。 % fs 原始信号采样频率 % 输出 % F ncoefx1,共振峰频率 function [F] = spFormantsLpc(a, fs) r = roots(a); r = r(imag(r)>0.01); F = sort(atan2(imag(r),real(r))*fs/(2*pi)); end
% 名称
% spFormantsTrackLpc:基于 LPC 的共振峰跟踪
% 用法
% [F, T] = spFormantsTrackLpc(x, fs, ncoef,
% frame_length, frame_overlap, window, show)
% 描述
% 基于 LPC 的共振峰跟踪
% 输入
% x Nx1信号
% fs 采样频率
% [ncoef] 系数数量,默认ncoef = 2 + fs / 1000;(人声的经验值)
% [frame_length] 声音片段长度,默认30(ms)
% [frame_overlap] 声音片段重叠部分,默认重叠长度的一半。
% [window] (字符型)窗型'rectwin'(默认)或者'hamming'
% [show] 是否画出来,默认 false
% 输出
% F 共振峰 (fm = F(find(T == 0.01))
% T 共振峰次数
function [F, T] = spFormantsTrackLpc(x, fs, ncoef, frame_length, frame_overlap, window, show)
%% Initialization
N = length(x);
if ~exist('frame_length', 'var') || isempty(frame_length)
frame_length = 30;
end
if ~exist('frame_overlap', 'var') || isempty(frame_overlap)
frame_overlap = 20;
end
if ~exist('window', 'var') || isempty(window)
window = 'hamming';
end
if ~exist('show', 'var') || isempty(show)
show = 0;
end
if ~exist('ncoef', 'var')
ncoef = [];
end
nsample = round(frame_length * fs / 1000); %
noverlap = round(frame_overlap * fs / 1000); % ms 转为点
window = eval(sprintf('%s(nsample)', window)); % e.g., hamming(nfft)
pos = 1; t = 1;
F = []; % 共振峰
T = []; % 每个 frame 内的次数
mid = round(nsample/2);
while (pos+nsample <= N)
frame = x(pos:pos+nsample-1);
frame = frame - mean(frame);
a = spLpc(frame, fs, ncoef);
fm = spFormantsLpc(a, fs);
for i=1:length(fm)
F = [F fm(i)]; % 每个 frame(片段)的共振峰数量不同
T = [T (pos+mid)/fs];
end
pos = pos + (nsample - noverlap);
t = t + 1;
end
if show
% 画出波形
t=(0:N-1)/fs;
subplot(2,1,1);
plot(t,x);
legend('Waveform');
xlabel('Time (s)');
ylabel('Amplitude');
xlim([t(1) t(end)]);
%画出共振峰轨迹
subplot(2,1,2);
plot(T, F, '.');
hold off;
legend('Formants');
xlabel('Time (s)');
ylabel('Frequency (Hz)');
xlim([t(1) t(end)]);
end[x, fs] = wavread('pen1.wav');
[F, T] = spFormantsTrackLpc(x, fs, [], 30, 20, 'hamming', 'plot');%Formants Detection via LPC Method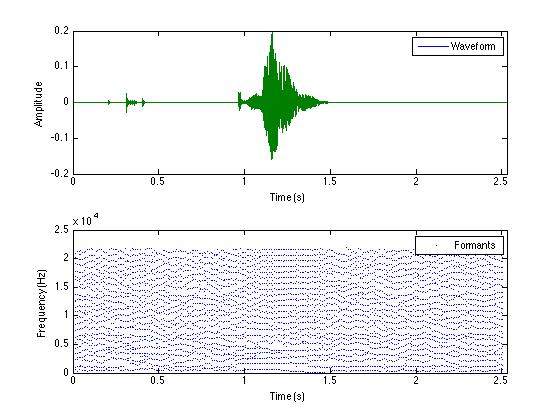
六、参考
1 http://blog.csdn.net/zouxy09/article/details/91418752 http://sound.eti.pg.gda.pl/student/eim/synteza/leszczyna/index_ang.htm
3 http://note.sonots.com/SciSoftware/Pitch.html

相关文章推荐
- 【原创汉化】Wavosaur 1.0.5.0 汉化版
- Python将图片写到音频频谱
- 《视频直播技术详解》系列之二:处理
- iOS音频技术的研究-音频格式
- ubuntu 16.10 下安装 sonic visualizer
- 利用python-librosa库进行音频处理
- iOS 如何对音频、视频合成,配音、卡拉OK技术
- 【脚本语言系列】关于Python音频处理WMPlayerOCX,你需要知道的事情
- 【脚本语言系列】关于Python音频处理DirectSound, 你需要知道的事
- 电吉他效果器音频处理(1)——失真效果器、超载失真效果器、移相效果器、弗兰格效果器
- ffmpeg使用笔记: 安装--命令--Java封装
- ios开发AudioUnit的录制与播放功能,双工模式下的回音抑制以及降噪
- ios开发之使用AudioQueue进行音频的播放
- 使用SoundTouch为音频文件添加特殊效果
- c++&c#实现拼接wav和mp3文件
- 写给小白的音频认识基础
- Python3+将2声道音频,分拆成1声道
- 信托购买高搜索产品容易推10元[奥运]门槛
- 边走边学Nodejs (基础入门篇)