Stanford机器学习 -- 对Linear Regression 的补充
2015-06-30 19:28
267 查看
Linear Regression的步骤
初始化 parameters θi (i = 0 ,1,……,n)选择α(学校速率,可以尝试不同的值找到最合适的)
1.设计Cost Function
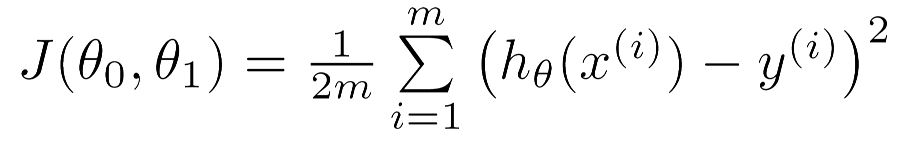
2.对代价函数求导数
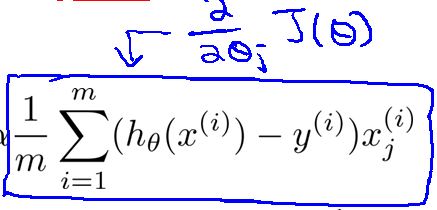
循环(最终循环结束的条件):
For循环(对每个参数进行更新):
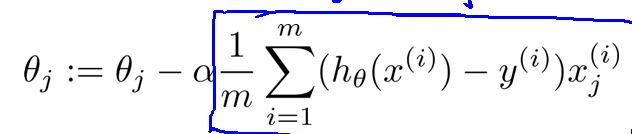
循环结束的条件:指定一个最小更新误差,每次循环完成后计算误差函数J更新后和更新前的误差,如果小于最小更新误差停止循环。也可以自己设置一个足够大的值。
vertorization(向量化)
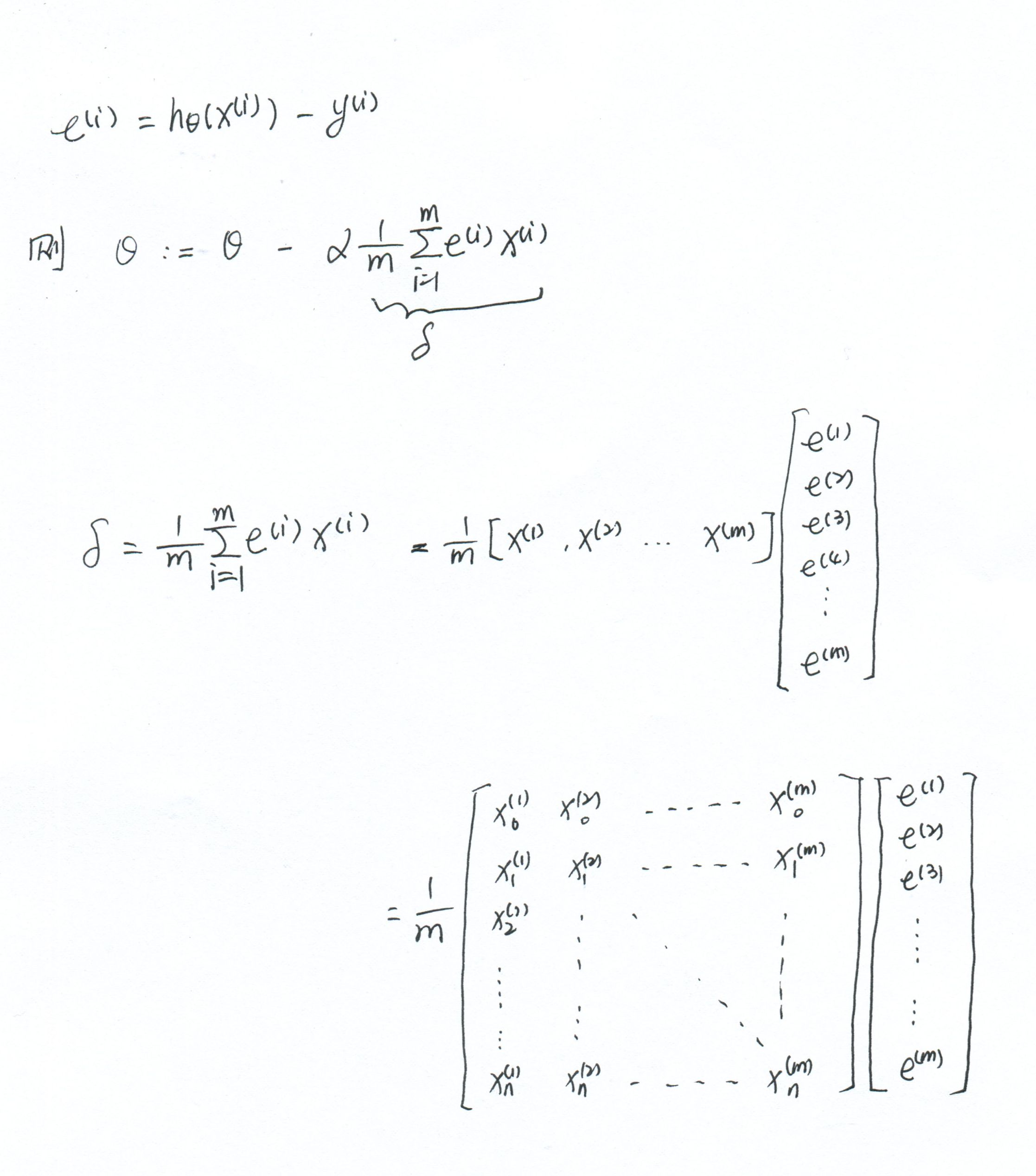
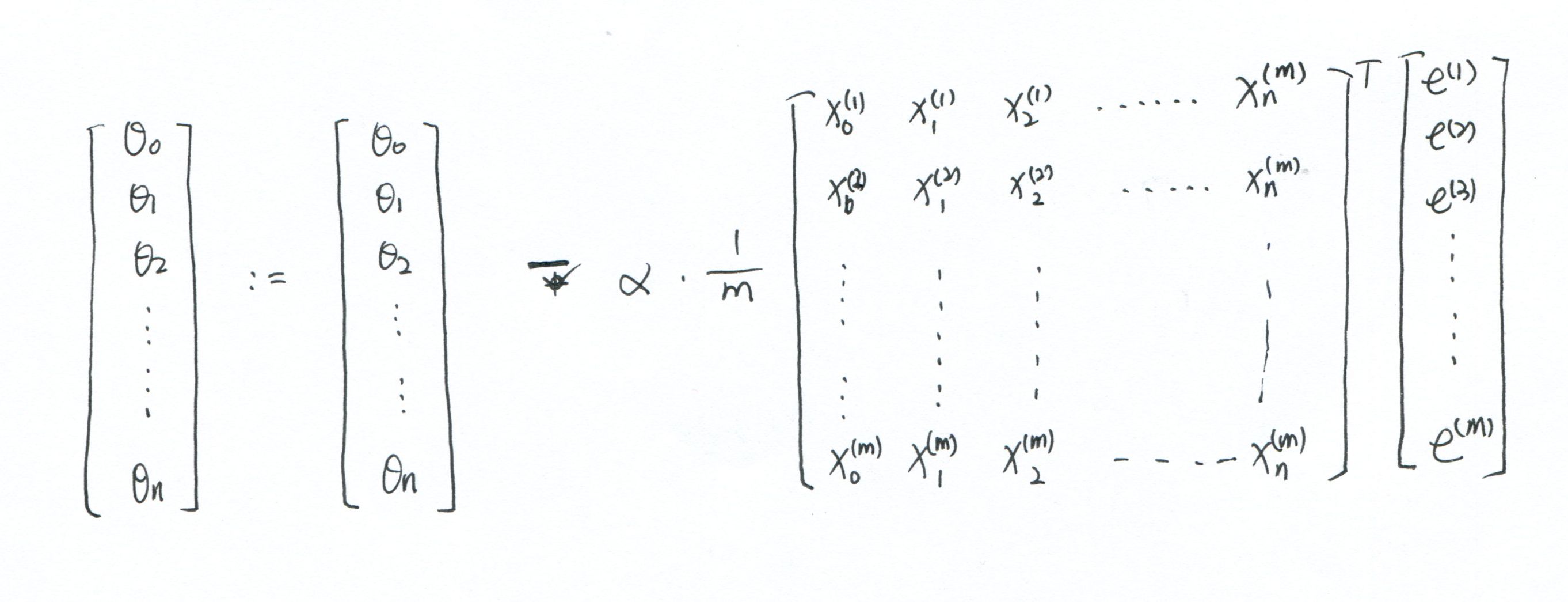
这是按照Andrew Ng的思路写成的,只是为了编写程序方便,具体用了什么数学知识,也不太懂。
实现代码
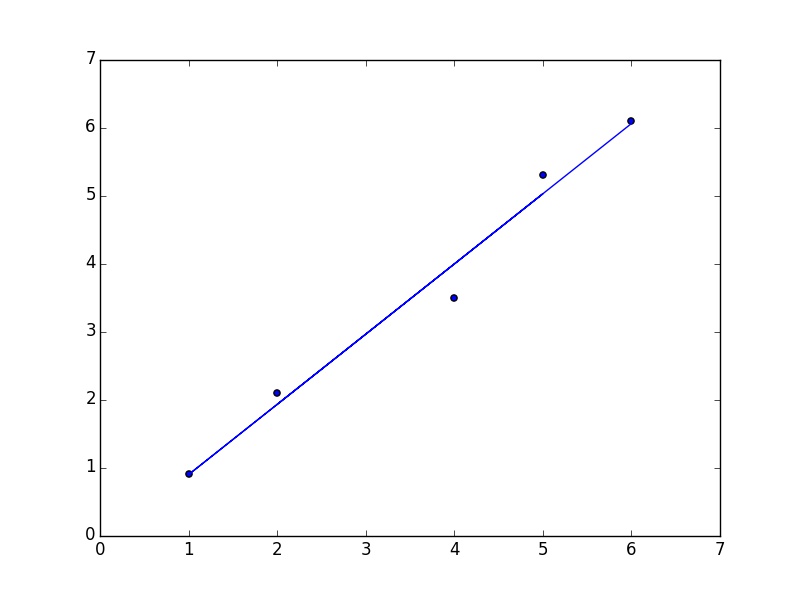
.1 python1.第一种实现用梯度下降法:
from numpy import * import matplotlib.pyplot as plt import numpy as np def Gd_algorithm( alpha ): dataMat = array([[1,2],[1,4],[1,5],[1,1],[1,6]]) labelMat = array([2.1,3.5,5.3,0.9,6.1]) weights = ones((shape(dataMat)[1] , 1)) err_inf = inf flag = True while flag : flag = False error = dot(dataMat , weights).T[0] - labelMat.T #print error err_sum_new = sum(error ** 2) if err_sum_new < err_inf: err_inf = err_sum_new flag = True else: break for i in range(shape(weights)[0]): weights[i] = weights[i] - alpha * (1.0/shape(dataMat)[0]) * dot(error , dataMat.T[i]) print weights plt.scatter(dataMat.T[1] , labelMat) x = dataMat.T[1] y = weights[0] + weights[1]* x plt.plot(x,y) plt.show()

2用向量化代码编写
from numpy import * import matplotlib.pyplot as plt import numpy as np def Gd_algorithm( alpha ): dataMat = array([[1,2],[1,4],[1,5],[1,1],[1,6]]) labelMat = array([[2.1],[3.5],[5.3],[0.9],[6.1]]) weights = ones((shape(dataMat)[1] , 1)) err_inf = inf flag = True while flag : flag = False error = dot(dataMat , weights) - labelMat err_sum_new = sum(array(error) ** 2) if err_sum_new < err_inf: err_inf = err_sum_new flag = True else: break weights = weights - alpha * (1.0/shape(dataMat)[0]) * dot(dataMat.T , error) print weights plt.scatter(dataMat.T[1] , labelMat) x = dataMat.T[1] y = weights.tolist()[0][0] + weights.tolist()[1][0]* x plt.plot(x,y) plt.show()
运行结果:
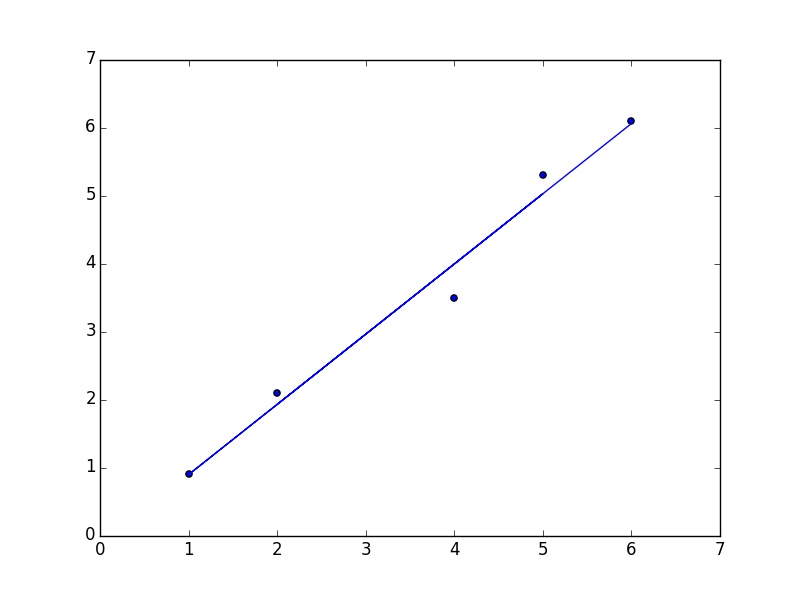

可以试一下不同的alpha用的时间不太一样。
3用公式计算权重
from numpy import * import matplotlib.pyplot as plt import numpy as np def algorithm(): dataMat = array([[1,2],[1,4],[1,5],[1,1],[1,6]]) labelMat = array([[2.1],[3.5],[5.3],[0.9],[6.1]]) weights = ones((shape(dataMat)[1] , 1)) weights = dot(dot(linalg.inv(dot(dataMat.T , dataMat)) , dataMat.T) , labelMat) print weights plt.scatter(dataMat.T[1] , labelMat) x = dataMat.T[1] y = weights.tolist()[0][0] + weights.tolist()[1][0]* x plt.plot(x,y) plt.show()
优点:简单,一行代码搞定
缺点:当数据集样本很大时,计算会变慢,而且,有时候linalg.inv(dataMat.T,dataMat) 不一定能求出来。
这个运行的结果和上面差不多。
关于梯度下降和梯度上升的说明
下面是在有些书中用到的梯度上升法求导数的最优解。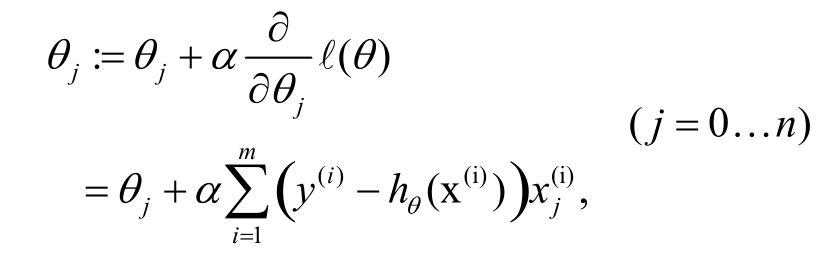
这是在Andrew Ng用的梯度下降法求最优解。
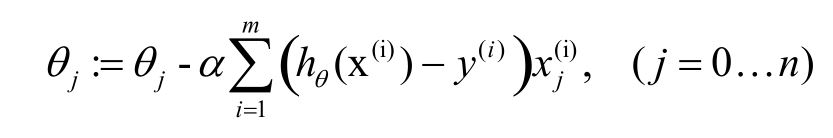
可以看到这两中方法其实是一个公式的两种不同叫法,他们背后的数学含其实是一样的。在使用时注意就OK了,数学含义以后明白了再补。
代码写的很烂,请各位大神不吝赐教!!

相关文章推荐
- model转字典
- No sources that matches the given name (at 'layout_toLeftOf' with value '@id/
- Java反射应用案例
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
- 回溯法之求n个集合的幂集
- Intel MKL 在VS中的配置与安装笔记
- 写一个算法实现在一个整数数组中,找出第二大的那个数字。
- 如何查找最新文献
- Java文件选择对话框(文件选择器JFileChooser)的使用:以一个文件加密器为例
- IT架构之IT架构标准——思维导图
- javascript基础
- iOS7新特性 ViewController转场切换(三) 自定义视图控制器容器的切换---非交互式
- iOS 阶段学习第11天笔记(OC基础知识)
- 如何做好PPT?
- 写一个通用的事件侦听器函数(兼容多浏览器)
- git查看历史与乱码解决
- android 完美退出应用程序。
- 理解SVG的viewport,viewBox,preserveAspectRatio
- Freemarker-2.3.22 Demo - No04_条件判断
- TexturePacker使用